YOLO의 목적
- Make it better
- Do it faster
- Makes us stronger
Make it better
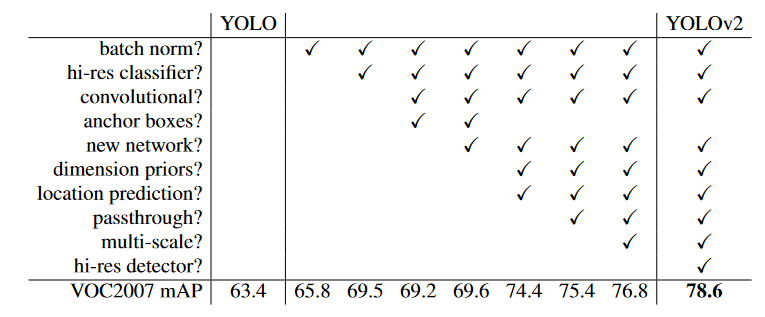
Better는 정확도를 올리기 위한 방법
- Batch Normalization
- High Resolution Classifier
- Convolutional with Anchor boxes
- Dimension Clusters
- Direct location prediction
- Fine-Grained Features
- Multi-Scale Training를 사용
Makes us stronger
stronger는 더 많은 범위의 class를 예측하기 위한 방법
- Hierarchical classification
- Dataset combination with WordTree
- Joint classification and detection를 사용
[Deeplearning] YOLO9000: Better, Faster, Stronger
YOLO v2 는 실제로 YOLO9000: Better, Faster, Stronger이라는 논문 이름으로 발표되었습니다. 9000개의 class를 classification하면서 detection까지 해내는 놀라움을 다시 한번 보여주는데요. 9000개의 클래스를 구성하는 방법까지는 다루지 않겠습니다. 궁금하신 분은 아래 링크를 참고
◇ Yolo v2 의 특징 ◇
- Batch Normalization
- High Resolution Classifier : 네트웍의 Classifier 단을 보다 높은 resolution(448x448)로 fine tuning
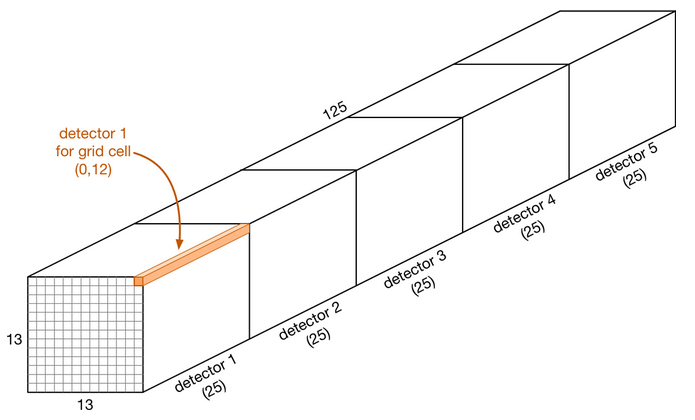
- 13 x 13 feature map 기반에서 개별 Grid cell 별 5개의 Anchor box에서 Object Detection
