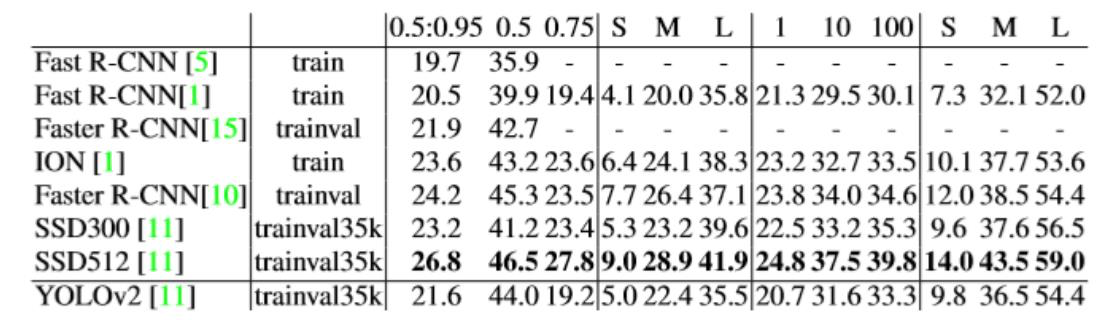
YOLO v1의 원리(논문)
2-stage detector인 RCNN과 YOLO 모델은 아래와 같이 기본 가정이 차이
- RCNN 계열의 가정 :
"물체가 존재할 것 같은 곳을 backbone network로 표현할 수 있다." → region proposal network - YOLO v1의 가정 :
"이미지 내의 작은 영역을 나누면 그곳에 물체가 있을 수 있다." → grid 내에 물체가 존재YOLO v1에서 grid는 고정되고, 각 grid 안에 물체가 있을 확률이 중요

Confidence Score :bbox가 사물(object)을 포함하는지를 모델이 확신 지표
- box가 그 사물을 얼마나 정확히 예측하는지를 보여주는 점수
각 bbox는 x, y, w, h, confidence, 총 5개의 예측- (x, y) 좌표는 bbox의 중심 좌표이고 w와 h는 너비와 높이
- 각 grid cell은 C개의 조건부 class 확률 P(Class i∣Object)도 예측
이 확률은 grid cell이 사물을 포함할 때를 조건으로 하는 확률- bounding box의 개수와 상관 없이 각 grid cell의 확률만 예측
- YOLO의 예측값은 S x S x (B * 5 + C) 크기의 텐서로 출력
Q. 1개의 7x7 grid 당 2개의 bounidng box(BBox) 와 20개 클래스를 예측하는 YOLO 를 만들고 싶은 경우, output tensor의 크기와 이를 flatten했을 때의 크기는?
output tensor의 크기는 7 x 7 x (5 x 2 + 20)이며, 이를 flatten하면 1470
동일한 물체를 잡는 bbox가 많아진다는 문제 발생
학습이 잘된 경우는 해당 grid들이 모두 비슷한 크기로 자전거의 bbox를 잡습니다.
NMS(Non-Maximum Suppression)와 같은 기법을 이용
비-최대 억제라고도 불리는 NMS 기법은 object detector가 예측한 bounding box 중 정확한 bounding box를 선택하는 기법
◇ YOLOv1 Detection ◇ - NMS
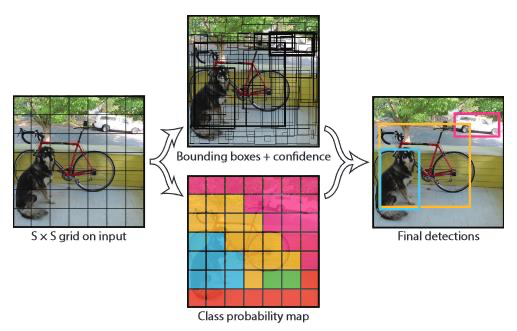
◇ NMS(Non Max Suppression)으로 최종 Bbox 예측 ◇

◇ 개별 Class 별 NMS 수행 ◇
- 특정 Confidence 값 이하는 모두 제거
- 가장 높은 Confidence값을 가진 순으로 Bbox 정렬
- 가장 높은 Confidence를 가진 Bbox와 IOU와 겹치는 부분이 IOU Threshold 보다 큰 Bbox는 모두 제거
- 남아 있는 Bbox에 대해 3번 Step을 반복
- Object Confidence와 IOU Threshold로 Filtering 조절

- object detection에서 기존에 사용되면 R-CNN 계열 방법은 검출속도 느림
(그 중 빠르다고 여겨지던 Faster R-CNN도 YOLO보다는 속도가 느리다)- Faster R-CNN은 RPN(Region Proposal Network) 후보군을 뽑고 localization와 classification을 수행(RPN에서 300개 영역을 제안하는데, objectness의 숫자가 많을수록 느려진다.)
