논문
https://arxiv.org/pdf/2401.12168
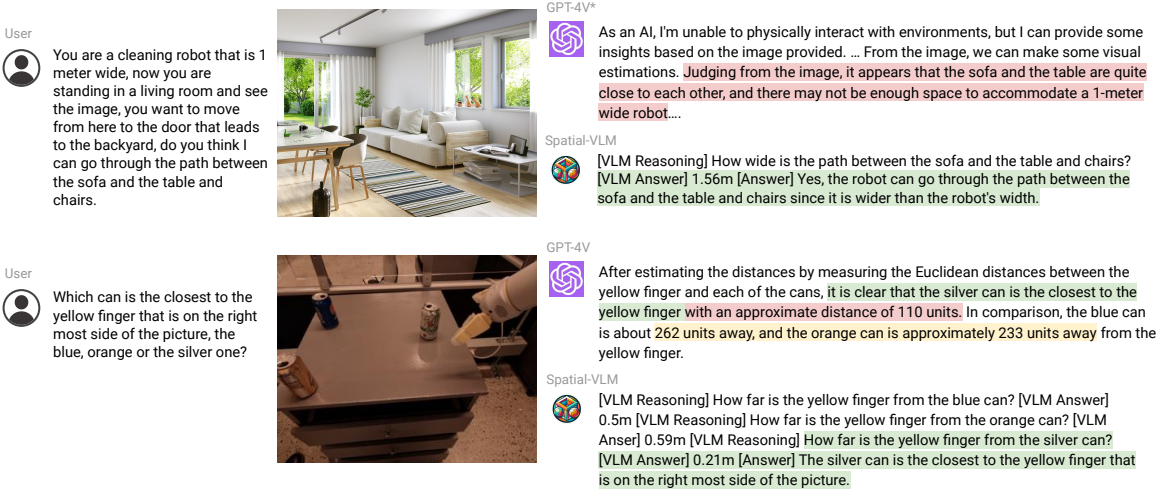
1. 연구 배경 및 문제 제기
시각적 질문 답변(Visual Question Answering, VQA) 및 로봇 공학에서 공간적 관계(Spatial Reasoning) 를 이해하고 추론하는 능력은 매우 중요합니다. 기존의 비전-언어 모델(Vision-Language Models, VLMs) 은 VQA 벤치마크에서 인상적인 성능을 보였지만, 3D 공간적 추론 능력 에 있어서는 한계를 보였습니다.
특히, 기존 VLM 모델은 다음과 같은 공간적 인식 능력이 부족했습니다:
- 객체 간의 거리 (Quantitative Spatial Relationships)
- 크기 차이 (Size Differences)
- 정확한 물리적 관계 추론
이러한 한계는 훈련 데이터 부족 때문이라고 저자들은 가정합니다. 즉, 기존 VLM이 3D 공간적 정보를 충분히 학습하지 않았다는 것입니다.
2. 연구 목표
이 논문에서는 대규모 인터넷 데이터셋을 활용하여 VLM의 공간적 추론 능력을 강화하는 방법을 제안합니다. 이를 통해 모델이 정성적(qualitative)뿐만 아니라 정량적(quantitative) 공간적 질문에도 답할 수 있도록 합니다.
3. 연구 방법
연구진은 인터넷 규모의 공간적 추론 데이터를 생성하는 자동 3D 공간 VQA 데이터 생성 프레임워크를 개발했습니다.
이를 통해 10억 개(2 billion) 이상의 VQA 예제와 1,000만 개(10 million) 이상의 실세계 이미지를 포함하는 대규모 데이터셋을 구축했습니다.
본 논문은 VLM에 정성적 및 정량적 공간 추론 능력을 모두 제공하기 위해, 대규모의 공간적 VQA 데이터셋을 생성하는 것을 제안하였다. 구체적으로, 기존 비전 모델을 활용하여 물체 중심의 컨텍스트를 추출한 다음, 템플릿 기반 접근 방식을 채택하여 적절한 품질의 방대한 공간적 VQA 데이터를 생성하는 포괄적인 데이터 생성 프레임워크를 설계하였다. 생성된 데이터셋을 사용하여 SpatialVLM을 학습시켜 direct spatial reasoning 능력을 학습한 다음, 이를 LLM에 내장된 고수준의 상식적 추론과 결합하여 chain-of-thought spatial reasoning을 할 수 있다.
