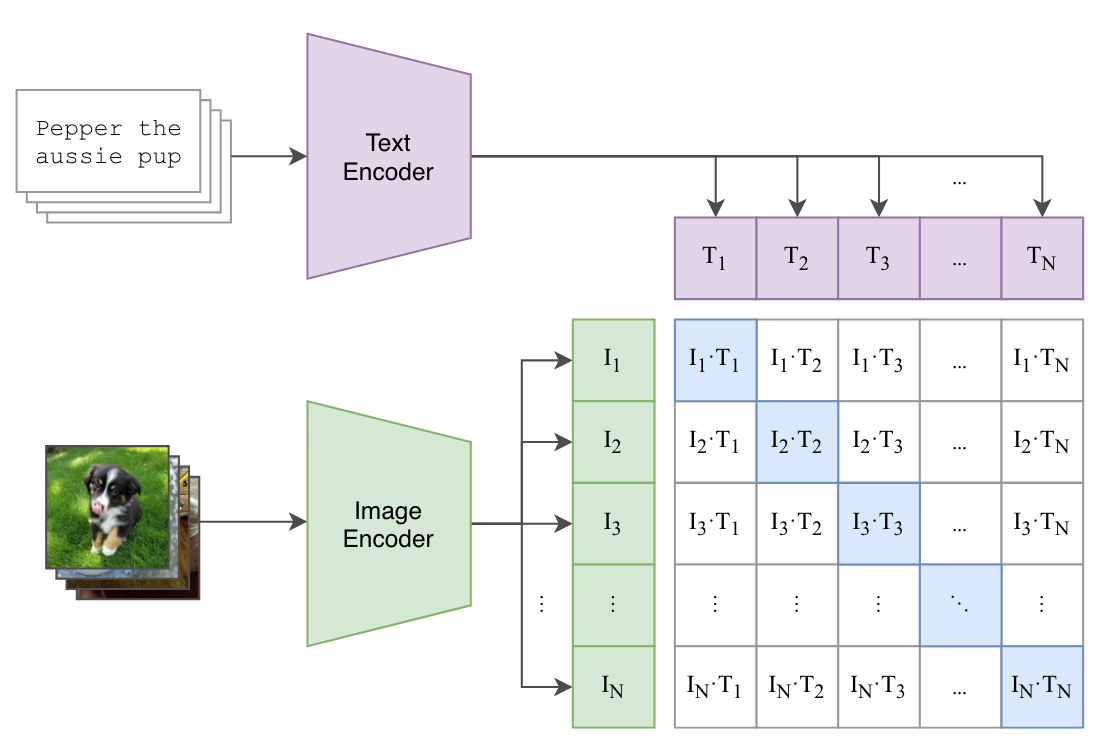
CLIP은 OpenAI에서 개발한 멀티모달 AI 모델로, 텍스트와 이미지를 함께 이해하는 모델이야. 기본적으로, 텍스트와 이미지가 연관된 정도를 학습하여 이미지 검색, 분류, 생성 등 다양한 작업을 수행할 수 있어.
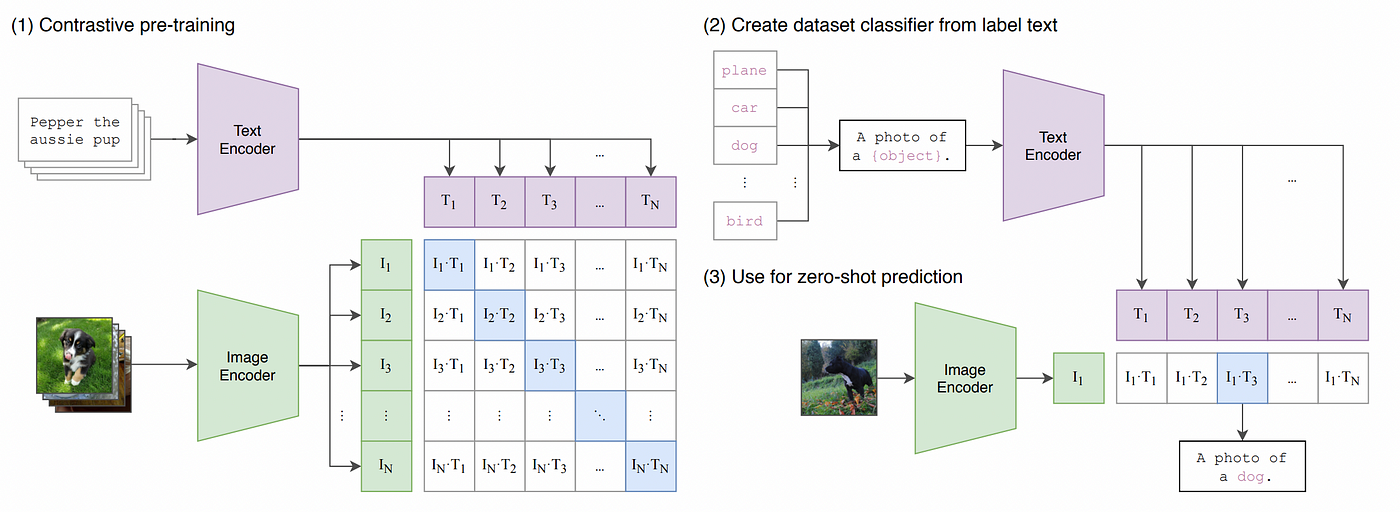
1. CLIP의 기본 개념
- Contrastive Learning(대조 학습) 방식 사용:
- 같은 의미의 텍스트-이미지 쌍을 가깝게(Low distance),
- 다른 의미의 텍스트-이미지 쌍을 멀게(High distance) 학습하는 방식
- Zero-shot 학습 가능:
- CLIP은 특정 태스크에 대해 별도로 학습하지 않아도, 사전에 학습된 데이터만으로도 강력한 성능을 발휘할 수 있어!
