앞 게시글에서 semi-supervised learning의 컨셉과 사용되는 방법 몇가지에 대해 알아보았었다.
semi-supervised learning의 Auxiliary Objective 함수를 1. Consistency Regularization 방법과 2. Entropy Minimization 방법으로 나누어 소개 했는데,
Entropy Minimization의 대표적인 Pseudo Labeling [Lee, 2013] 방법과
Consistency Regularization 의 대표적인 방법인 Π-Model [Laine and Aila, 2017], 그리고 이를 약간 개선한 Temporal Ensembling 방법이 있었다.
Temporal Ensembling 모델에서는 scalable 하지 않다는 문제점이 있었는데 이를 개선하기 위한 방법으로 Mean Teacher 방법을 이어서 소개한다.
방법4. Mean Teacher [Tarvainen and Valpola, 2017]
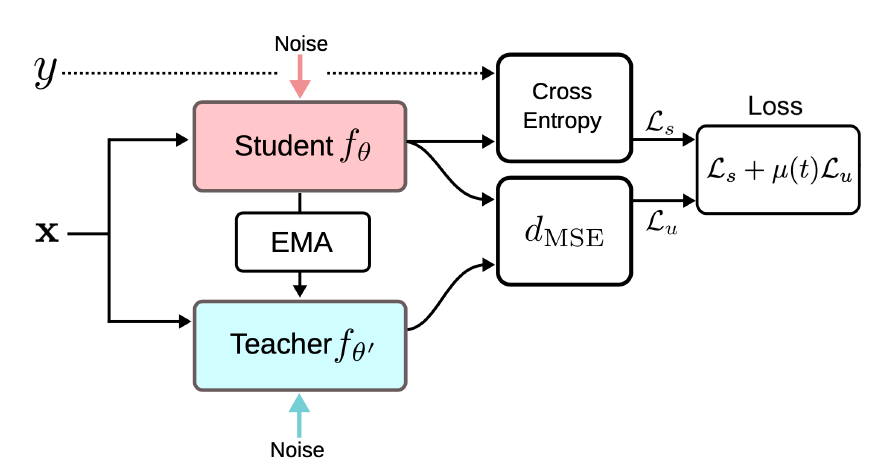
mean teacher
mean teacher는 knowledge distillation 쪽에서도 많이 쓰이는 개념
scalable 문제를 해결하기 위해 Mean Teacher 라는 개념을 가져왔다.
현재 내가 계산한 모델 파라미터 가 있고 현재까지 temporal하게 누적해온 가 있는데 이것을 moving average로 가져온다.
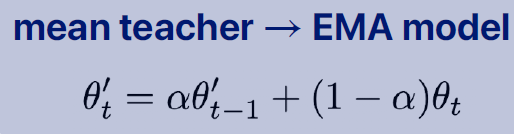
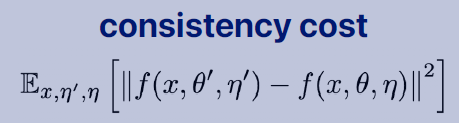
(비교)
Temporal Ensembling 방법에서는 prediction 를 sample 개수 N과 class개수 c로 (Nxc)로 나타냈어야 했는데 지금은 parameter M개 하나만 저장하면 된다.
즉 ensemble을 하는건데 prediction space 에서 하는 것이 아니라 model parameter space 에서 하는 것이다.
- teacher 는 moving average로 앙상블 형태의 좀 더 좋은 모델 (multiple model) => 정확도가 높을 것이라 기대
- student는 누적이 아닌 현재 시점의 파라미터(single model)
이 student와 teacher 모델이 비슷하게 되도록 학습을 하는 것
결과
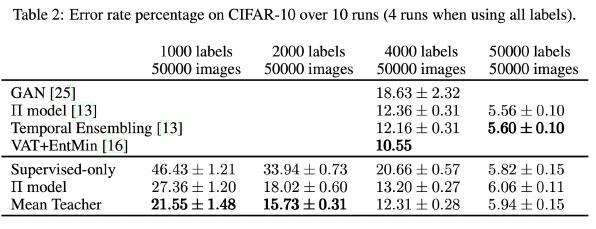
mean teacher를 사용했을 때 성능이 좀 더 개선이 되었다.