반면 YOLO는 이미지를 S x S개의 grid로 나누고, 한 개의 grid당 bbox의 좌표와 confidence score만 예측하므로 R-CNN 계열 방법보다 훨씬 빠른 속도를 보여줍니다. 그런 이유로 YOLO는 최초의 real-time object detector로 여겨집니다.
YOLO의 목표
grid에 포함되는 물체를 잘 잡아내는 것
즉 grid cell에 속하는 물체를 검출할 책임이 있는 거죠.
- 1개 grid에 귀속된 bbox 정보 (x, y, w, h)의 학습 목표는 bbox의 ground truth와 최대한 동일하도록 학습되는 것입니다.
- 학습 목표가 제대로 이루어졌는지를 확인하려면 객체 인식 모델의 성능 평가 도구인 IoU(Intersection over Union)를 사용
◇ YOLOv1 inference 구현 ◇
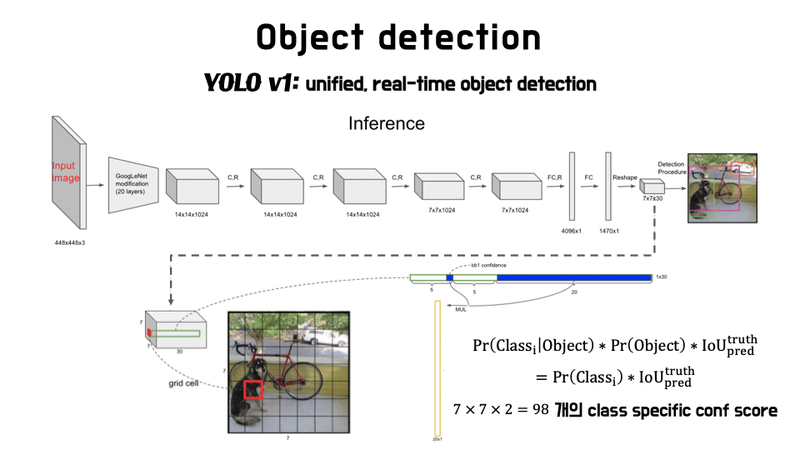
조건부 class 확률 는 마지막 layer에서 사용
output tensor의 크기 7 x 7 x 30에서 7 x 7은 49개의 grid cell이고,
30은 5(x, y, w, h, confidence score) 2 + 20(조건부 class 확률의 개수)입니다.
위의 그림에서 빨간색 정사각형이 7 x 7=49인 grid cell이고,
초록색 직사각형은 1 x 30의 크기를 가지죠.
여기서 30이 바로 위에서 언급한 $30(5 2 +20)$입니다.
테스트할 때, 조건부 확률 를 각 box의 과 곱해 - 를 얻을 수 있습니다. 각 score는 box 안에 나타나는 클래스의 확률과 예측된 box가 사물에 얼마나 잘 맞는지(fit)를 보여줍니다.
각각의 bounding box의 confidence score와 각각의 조건부 class 확률을 곱하면 각 bounding box마다
class-specific confidence score를 얻을 수 있고,
그 개수는 개입니다.
이 98개의 class-specific confidence score에 대해 20개의 class를 기준으로 NMS를 하여 object에 대한 class와 bounding box location을 결정
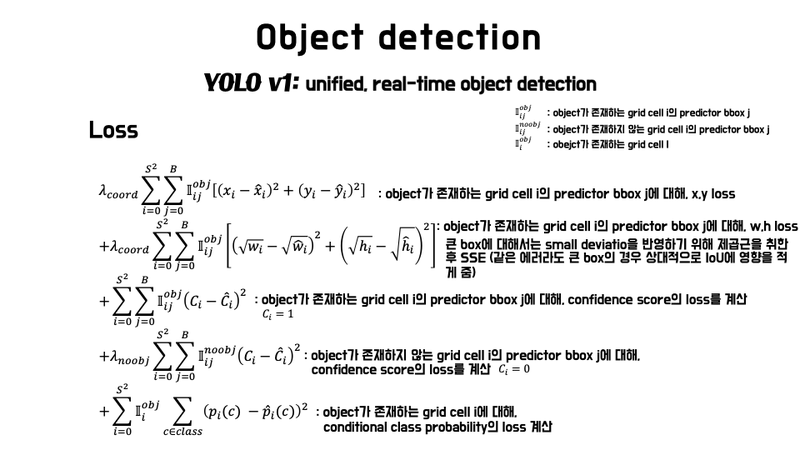
YOLO v1 의 loss 함수 ◇
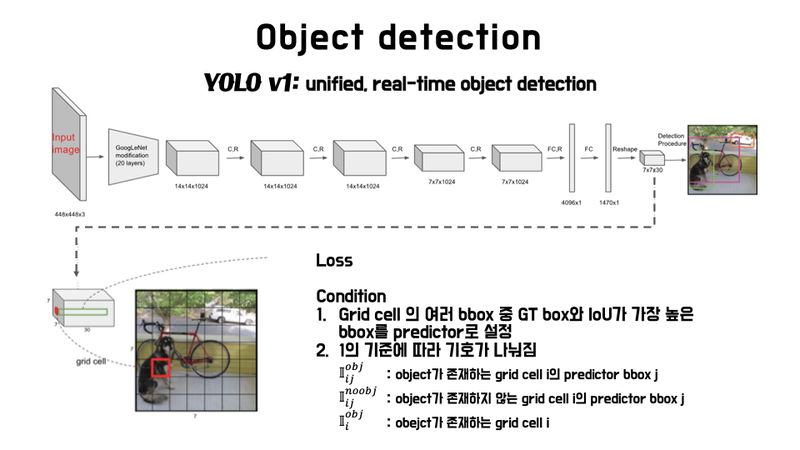
YOLO의 성능