1. Spatial Grounding from 2D Images
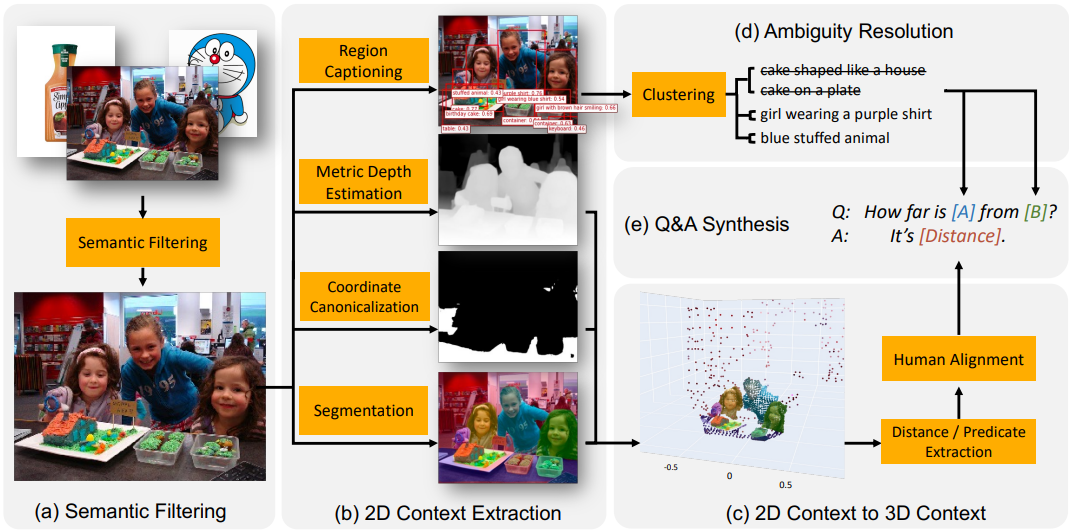
오늘날 VLM의 공간 추론 능력이 부족한 이유는 아키텍처가 아니라 학습 데이터가 부족하기 때문이다. 저자들은 이러한 통찰력에 따라 공간 추론 질문이 포함된 VQA 데이터를 생성하는 파이프라인을 설계하였다.
Semantic 필터링
인터넷 규모의 이미지 캡션 데이터셋은 VLM 학습에 널리 사용되었지만, 이러한 데이터셋의 많은 이미지는 하나의 물체로 구성되거나 장면 배경이 없기 때문에 공간 추론 QA를 합성하기에 적합하지 않다. 따라서 데이터 합성 파이프라인의 첫 번째 단계로 모든 이미지를 분류하고 적합하지 않은 이미지를 제외하기 위해 CLIP 기반 open-vocabulary classification 모델을 채택한다.
2D 이미지에서 물체 중심의 컨텍스트 추출
2D 이미지에서 물체 중심의 공간적 컨텍스트를 추출하기 위해, region proposal, region captioning, semantic segmentation 모듈을 포함한 일련의 전문가 모델을 활용하여 물체 중심의 정보를 추출한다. 이 단계에서는 픽셀 클러스터와 open-vocabulary 캡션 설명으로 구성된 물체 중심의 엔티티를 얻는다.
2D 컨텍스트를 3D 컨텍스트로 끌어올리기
Object detection과 bounding box positioning을 사용하여 생성된 기존의 공간적 VQA 데이터셋은 2D 이미지 평면과 픽셀 수준 추론으로 제한된다. 2D 픽셀을 미터 스케일의 3D 포인트 클라우드로 끌어올리기 위해 깊이 추정을 수행한다. 포인트 클라우드의 카메라 좌표계를 정규화하기 위해, 수평 표면(ex. 바닥, 테이블 위)을 segmentation하여 기준으로 사용한다.
모호성 해결
때로는 한 이미지에 유사한 범주의 여러 물체가 있어 캡션 레이블이 모호해지는 경우가 있다. 따라서 이러한 물체에 대한 질문을 하기 전에 참조 표현이 모호하지 않은지 확인해야 한다. 저자들은 이를 해결하는 데 효과적인 두 가지 핵심 디자인 선택을 했다.