방법5. Virtual Adversarial Training [Miyota et al., 2017]
semi-supervised learning에서 꽤나 획기적인 논문
입력 데이터에 간단한 변형을 주는 것이 아니라 adversarial한 변형을 적용한 방법이다. adversarial을 쉽게 설명하자면 loss의 값을 최대한 해치는 방향으로 변형을 하는 것이다.
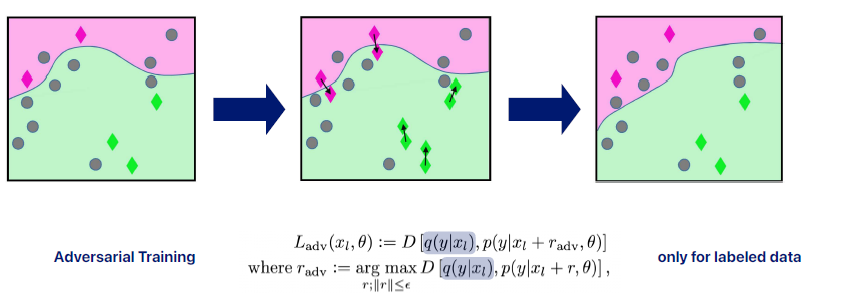
-
loss의 값을 최대한 해치는 방향으로 변형을 하는 것이 무엇인가?
일반적으로 loss를 minimize하기 위해 구한다. 그러나 여기서는 loss를 늘리는 쪽을 본다.
loss를 늘리는 쪽이란 결국 noise를 섞어서 prediction을 방해하는 방향을 찾겠다라는 것인데, 여기서 input 관점에서의 방향 찾는다. sign을 이용해 gradient의 방향만 활용한다.
consistency regularization 관점에서 prediction이 망가지는 방향으로 가더라도 Ground Truth target이랑 같게 하도록 학습한다.
그것을 가지고 minimize하는것이 adversarial training! -
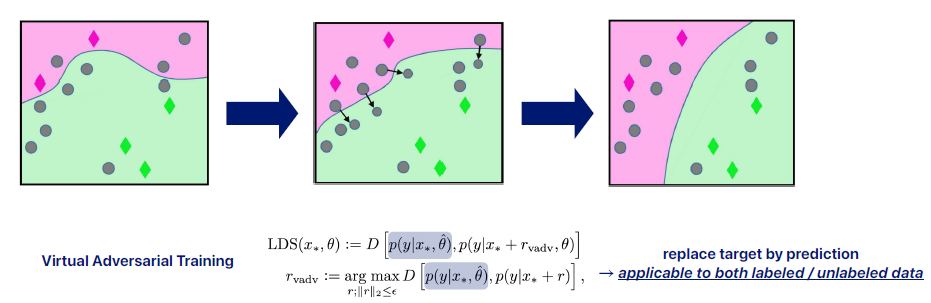
virtual이라는 이름이 붙은 이유?
일반적으로 adversarial training은 labeled 데이터를 가지고 하던건데 그것을 unlabeled 데이터까지 확장해서 virtual adversarial training 이라고 불린다.
