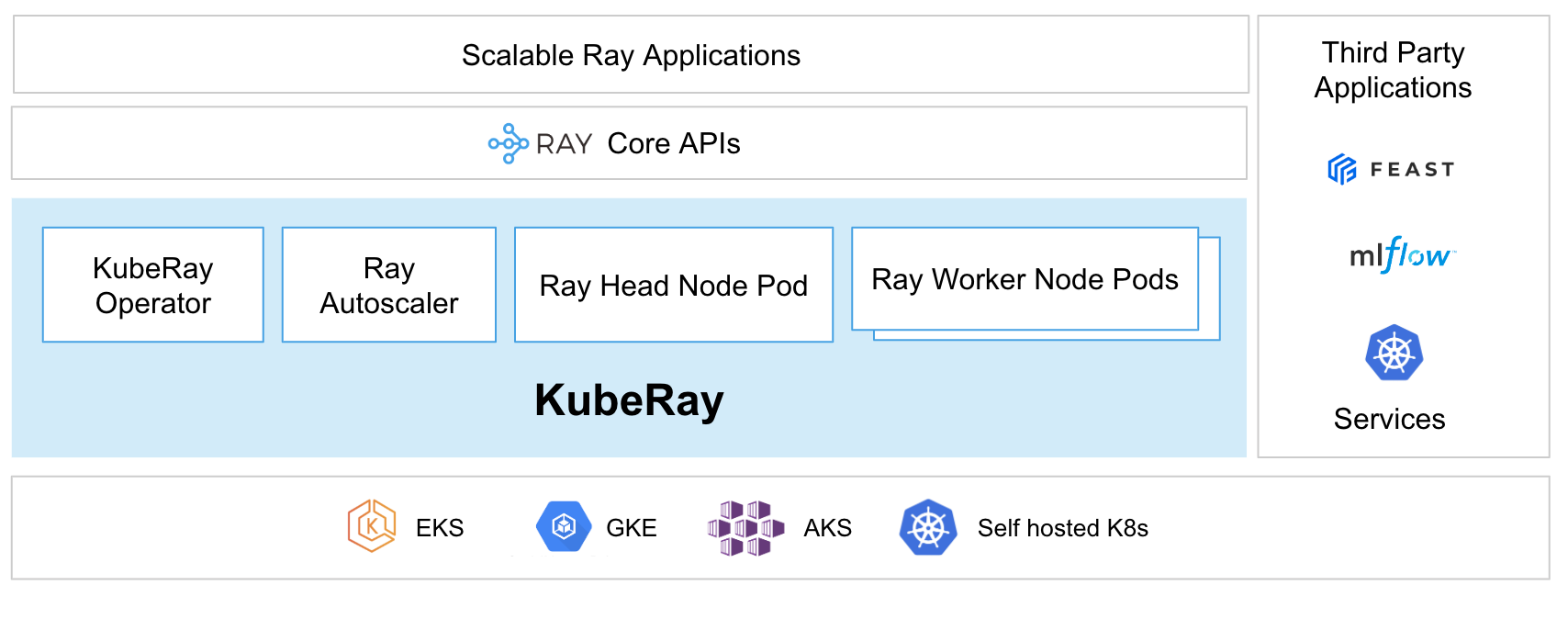
Ray Kubernetes 클러스터 개요
Ray는 분산 컴퓨팅을 위한 Python 프레임워크이며, Kubernetes 환경에서 실행할 수 있습니다. Kubernetes에서 Ray를 실행하는 것은 확장성, 리소스 관리, 운영상의 이점을 제공합니다.
주요 구성 요소
1. Ray Cluster 구조
- Head Node: 클러스터의 중앙 조정자 역할, 스케줄링과 메타데이터 관리 담당
- Worker Nodes: 실제 작업을 수행하는 노드들
- Ray Dashboard: 클러스터 상태 모니터링을 위한 웹 UI
2. Kubernetes 리소스
- RayCluster CRD (Custom Resource Definition): Ray 클러스터를 정의하는 Kubernetes 사용자 정의 리소스
- RayService: Ray 애플리케이션을 서비스로 배포
- RayJob: 배치 작업을 실행하기 위한 리소스
배포 방법
1. KubeRay Operator 설치
# KubeRay operator 설치
kubectl create -k "github.com/ray-project/kuberay/ray-operator/config/default"2. RayCluster 매니페스트 예시
apiVersion: ray.io/v1alpha1
kind: RayCluster
metadata:
name: my-ray-cluster
spec:
rayVersion: '2.8.0'
headGroupSpec:
replicas: 1
rayStartParams:
dashboard-host: '0.0.0.0'
template:
spec:
containers:
- name: ray-head
image: rayproject/ray:2.8.0
resources:
limits:
cpu: 2
memory: 4Gi
workerGroupSpecs:
- replicas: 2
minReplicas: 1
maxReplicas: 5
groupName: worker-group
template:
spec:
containers:
- name: ray-worker
image: rayproject/ray:2.8.0
resources:
limits:
cpu: 4
memory: 8Gi주요 특징
1. 자동 스케일링
- Kubernetes HPA(Horizontal Pod Autoscaler)와 통합
- 워크로드에 따른 동적 노드 추가/제거
- 비용 효율적인 리소스 사용
2. 고가용성
- Head 노드 장애 시 자동 복구
- 워커 노드 장애 시 작업 재분배
- Persistent Volume을 통한 상태 보존
3. 네트워킹
- Service를 통한 클러스터 내부 통신
- Ingress를 통한 외부 접근 제어
- Ray Dashboard 접근을 위한 포트 포워딩
사용 사례
1. 머신러닝 워크로드
- 분산 훈련 (Ray Train)
- 하이퍼파라미터 튜닝 (Ray Tune)
- 강화학습 (Ray RLlib)
- 모델 서빙 (Ray Serve)
2. 데이터 처리
- 대규모 데이터 전처리
- ETL 파이프라인
- 실시간 스트림 처리
3. 일반적인 분산 컴퓨팅
- 병렬 시뮬레이션
- 배치 처리 작업
- 과학 계산
모니터링 및 관리
1. Ray Dashboard
- 클러스터 상태 실시간 모니터링
- 작업 실행 현황 추적
- 리소스 사용률 확인
2. Kubernetes 네이티브 도구
- kubectl을 통한 클러스터 관리
- Prometheus/Grafana를 통한 메트릭 수집
- 로그 수집 및 분석
3. 디버깅
- Pod 로그를 통한 문제 진단
- Ray 내장 프로파일링 도구 활용
- 분산 추적을 통한 성능 분석
모범 사례
1. 리소스 관리
- 적절한 CPU/메모리 제한 설정
- 노드 선택기를 통한 워크로드 배치
- 우선순위 클래스 활용
2. 보안
- RBAC를 통한 접근 제어
- Network Policy를 통한 네트워크 격리
- 시크릿을 통한 민감 정보 관리
3. 성능 최적화
- 적절한 배치 사이즈 설정
- 메모리 효율적인 데이터 처리
- 네트워크 대역폭 고려
Ray on Kubernetes는 복잡한 분산 워크로드를 간단하고 확장 가능한 방식으로 실행할 수 있게 해주는 강력한 플랫폼입니다. 특히 머신러닝과 데이터 처리 영역에서 매우 유용합니다.
더 구체적인 설정이나 사용 사례에 대해 궁금한 점이 있으시면 언제든 물어보세요!

따라가기도 벅찬 AI Engineer 겸 부앙단