-
“케이크”와 같은 고정적이고 대략적인 범주를 생성하는 경향이 있는 일반적인 object detector를 의도적으로 피하고, 사용자 맞춤 설정이 가능한 물체 중심의 캡션 생성 방식인 FlexCap을 채택한다. 실제로 각 물체에 대해 1-6단어 사이의 가변 길이의 무작위 캡션을 샘플링할 수 있다. 결과적으로 물체 주석은 “집 모양의 케이크”, “플라스틱 용기에 담긴 컵케이크”와 같이 세분화된다.
-
물체 캡션들을 증강하거나 거부함으로써 모호성을 제거하는 semantic 중심의 후처리 알고리즘을 설계하였다.
2. Large-Scale Spatial Reasoning VQA Dataset
저자들은 VLM을 합성 데이터로 사전 학습시켜 VLM에 간단한 공간 추론 능력을 주입하는 데 집중하였다. 따라서 이미지에서 두 개 이하의 물체(A와 B로 표시)만 포함하는 공간 추론 QA 쌍을 합성하고 다음 두 가지 질문 카테고리를 고려하였다.
- 정성적 질문: 어떤 공간적 관계에 대한 판단을 요구하는 질문
- 두 개의 물체 A와 B가 주어졌을 때, 어느 것이 더 왼쪽에 있는가?
- 물체 A가 물체 B보다 더 높이 있는가?
- A와 B 중에서 어느 것이 너비가 더 큰가?
- 정량적 질문: 숫자와 단위를 포함하는 보다 세부적인 답변을 요구하는 질문
- 물체 A는 물체 B에 비해 얼마나 왼쪽에 있는가?
- 물체 A는 B에서 얼마나 떨어져 있는가?
- 카메라에 대해서 A가 B 뒤에 얼마나 떨어져 있는가?
정량적 질문은 주요 질문 템플릿을 사용하여 합성할 수 있으며, 모호성을 해소한 후 캡션을 사용하여 물체 이름을 채울 수 있다. 이를 통해 일반적으로 instruction tuning 방법들에서 채택하는 접근 방식인 템플릿 기반 생성을 수행할 수 있다. 질문에 대한 답변은 관련 물체의 분할된 포인트 클라우드와 3D bounding box를 입력으로 사용하는 적절한 함수를 통해 얻는다.
저자들은 각각 약 20개의 질문 템플릿과 10개의 답변 템플릿을 특징으로 하는 38개의 서로 다른 유형의 정성적 및 정량적 질문을 설계하였다. 또한 간결한 답변을 장려하기 위해 샘플링에 편향을 추가하였다. 마지막으로 인간과 유사한 방식으로 숫자를 반올림하는 반올림 메커니즘을 도입하였다. 이러한 접근 방식을 사용하여 monocular 카메라 이미지에 대한 충분한 QA 데이터 쌍을 생성할 수 있다.
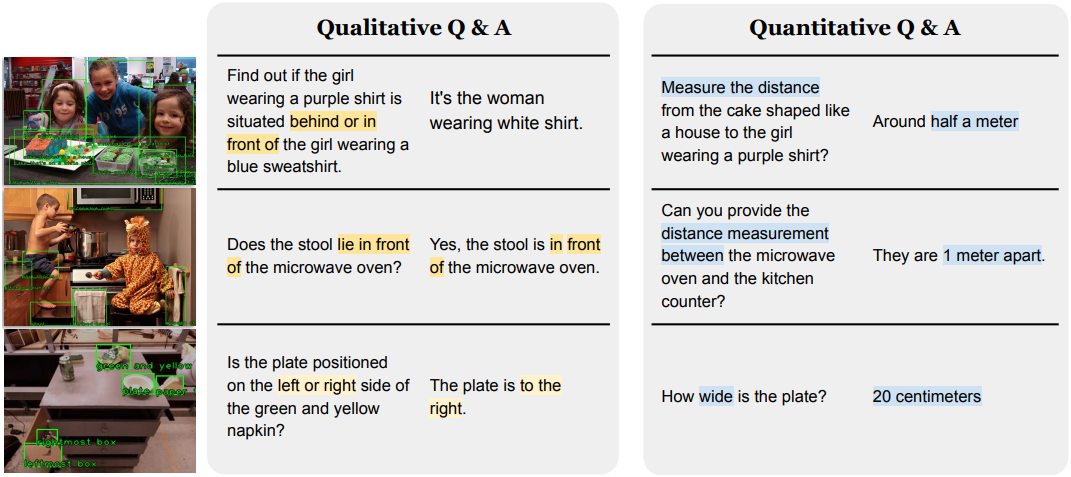
위는 생성된 몇 가지 합성 QA 쌍의 예시들이다. 전체적으로 1,000만 개의 이미지와 20억 개의 direct spatial reasoning QA 쌍이 있는 방대한 데이터셋을 생성하며, 50%는 정성적 질문이고 50%는 정량적 질문이다. 물체 캡션과 거리 단위의 다양성 덕분에 합성 데이터셋은 물체 설명, 질문 유형 등에서 상당한 다양성을 제공한다.