방법 6. MixMatch [Berthelot et al., 2019]
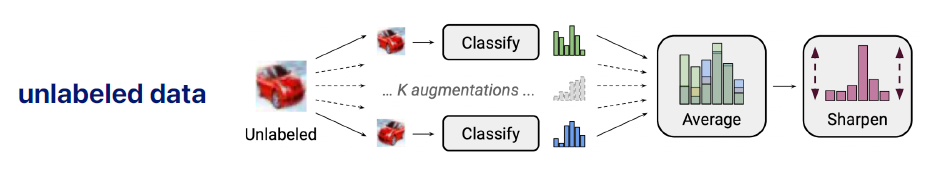
-
model ensembling (test time augmentation 과 유사)
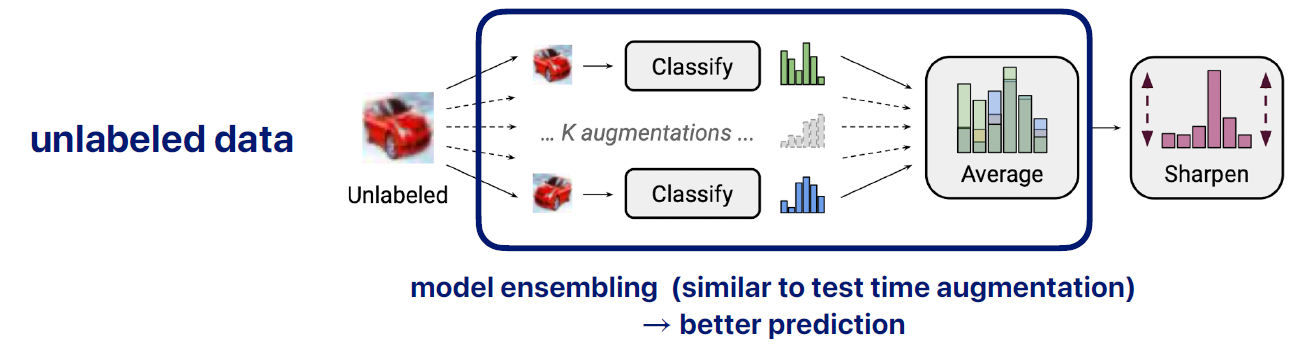
unlabeled data 가 있으면 k번의 augmentation을 해줌
각각의 다른 k개의 prediction 있음 -> 이것을 average 해줌
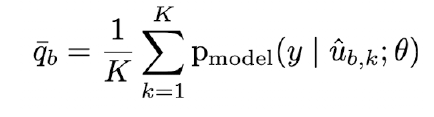
이렇게 하면 좀더 나은 prediction 값을 가짐 -
(soft) pseudo-labeling → entropy minimization
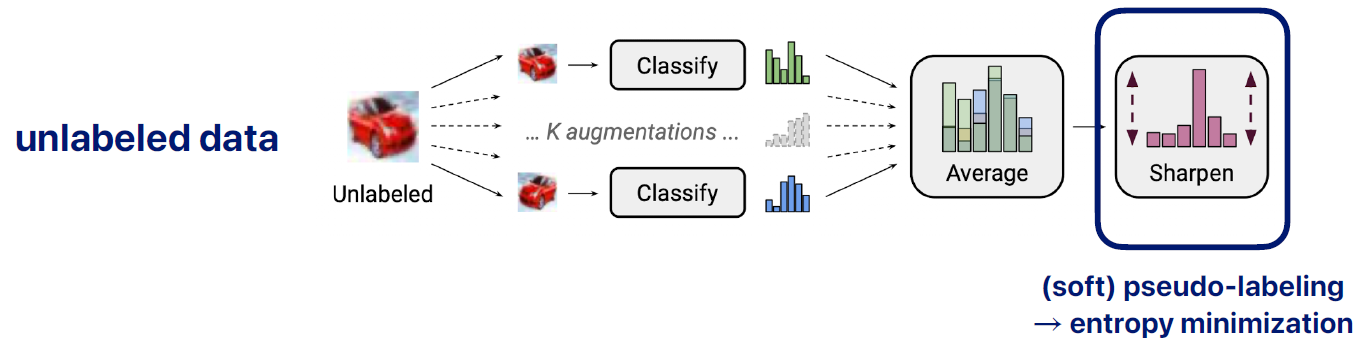
앙상블 값을 가지고 pseudo labeling을 하면 더 좋은 값을 가지지 않겠는가 하는 것
여기서는 soft하게 접근해서 완전한 hard(one hot 확률)는 아니고 hard에 가까운 확률이 나온다.