- 예를 들어, 새로운 이미지 카테고리를 위한 분류 모델을 학습하지 않아도, "고양이", "강아지" 등의 텍스트와 이미지를 비교하여 분류 가능
2. CLIP의 구조 (아키텍처)
CLIP은 크게 두 개의 신경망(Neural Network)으로 구성돼 있어:
-
Vision Encoder (이미지 인코더)
- CNN(ResNet-50/101) 또는 Vision Transformer (ViT) 기반
- 입력된 이미지를 벡터 형태로 변환
-
Text Encoder (텍스트 인코더)
- Transformer 기반 모델 사용 (GPT 아키텍처와 유사)
-입력된 텍스트를 벡터 형태로 변환
- Transformer 기반 모델 사용 (GPT 아키텍처와 유사)
💡 핵심 아이디어:
이미지와 텍스트를 같은 차원의 벡터 공간에 매핑한 후, 의미가 비슷한 경우 벡터 거리가 가까워지도록 학습하는 방식
3. CLIP의 학습 방식 (Contrastive Learning)
CLIP은 Contrastive Loss를 사용해서 학습해!
- 한 배치(Batch)에는 여러 개의 (이미지, 텍스트) 쌍이 포함됨
- 같은 쌍은 유사도 점수를 최대화하고, 다른 쌍은 유사도 점수를 최소화하는 방식으로 학습
📌 예제
이미지 1: 🐶 (강아지 사진)
이미지 2: 🏎️ (자동차 사진)
텍스트 1: "A cute dog"
텍스트 2: "A fast car"
👉 CLIP은 🐶 ↔ "A cute dog"의 유사도를 높이고, 🐶 ↔ "A fast car"의 유사도를 낮추는 방향으로 학습됨
CLIP의 모델 아키텍처 코드에 대해 상세히 설명해줄게! 🚀
CLIP의 핵심 구조는 크게 Vision Encoder(이미지 인코더)와 Text Encoder(텍스트 인코더)로 나뉘고, 두 인코더의 출력을 같은 임베딩 공간으로 매핑한 후 대조 학습(Contrastive Learning)을 수행.
모델 구조 상세 분석
🏗 1. CLIP 모델 아키텍처 개요
CLIP의 구조는 다음과 같이 구성:
- Vision Encoder (ResNet or Vision Transformer 기반)
- Text Encoder (Transformer 기반, GPT-like 구조)
- Projection Head (이미지와 텍스트 임베딩을 동일한 차원으로 변환)
- Contrastive Loss (이미지-텍스트 매칭 학습)
🔍 2. CLIP의 주요 코드 분석
CLIP 모델의 원본 코드는 OpenAI의 CLIP 공식 GitHub에 공개.
여기서 핵심이 되는 부분을 하나씩 분석.
🖼 (1) Vision Encoder (이미지 인코더)
CLIP의 이미지 인코더는 ResNet 또는 Vision Transformer (ViT)을 사용.
아래는 ViT 기반의 이미지 인코더 코드.
import torch
import torch.nn as nn
from torchvision.models import vit_b_32
class VisionTransformer(nn.Module):
def __init__(self, embed_dim=512):
super().__init__()
self.model = vit_b_32(pretrained=True) # 미리 학습된 ViT 사용
self.fc = nn.Linear(768, embed_dim) # 최종 출력 차원을 512로 변환
def forward(self, images):
x = self.model(images) # 이미지 인코딩
x = self.fc(x) # FC 레이어를 통해 차원 변환
return x✅ 설명
vit_b_32(pretrained=True): 사전 학습된 Vision Transformer(ViT) 사용self.fc = nn.Linear(768, embed_dim): ViT 출력 (768차원) → 512차원 변환- 입력: 이미지 (Tensor)
- 출력: 512차원 이미지 임베딩 벡터
📝 (2) Text Encoder (텍스트 인코더)
텍스트 인코더는 Transformer 기반이고, GPT와 유사한 구조야.