3. Learning Spatial Reasoning
Direct Spatial Reasoning
Direct spatial reasoning이란 VLM이 이미지 I와 공간적 task의 쿼리
Q를 입력으로 받고, 외부 도구나 다른 대형 모델과 상호 작용하지 않고 텍스트 문자열 형식으로 답변 A를 출력하는 것이다.
저자들은 PaLM-E와 동일한 아키텍처와 학습 절차를 채택하였지만 PaLM backbone을 더 작은 PaLM 2-S로 대체하였다. 그런 다음 원래 PaLM-E 데이터셋과 본 논문의 데이터셋을 혼합하여 모델을 학습시키고 토큰의 5%를 공간 추론 task에 할당하였다.
Chain-of-Thought Spatial Reasoning
많은 실제 task에는 여러 단계의 공간 추론이 필요하다. 예를 들어, 물체 A가 물체 B에 들어갈 수 있는지 확인하려면 크기와 제약에 대해 추론해야 한다. 때로는 근거 있는 공간적 개념과 상식적 지식을 통해 추론해야 한다. SpatialVLM은 근거 있는 개념으로 쿼리할 수 있는 자연어 인터페이스를 제공하며, 강력한 LLM과 결합하면 복잡한 공간 추론을 수행할 수 있다.

이 방법을 Chain-of-Thought Spatial Reasoning이라고 부른다. 합성된 데이터에는 direct spatial reasoning 문제만 포함되어 있지만 VLM이 이를 합성하여 multi-hop chain-of-thought 추론이 필요한 복잡한 문제를 해결하는 것은 쉽다. 저자들은 LLM(text-davinci-003)을 활용하여 SpatialVLM과 통신하여 chain-of-thought 프롬프트로 복잡한 문제를 해결하였다. LLM은 복잡한 질문을 간단한 질문으로 분해하고 VLM에 쿼리를 보내고 추론을 함께 모아 결과를 도출할 수 있다.
4. 실험
1. Spatial VQA performance
다음은 공간 관계에 대한 (위) 정성적 질문과 (아래) 정량적 질문에서 다른 VLM들과 정확도를 비교한 표이다.


2. Ablation Studies
다음은 공간 추론 데이터셋의 유무에 따른 성능을 비교한 표이다.

다음은 사전 학습된 ViT의 고정 유무에 따른 성능을 비교한 표이다.

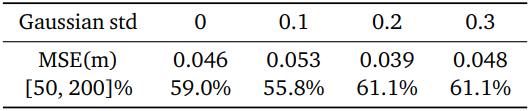
다음은 데이터의 노이즈 수준에 따른 성능을 비교한 표이다.
3. Spatial Reasoning Unlocks Novel Applications
다음은 로봇 그리퍼가 콜라 캔에 접근하는 일련의 이미지가 주어졌을 때, “노란색 그리퍼와 콜라 캔 사이의 거리는 얼마인가”라는 질문에 대한 SpatialVLM의 답변을 실제 거리와 비교한 결과이다.

다음은 로봇 task를 위해 SpatialVLM을 reward generator로 사용한 예시이다.

5. 주요 기여
세계 최대 규모의 3D 공간적 질문-응답(VQA) 데이터셋 구축.
정량적(quantitative) 공간 추론이 가능한 VLM 모델 개발.
로봇공학 및 체인 오브 쏘트(Chain-of-Thought) 공간 추론 응용 가능성 제시.
6. 결론 및 향후 연구 방향
본 연구는 비전-언어 모델(VLMs)이 3D 공간적 정보를 학습하여 더 강력한 공간 추론 능력을 가질 수 있음을 입증했습니다.
특히, 로봇공학 및 체인 오브 쏘트 기반의 공간적 추론 응용 가능성을 강조하며, 미래 연구에서는 더 정교한 데이터셋 및 모델 개선을 통해 공간 추론 능력을 더욱 향상시킬 수 있을 것으로 보입니다.