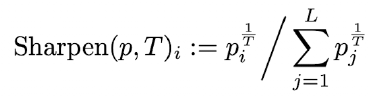
-
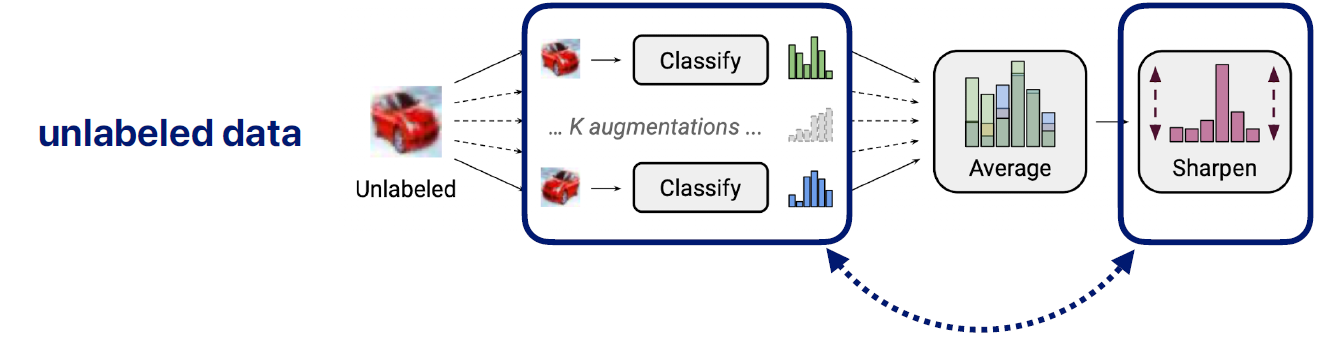
consistency regularization (squared loss)
k개의 augmented prediction 값 과 이를 대표하는 pseudo label 만듬
그 다음 psuedo label을 k개의 prediction이랑 같아지도록 학습함으로써 좀 더 학습이 잘 되도록 하는 방향
mixup
Mixmatch에 mixup이라는 컨셉을 더 붙여줌
label이 있는 데이터와 label이 없는 데이터를 mix 하는 과정
mixup은 "smoothness"랑도 연결됨
decision boundary를 좀더 smooth 하게 만듬
- pseudo code

- loss
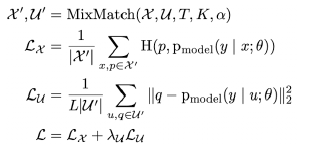
loss계산할때,
label 데이터는 cross entropy 계산
unlabeled 데이터는 difference를 minimization 해줌
mixup 은 1. Consistency Regularization 방법과 2. Entropy Minimization 방법 같이 들어가는 것
결과
파란색 점선으로 나타낸 것이 supervised learning의 결과이고 이를 다른 semi-supervised 방법들과 비교해보면 다음과 같다.
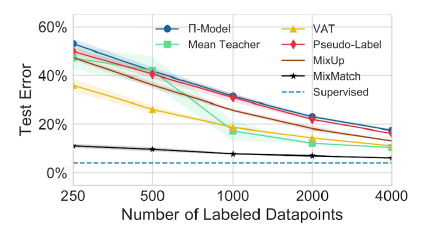
mix match는 label 데이터가 많이 있으나 적게 있으나 error 적게 나온다.
mix match가 기존의 것을 잘 조합하여 성능을 개선했다라고 볼 수 있다.
이후에 나온 다른 Semi-Supervised Learning 방법들
대부분 여러가지를 섞은 것들이 많이 나오고 있다.
• ReMixMatch [Berthelot et al., 2019]
• Interpolation Consistency Training [Verma et al., 2019]
• Self-Supervised Semi-Supervised Learning [Zhai et al., 2019]
• Unsupervised Data Augmentation [Xie et al., 2020]
• FixMatch [Sohn et al., 2020]
다양한 모델들이 나오고 있지만 결국 컨셉적으로는 1. Consistency Regularization 방법과 2. Entropy Minimization 방법을 잘 조합해서
단점들을 보완하는 방식으로 접근한 것이라고 볼 수 있다.
(Self-supervised learning이 나오면서 semi-supervised learning이 많이 죽기는 했다. 그래도 여전히 Consistency Regularization이라던지 Entropy Minimization 접근 방법들은 많이 쓰이고 있다.)
