Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks (2015)
초록
기존의 object detection의 State Of The Art 였던 SPPnet, Fast R-CNN 같은 네트워크들은 region proposal algorithm에 의존했고, 위의 두 모델은 detection network의 시간 감소를 보였지만 region proposal 연산이 bottleneck으로써 작동된다는 사실을 노출시켰다. 그래서 이 논문에서는 detection network의 convolution feature를 공유하여 region proposal에 거의 시간을 사용하지 않는 Region Proposal Network (이하 RPN)을 제안한다. 이 논문에서는 RPN과 Fast R-CNN을 하나의 network로 묶어 convolution feature를 공유하도록 한다.
1. Introduction
최근 (2015년 기준) object detection은 region proposal 방법론과 R-CNN을 이용하여 발전해왔다. 이는 매우 high-cost를 요했지만 Fast R-CNN으로 그 문제점을 해결했다. 하지만 region proposal은 test-time에서 computational bottleneck을 일으킨다.
Region Proposal 방법론 중에 가장 많이 쓰이는 Selective Search는 효율적인 detection network와 비교하여 CPU 구현을 하며 이미지 당 2초를 소요하여 매우 느리다. EdgeBoxes가 그나마 조금 더 빠르긴하지만 detection network에서 매우 많은 시간을 잡는다.
R-CNN은 GPU 연산의 이점을 볼 수 있지만 Region proposal은 CPU에서 연산되어 이러한 많은 시간을 소요하게 하는 것이다. 그렇기 때문에 시간을 획기적으로 줄이기 위해서는 이런 region proposal을 GPU에서 하는 것이 필요하다. 이것은 효과적인 솔루션이지만 다시 구현하는 것은 다운스트림 detection network를 무시하고 계산을 공유하는 것에서 중요한 기회를 놓칠 수 있다. (re-implementation ignores the downstream detection network and therefore misses important opportunities for sharing computation)
그래서 본 논문에서는 State Of The Art인 object detection 모델과 convolution layers를 공유하는 RPN을 제안한다. test-time에서 convolutions을 공유하므로써 region proposal에 걸리는 시간을 줄일 수 있다.
Fast R-CNN같은 Region based detector에서 쓰이는 convolutional feature map은 region proposal에서도 사용 가능하다는 것을 밝혔다. 이 convolutional features의 가장 윗 부분에 몇 개의 추가적인 convolution layers를 더함으로써 RPN을 구성하고, 이 convolution layers에서는 동시에 region bound에 대해 회귀(regress)하고 일정한 사이즈의 각각의 위치에 대해 사물이 있을지에 대한 점수를 매긴다.
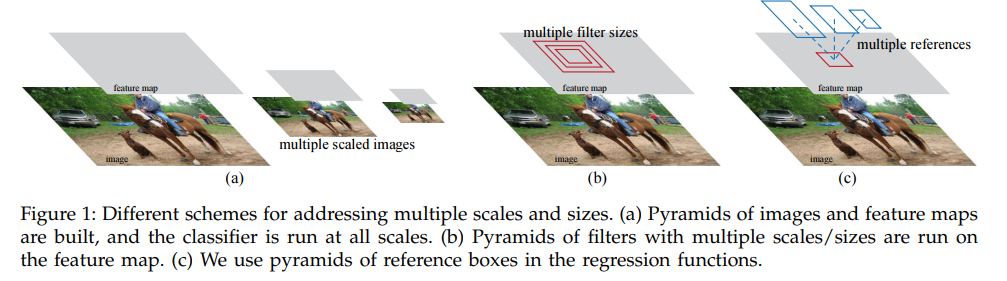
RPN은 넓은 범위의 scale과 다양한 가로세로비를 이용하여 region proposal을 한다. 이는 pyramids of images or pyramids of filters를 사용했던 이전의 방법과 대비된다. 즉, 본 논문에서는 anchor box를 이용하여 다양한 크기와 가로세로비를 이용한다.
또한 RPN과 Fast R-CNN을 합치기 위해서 region proposal에 대한 fine tuning과 object detection에 대한 fine tuning을 번갈아 한다. 이러한 방식은 통합된 네트워크가 더 빠르게 수렴하게 한다.
2. Related Work
Object Proposals
많이 사용되는 object proposal methods는 super-pixels를 묶는 방법(e.g., Selective Search, CPMC, MCG)과 sliding windows를 사용하는 방법(e.g., objectness in windows, EdgeBoxes)가 있다. 이러한 object proposal methods는 detection model과 별개로 적용되는 외부의 모듈로써 사용되었다.
