TweetMaker - Building a Multimodal Metric Learning and Similarity for Tweet Image Recommendation
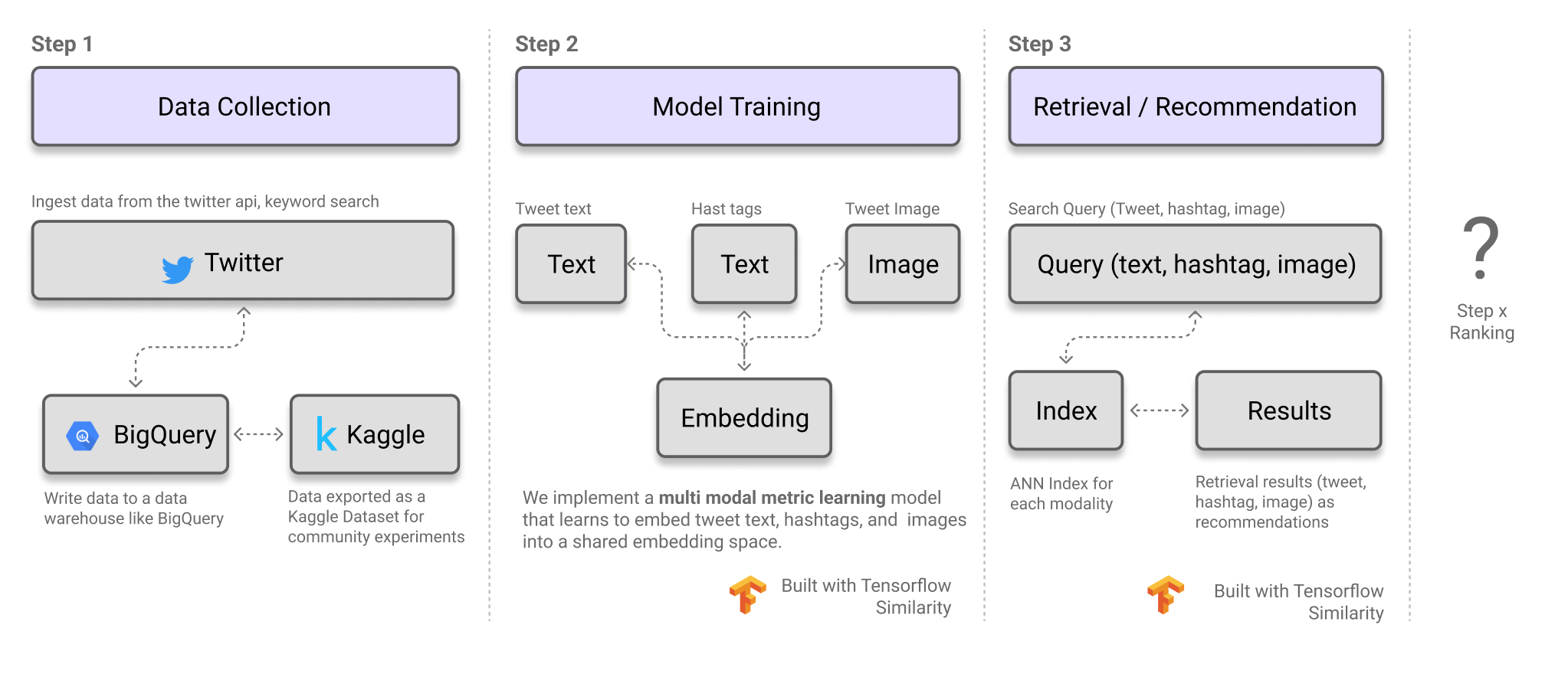
이번 포스트에서는 TweetMaker라는 가상의 사용 사례를 살펴보겠습니다. TweetMaker는 트윗을 더욱 흥미롭게 만들 수 있도록 이미지, 해시태그 또는 텍스트를 추천하는 도구입니다! 이 프로젝트는 크게 세 가지 주요 부분으로 구성됩니다.
-
Data Collection:
이 모델을 학습시키는 데 사용된 데이터는 트윗의 텍스트, 연관된 이미지, 해시태그 및 일반적인 메타데이터를 포함합니다. 이 목적을 위해 예제 데이터셋이 이미 준비되었으며, Kaggle 데이터셋 AI Tweets로 노트북과 함께 제공됩니다. -
Model Training:
여기에서는 두 가지 모달리티(텍스트 및 이미지)를 활용하여 데이터를 추천하고자 합니다. 즉, 트윗 텍스트와 해시태그(텍스트 모달리티) 및 트윗 이미지(이미지 모달리티)를 기반으로 추천을 수행합니다. 이를 위해, 어떤 모달리티의 콘텐츠든 공통된 임베딩 공간으로 변환할 수 있도록 학습하는 multimodal metric learning model(멀티모달 메트릭 학습 모델)을 훈련할 것입니다. -
Retrieval / Recommendation:
훈련된 모델이 준비되면, 다음 단계로는 데이터베이스 내에서 특정 모달리티의 쿼리에 대한 유사한 데이터를 빠르게 검색할 수 있는 인프라를 구축하는 것입니다. 예를 들어, 트윗 데이터셋을 기반으로 해시태그, 트윗 텍스트, 트윗 이미지 각각에 대한 인덱스를 생성합니다. 그런 다음, 쿼리(이미지, 해시태그 또는 텍스트)가 주어지면 이를 임베딩 공간으로 변환한 후, 빠른 근사 최근접 이웃 검색(Approximate Nearest Neighbor Search, ANN) 을 수행하여 관련 있는 이미지, 해시태그 또는 텍스트를 추천합니다.
