
◇ YOLOv1 ◇

Yolo V1 은 입력 이미지를 S X S Grid로 나누고 각 Grid의 Cell이 하나의 Object에 대한 Detection 수행
- 각 Grid Cell 이 2개의 Bounding Box 후보를 기반으 로 Object의 Bounding Box 를 예측
- 7X7 Grid = 49개
- 각 그리드 셀이 2개의 바운딩 박스를 만든다
- 후보를 기반으로 해서 바운딩 박스를 예측한다.
- 49x2 = 98 개가 만들어 진다.
◇ YOLO-V1 네트웍 및 Prediction 값 ◇
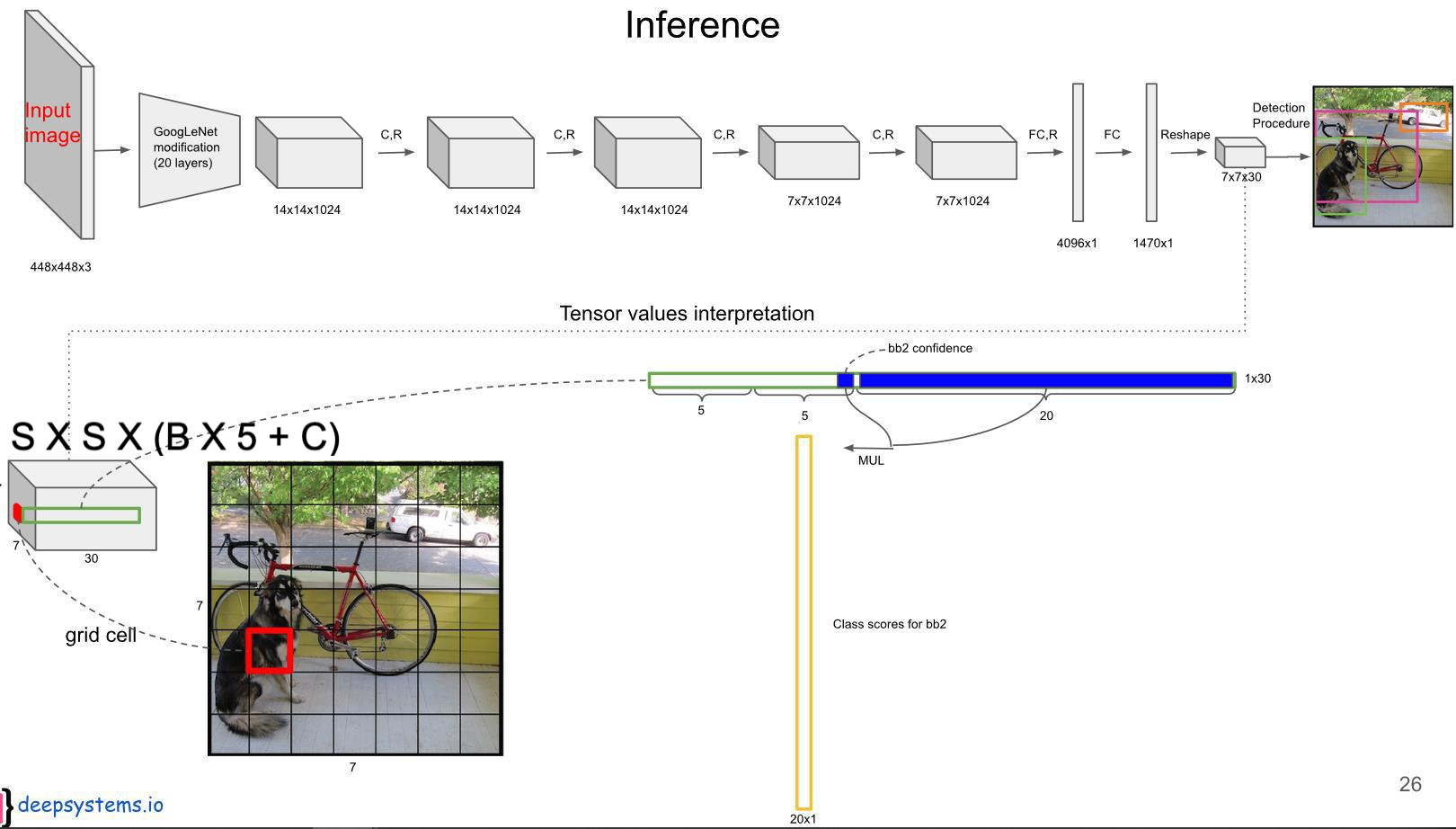
(자전거 이미지)각 Grid Cell 별로 아래를 계산
1st : 2개의 Bounding Box 후보의 좌표와 해당 Box별 Confidence Score
• x, y, w, h : 정규화된 BBox의 중심 좌표와 너비/높이
• Confidence Score = 오브젝트일 확률 * IOU 값
2nd : 클래스 확률. Pascal VOC 기준 20개 클래스의 확률
◇ YOLO-V1 Loss ◇
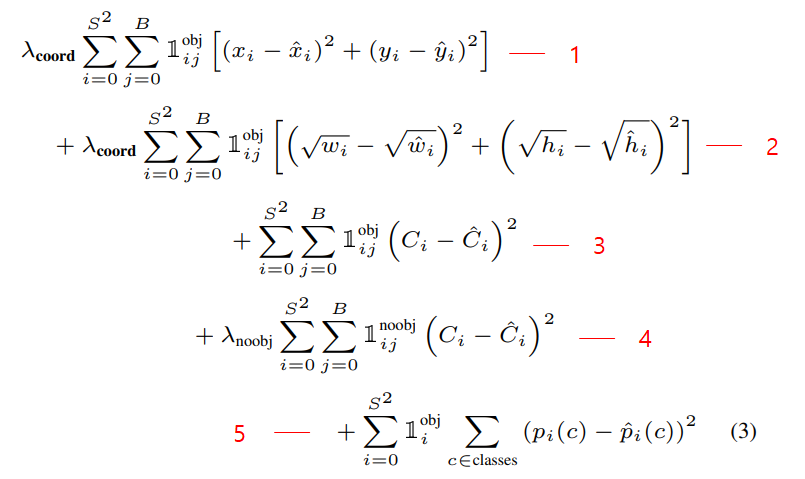
- YOLO v1은 위와같은 Multi Loss를 사용
- CrossEntropy가 아닌 SSE(Sum Square Error)를 사용
1 - Localization loss : x, y값을 regression하는 SSE loss 예측 좌표 x, y 값과 Ground Truth 좌표 x, y값의 오차 제곱을 기반
모든 Cell의 2개의 Bbox(98개 Bbox) 중에 예측 Bbox를 책임지는 Bbox 만 Loss 계산는 98개의 Bbox 중 오브젝트 예측을 책임지는 Bbox만 1
나머지는
2 - Localization loss : width, height값은 regression하는 SSE loss
3 - Confidence loss :
object가 있는 곳의 confidence SSE loss
4 - Confidence loss : object가 없는 곳의 confidence SSE loss
5 - Classification loss : object가 있는 곳의 각 class별 SSE loss (각 셀당1개의 class probability가 나오므로 ij가 아닌 i뿐)
- 참고로 loss를 구하기 전에 미리 ground truth쪽 confidence와 해당 클래스의 인덱스에 1을 할당해준다.