– anchor box의 크기와 ratio는 K-Means Clustering으로 설정. - 예측 Bbox의 x,y 좌표가 중심 Cell 내에서 벗어나지 않도록 Direct Location Prediction 적용
- Darknet-19 Classification 모델 채택
- Classification layer를 fully Connected layer에서 Fully Convolution 으로 변경하고 서로 다른 크기의 image들로 네트웍 학습
◇ Yolo v2 Anchor Box로 1 Cell에서 여러 개 Object Detection ◇
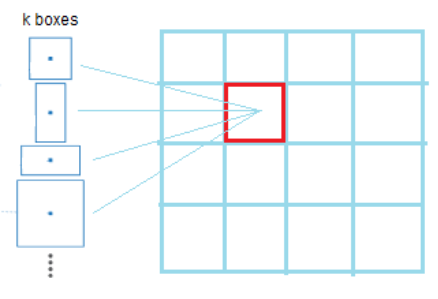
- SSD와 마찬가지로 1개의 Cell에서 여러 개의 Anchor를 통해 개별 Cell에서 여러 개 Object Detection 가능 K-Means Clustering 을 통해 데이터 세트의 이미지 크기와 Shape Ratio 따른 5개의 군집화 분류를 하여 Anchor Box를 계산
◇ YOLO v2 Output Feature Map ◇
◇ Direct Location Prediction ◇
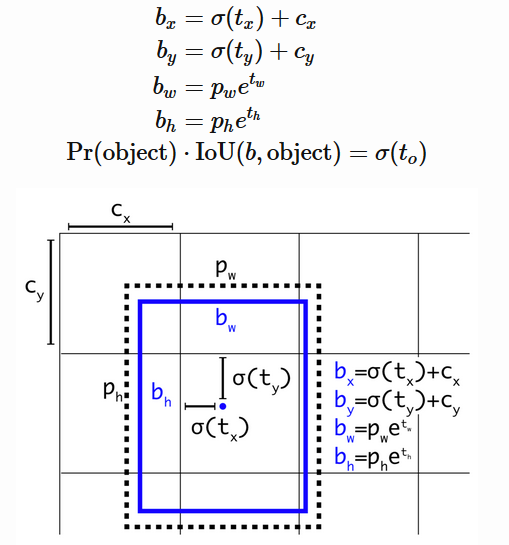
- (pw,ph): anchor box size
- (tx,ty,tw,th) : 모델 예측 offset 값
- (bx,by), (bw,bh): 예측 Bounding box 중심 좌표와 Size
Center 좌표가 Cell 중심을 너무 벗어나지 못하도록 0 ~ 1 사이의 시그모이드 값으로 조절
◇ YOLOv1 과 v2 Loss ◇
논문에는 YOLO V2 Loss에 대한 별도 언급이 없음
• YOLOv1 Loss 와 유사한 Loss식
Passthrough module을 통한 fine grained feature
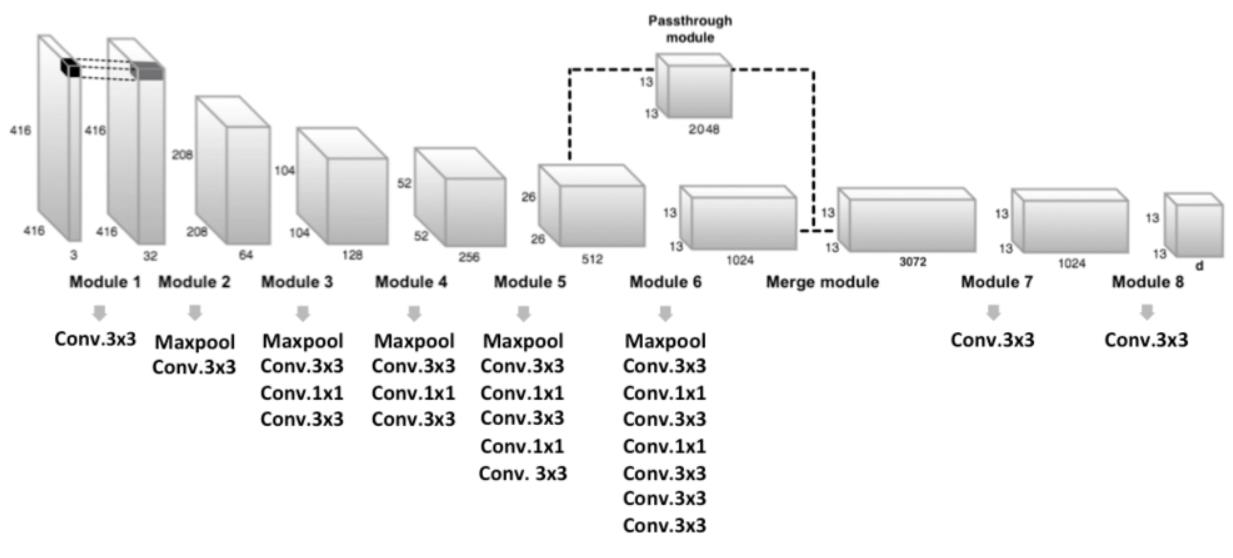
좀 더 작은 오브젝트를 Detect 하기 위해서 26x26x512 feature map의 특징을 유지한 채 13x13x2048 로 reshape한 뒤 13x13x1024에 추가하여 feature map 생성.