Deep Networks for Object Detection
R-CNN은 CNN을 end-to-end로 학습시켜 proposal regions를 어떤 카테고리나 배경으로 분류하게끔 학습시켰다. R-CNN은 classifier 분류기로써 이용되고, object bounds를 예측하진 못한다. 이 학습 정확도는 region proposal method의 성능에 좌우된다. 몇몇 논문들이 deep network를 이용하여 bounding box까지 예측하려 했고, OverFeat에서 fully-connected layer를 이용하여 단일 객체의 bounding box의 좌표를 학습시켰다. Fully connected layer는 convolution layer로 바뀌면서 여러 클래스별 객체를 감지한다. MultiBox는 네트워크의 마지막 fully connected layer로써 동시에 여러 class-agnostic box (object는 있지만 그것이 어떤 class인지는 모르는 box)를 예측했다. 이는 OverFeat를 일반화한 것이다. 이러한 class-agnostic box는 R-CNN에서 region proposal을 위해 사용되기도 한다.
3. Faster R-CNN
Faster R-CNN은 두가지 모듈로 나누어져있다. 첫번째 모듈은 지역을 제안하는 deep fully convolutional network이고 두번째 모듈은 제안된 지역을 감지하는 Fast R-CNN 모듈이다. 이 전체의 시스템은 하나의 통합된 네트워크이다. attention 메타니즘을 사용하면서 RPN 모듈은 Fast R-CNN이 무엇을 봐야할 지 알려준다.
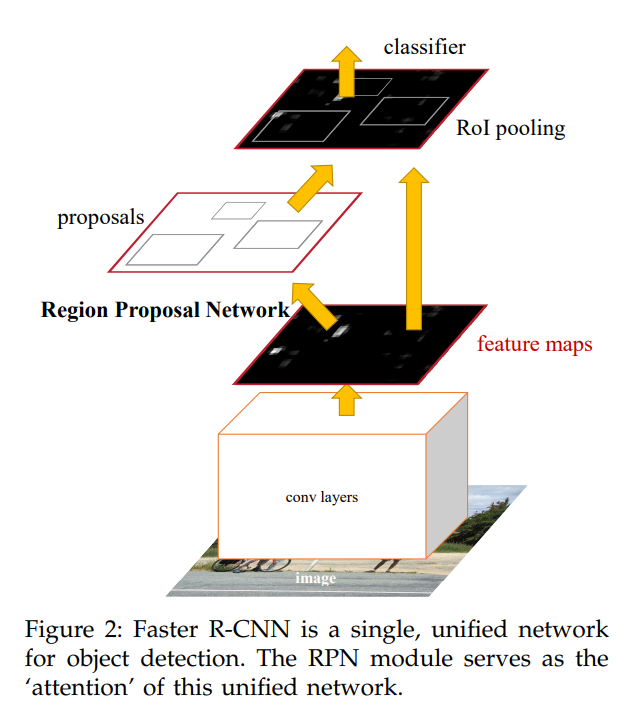
3.1 Region Proposal Networks
RPN은 image (어떤 사이즈든 상관 X)를 input으로 받아 output으로 직사각형의 object proposal 집합과 그 proposal에 해당하는 score를 제공한다. 이 RPN의 최종 목표는 Fast R-CNN과 공유된 연산을 하는 것이기 때문에 이 RPN과 Fast R-CNN이 모두 convolutional layer를 공통으로 갖고 있어야 하고, 따라서 RPN도 convolutional layer로 이루어져 있다.
region proposal을 만들기 위해서 마지막에 나온 convolution feature map 위에서 작은 네트워크를 슬라이드 한다. 이 작은 네트워크는 크기의 convolution feature map의 window를 input으로 받는다. 각각의 sliding window는 저차원의 feature와 mapping 되는데, 이 feature는 box regression layer와 box classification layer로 나눠지게 된다. 본 논문에서는 을 사용했고, 이 작은 네트워크는 아래 사진과 같다. 이 작은 네트워크는 sliding-window 방식으로 진행되기 때문에 fully connected layer는 공간적인 특성을 가지고 있고, 이 아키텍쳐는 convolution layer 뒤에 convolution layer가 뒤따르는 형태를 갖고 있다 (for reg and cls, repectively).