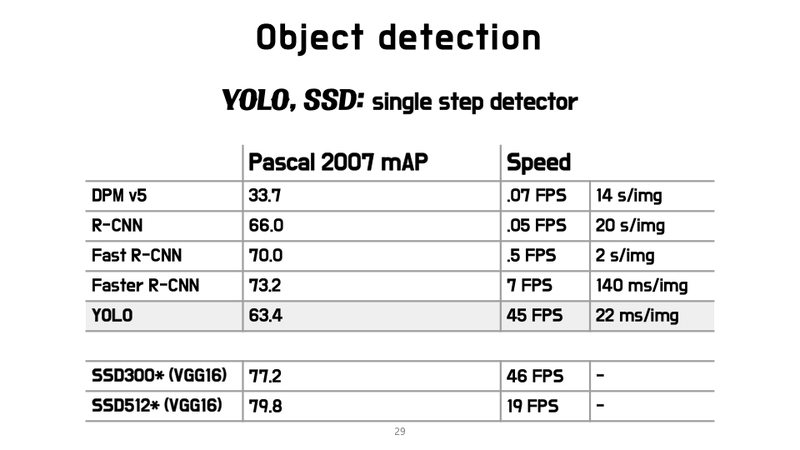
arXiv 논문 발표에서는 mAP가 63.4였지만 CVPR 2016 발표때는 69.0으로 모델의 성능을 향상되어 발표되었습니다. 즉 YOLO v1은 Faster R-CNN과 성능에 큰 차이가 나지 않으면서 속도는 6배 이상인 혁신적인 연구
◇ YOLO-V1 이슈 ◇
Detection 시간은 빠르나 Detection 성능이 떨어짐. 특히 작은 Object에 대한 성능이 나쁨
획기적이었던 YOLO v1에도 단점은 있었습니다. 우선 각각 grid cell이 하나의 클래스만 예측 가능하므로 작은 object에 대해 예측이 어려웠다. bbox의 형태가 training data를 통해 학습되었기 때문에 bbox 분산이 너무 넓어 새로운 형태의 bbox 예측이 잘 안되기도 했죠. 또한 모델 구조상 backbone만 거친 feature map을 대상으로 bbox 정보를 예측하기 때문에 localization이 다소 부정확했습니다. 그래서 2017년 YOLO v2이 나오게 됩니다.
◇ YOLO –v1, v2, v3 비교 ◇
anchor box 기반의 모델과 더 뛰어난 Backbone 구성, 다양한 성능 향상 테크닉을 적용하면서 발전됨.
| 항 목 | V1 | V2 | V3 |
|---|---|---|---|
| 원본 이미지 크기 | 446 X 446 | 416 X 416 | 416 X 416 |
| Feature Extractor | Inception 변형 | Darknet 19 | Darknet 53 |
| Grid당 Anchor Box 수 | 2개 (anchor box는 아님) | 5개 | Output Feature Map당 3개 서로 다른 크기와 스케일로 총 9개 |
| Anchor box 결정 방법 | K-Means Clustering | K-Means Clustering | |
| Output Feature Map 크기 (Depth 제외) | 7x7 | 13 x 13 | 13 x13 26 X 26, 52X52 3개의 Feature Map 사용 |
| Feature Map Scaling 기법 | FPN (Feature Pyramid Network) |
◇ PASCAL VOC 2007 Detection 시간 ◇
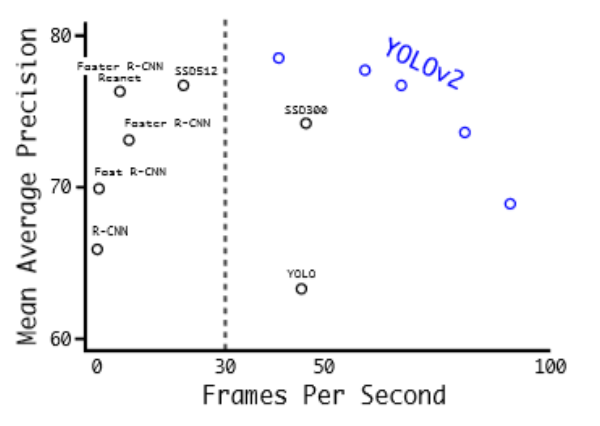
◇ MS-COCO 기준 Detection 성능 ◇