from transformers import RobertaModel
class TextEncoder(nn.Module):
def __init__(self, embed_dim=512):
super().__init__()
self.model = RobertaModel.from_pretrained("roberta-base") # Pretrained Transformer
self.fc = nn.Linear(768, embed_dim) # 차원 축소
def forward(self, input_ids, attention_mask):
x = self.model(input_ids=input_ids, attention_mask=attention_mask)
x = x.last_hidden_state[:, 0, :] # CLS 토큰 사용
x = self.fc(x) # FC 레이어
return x✅ 설명
RobertaModel.from_pretrained("roberta-base"): 사전 학습된 RoBERTa 모델 사용x.last_hidden_state[:, 0, :]: 문장의 첫 번째 토큰(CLS 토큰) 사용self.fc = nn.Linear(768, embed_dim): 768차원 → 512차원 변환- 입력: 토큰화된 텍스트
- 출력: 512차원 텍스트 임베딩
🔄 (3) Projection Head (공통 임베딩 공간 매핑)
이미지와 텍스트 임베딩을 같은 공간으로 변환하기 위해 선형 변환을 사용.
class ProjectionHead(nn.Module):
def __init__(self, embed_dim=512, proj_dim=512):
super().__init__()
self.projection = nn.Linear(embed_dim, proj_dim) # 512 -> 512 (동일 차원 변환)
self.scale = nn.Parameter(torch.ones(1) * 0.07) # Temperature scaling
def forward(self, x):
x = self.projection(x)
x = x / x.norm(dim=-1, keepdim=True) # L2 정규화
return x * self.scale✅ 설명
nn.Linear(embed_dim, proj_dim): 512차원 → 512차원 변환x / x.norm(dim=-1, keepdim=True): L2 정규화self.scale = nn.Parameter(torch.ones(1) * 0.07): Softmax 온도 파라미터
🎯 (4) Contrastive Learning (대조 학습)
CLIP은 Contrastive Learning을 사용해서 이미지와 텍스트를 서로 매칭하는 방식으로 학습.
import torch.nn.functional as F
class CLIPLoss(nn.Module):
def forward(self, image_features, text_features):
# 이미지와 텍스트 간 내적 계산
logits = image_features @ text_features.T # Cosine Similarity
labels = torch.arange(len(logits)).to(logits.device)
# CrossEntropyLoss 적용 (이미지-텍스트 정답 매칭)
loss = (F.cross_entropy(logits, labels) + F.cross_entropy(logits.T, labels)) / 2
return loss✅ 설명
logits = image_features @ text_features.T: 이미지와 텍스트 벡터 간 내적(유사도 계산)labels = torch.arange(len(logits)): 정답 레이블 생성F.cross_entropy(logits, labels): 정답 텍스트와 가장 유사한 이미지 찾도록 학습
🔗 (5) CLIP 전체 모델
위에서 만든 인코더, 프로젝션 헤드, Contrastive Loss를 결합하여 최종 CLIP 모델을 생성.
class CLIP(nn.Module):
def __init__(self, embed_dim=512):
super().__init__()
self.vision_encoder = VisionTransformer(embed_dim)
self.text_encoder = TextEncoder(embed_dim)
self.vision_proj = ProjectionHead(embed_dim)
self.text_proj = ProjectionHead(embed_dim)
self.loss_fn = CLIPLoss()
def forward(self, images, input_ids, attention_mask):
image_features = self.vision_proj(self.vision_encoder(images))
text_features = self.text_proj(self.text_encoder(input_ids, attention_mask))
loss = self.loss_fn(image_features, text_features)
return loss, image_features, text_features✅ 설명
VisionTransformer,TextEncoder사용하여 이미지/텍스트 임베딩 생성ProjectionHead로 공통 임베딩 공간으로 변환CLIPLoss를 통해 Contrastive Learning 수행
🎯 3. CLIP 코드 실행 방법
OpenAI의 CLIP 모델을 직접 실행.
import clip
import torch
from PIL import Image
# CLIP 모델 및 변환기 불러오기
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-B/32", device=device)
# 이미지 로드 및 변환
image = preprocess(Image.open("dog.jpg")).unsqueeze(0).to(device)
# 텍스트 입력
texts = ["a photo of a dog", "a photo of a cat"]
text_tokens = clip.tokenize(texts).to(device)
# 이미지 및 텍스트 특징 추출
with torch.no_grad():
image_features = model.encode_image(image)
text_features = model.encode_text(text_tokens)
# 유사도 계산
similarity = (image_features @ text_features.T).softmax(dim=-1)
print(similarity)🏆 4. 결론
- CLIP은 Vision Encoder + Text Encoder를 이용하여 멀티모달 학습을 수행
- Contrastive Learning을 통해 이미지-텍스트 유사도를 학습
- 다양한 응용 가능 (이미지 검색, Zero-shot 분류 등)