Multi-Scale Training
Classification layer가 Convolution layer로 생성하여 동적으로 입력 이미지 크 기 변경 가능 학습 시 10 회 배치 시 마다 입력 이미지 크기를 모델에서 320 부터 608까지 동적으로 변경(32의 배수로 설정)
Darknet 19 Backbone
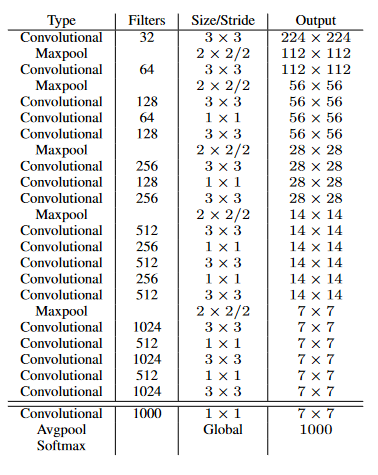
VGG-16: 30.69 BFLOPS, Top 5 Accuracy: 90%
Yolo v1: 8.52 BFlops , Top 5 Accuracy: 88%
Darknet-19: 19: 5.58 BFLOPS, Top 5 Accuracy: 91.2%
Classification layer에 Fully Connected layer를 제거하고 Conv layer를 적용.
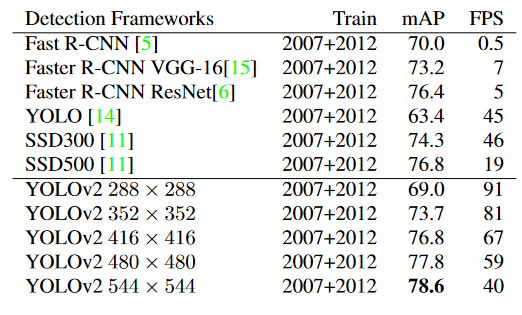
YOLO-v2 성능 향상
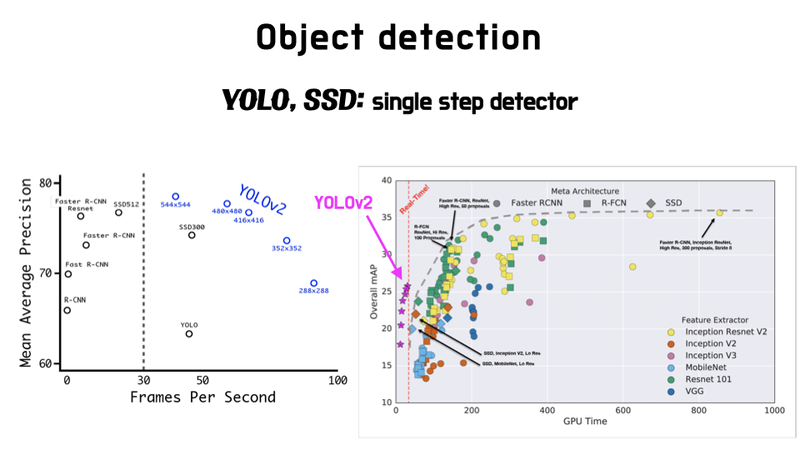
YOLO v2 당시 SSD, R-FCN 등이 이미 발표된 상황이었습니다. 특히 SSD와 YOLO는 같은 single stage 방법을 지향하고 있었기 때문에 경쟁 모델이 되었고, YOLO v2 입장에서는 SSD와의 성능 차이를 부각시키는게 중요한 과제