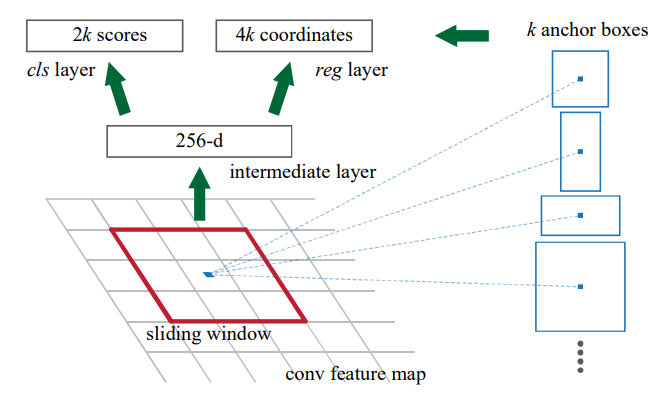
3.1.1 Anchors
각각의 sliding-window 위치에서 우리는 동시에 여러 region proposal을 예측해야 한다. 이 때 우리의 가능한 최대의 예측의 개수를 라 한다. 그렇기 때문에 reg layer는 총 개의 박스에 대한 좌표인 의 결과를 예측하고, cls layer는 그 box 안에 물체가 있는지 없는지를 확인하기 위해 의 점수를 추정한다. 개의 제안들은 개의 reference box와 관련하여 parameterize되고, 이 reference box를 anchor라 한다. Anchor는 sliding window의 중앙에 위치하고 이는 3개의 크기와 3개의 가로세로비로 총 9개의 anchor를 사용한다. 즉, 크기의 feature map이 있다면 총 개의 anchor가 존재한다.
Translation-Invariant Anchors
Translation-Invariant는 anchor의 중요한 성질이다. translation invariant란 어떤 위치에서든 잘 anchor가 작동되도록 하는 특성을 의미한다. MultiBox는 k-means를 이용해서 800개의 anchor를 생성하는데 이는 translation invariant가 아니다. 즉, MultiBox는 한 객체가 translated 되어도 같은 제안을 하지 않는다.
이 특성은 모델 사이즈를 줄이는 데에도 영향을 미친다. MultiBox는 -dimensional fully connected output layer를 갖고 있지만 우리의 방법은 일 때, -dimensional convolutional output layer를 가진다.
Multi-Scale Anchors as Regression References
multi-scale predictions에는 크게 두가지 방법이 있다. 첫번째는 image/feature pyramids를 기반으로 한 방식이다. image들은 여러 크기로 resize되고, feature map들은 각각의 scale로 계산된다. 이 방법은 대체로 유용하지만 시간이 많이 쓰인다. 두번째 방법은 feature map 상에서 여러 크기, 또는 여러 가로 세로 비율의 sliding window를 사용하는 방법이다. 이것은 pyramid of filters라고 생각될 수 있다.
비교적으로 우리의 anchor based method는 pyramid of anchors를 기반으로 하고, 이것은 조금 더 효율적이다. 우리의 방법은 다양한 크기와 가로 세로 비율의 anchor box를 이용해 bounding box를 회귀한다. 이것은 오직 단일 scale의 feature map과 이미지에 의존하고, 단일 size의 filter를 사용한다.
3.1.2 Loss Function
RPN을 학습시킬 때 우리는 물체인지 아닌지를 확인하는 binary class를 각각의 anchor에 적용한다. 우리는 ground-truth box와 IoU (Intersection over Union) 을 계산하여 0.7이 넘는다면 positive label을 부여하고, 0.3보다 작다면 negative label을 부여한다. positive label과 negative label을 제외한 anchor box는 학습에 영향을 주지 않는다.
이런 정의를 바탕으로 loss function을 다음과 같이 정의한다.
는 mini-batch 안의 anchor의 indes number이고, 는 anchor 가 object일 확률이다. 은 ground truth의 label로 anchor가 positive면 1, negative면 0이다. 는 예측된 bounding box의 4개의 parameterized된 좌표이고, 은 positive anchor의 ground truth 좌표이다.
Classification loss인 는 object인지 아닌지를 구별하는 두 class의 log loss이고, regression loss인 는 로 정의하고, 은 robust loss function (smooth )이다.
는 regression loss가 positive anchor ()일 때만 activate 되고, negative anchor일 때 deactivate 되도록 한다.
Normalized Factor인 , 는 balancing parameter 에 의해 가중치가 조정된다. 본 논문의 implementation 에서는 는 mini_batch size로 normalized 되었고 (256), 는 anchor locations의 개수에 의해 normalized 되었다. 그리고 을 default로 사용하여 거의 같은 비중으로 적용되도록 했다. 실험 결과에 따르면 의 사이즈에 크게 바뀌지 않는 것을 보았다.
bounding box regression에서는 4개의 좌표르 다음과 같이 parameterization 한다.
,
,
,
,
는 각각 box의 center 좌표, 그리고 width, height를 의미한다. 그리고 은 각각 predicted box, anchor box, ground-truth box를 의미한다.
3.1.3 Training RPNs
생략