위의 워크플로우를 통해 사용자가 트윗을 작성할 때 콘텐츠를 추천할 수 있지만, 결과를 더욱 개선할 여지는 여전히 있습니다. 예를 들어, 최신성, 참여도 등의 지표를 기준으로 검색된 결과를 재정렬하거나, 추천 파이프라인의 추가 단계로 학습-순위 모델(learning-to-rank models)을 구축할 수도 있습니다.
TensorFlow Similarity
그렇다면 위에서 설명한 모든 흥미로운 단계를 어떻게 구현할까요? 바로 TensorFlow Similarity 라이브러리가 도움을 줍니다. 물론, 이러한 단계들은 다른 도구를 사용하여 구현할 수도 있지만, TensorFlow Similarity는 다음과 같은 이유로 이를 훨씬 더 쉽게 만들어 줍니다.
-
메트릭 학습 모델 추상화:
TensorFlow Similarity는 자기 지도 학습(self-supervised learning), 메트릭 학습(metric learning), 유사성 학습(similarity learning) 및 대조 학습(contrastive learning) 등의 유사성 학습 기법을 쉽게 사용할 수 있는 API를 제공합니다. 여기에서는 TFSimilarity의 SimilarityModel 추상화를 사용하여 멀티모달 메트릭 학습 모델을 구축할 것입니다. -
메트릭 학습 손실 함수:
TensorFlow Similarity는 유사성 학습 과제에 유용한 다양한 손실 함수(loss function)를 제공하여 모델 학습을 최적화할 수 있도록 합니다. -
인덱싱 및 검색:
TensorFlow Similarity는 Indexer 클래스를 구현하여 임베딩과 메타데이터를 함께 인덱싱할 수 있도록 합니다. 또한, Matcher를 제공하여 빠른 근사 최근접 이웃 검색(ANN, Approximate Nearest Neighbor Search) 을 수행할 수 있습니다. lookup() 및 single_lookup() 함수를 통해 제공된 임베딩과 가장 유사한 인덱싱된 요소를 빠르게 검색할 수 있습니다.
Code
이 작업은 [Multimodal 예제]를 기반으로 구축되었습니다(https://github.com/tensorflow/similarity/blob/master/examples/multimodal_example.ipynb)
import os
#INFO, WARNING messages are not printed.
os.environ["TF_CPP_MIN_LOG_LEVEL"] = "3"
import gc
import textwrap
import numpy as np
import pandas as pd
from tqdm import tqdm
from matplotlib import pyplot as plt
from IPython.display import display, Image
import tensorflow as tf
from sklearn.model_selection import train_test_split
import matplotlib.image as mpimg이제 필요한 의존성을 설치하고, 이후에 사용할 유틸리티 함수들을 설정하겠습니다.
TensorFlow Similarity v0.17을 사용하고 있지만, 최신 버전과 새로운 기능을 확인하려면 공식 TensorFlow Similarity 저장소를 참고하는 것이 좋습니다.
또한, 검색 후 리콜(Recall) 지표를 쉽게 계산할 수 있도록 recall_at_k 같은 함수를 정의할 것입니다. 이를 통해 검색된 상위 K개의 결과에서 올바른 항목이 얼마나 포함되어 있는지를 평가할 수 있습니다.
!pip install -q git+https://github.com/tensorflow/similarity.git@master
!pip install -q transformers --upgrade from transformers import TFCLIPTextModel, TFCLIPVisionModel, CLIPTokenizer, TFCLIPModel
import tensorflow_similarity as tfsim # main package
from transformers import logging as hf_logging
hf_logging.set_verbosity_error()
tfsim.utils.tf_cap_memory()
# Clear out any old model state.
gc.collect()
tf.keras.backend.clear_session()
# We need TF Similarity 0.17+
print("TensorFlow:", tf.__version__)
print("TensorFlow Similarity", tfsim.__version__)
N_CPU = os.cpu_count()
IMG_SIZE = 224
BATCH_SIZE = 32
COLOR_CHANNELS = 3
N_TOKENS = 77
DATA_DIR = "multi_modal_datasets"
LATENT_SIZE = 512
model_name = 'openai/clip-vit-base-patch32'
MAX_SEQ_LENGTH = 128
# define function to load data image from path to vector.
def get_img_emb(image_path):
image = tf.io.read_file("../input/aitweets/images/images/" + image_path)
image = tf.image.decode_jpeg(image, channels=3)
image = tf.image.convert_image_dtype(image, tf.float32)
image = tf.image.resize(image, [IMG_SIZE, IMG_SIZE], method="nearest")
image = tf.transpose(image, [2, 0, 1]) # Channels first
return image
# Define a function for recall metrics
def recall_at_k(sim_matrix, k=1):
"""
It is the mean of ratio of correctly retrieved documents
to the number of relevant documents.
This implementation is specific to
data having unique label for each key
"""
sorted_mat = np.argsort(sim_matrix, axis=1)[:, -k:]
# Each key has unique label
true_labels = np.arange(sorted_mat.shape[0]).reshape(-1, 1)
true_labels = np.repeat(true_labels, k, axis=1)
sorted_mat = sorted_mat - true_labels
# the position in row corresponding to true positive
# will be zero
tps = np.any(sorted_mat == 0, axis=1)
return tps.mean()Data Collection - Loading The AI Tweets Dataset
이번 프로젝트에서 사용할 데이터셋은 Kaggle에 공개된 AI Tweets 데이터셋(aitweets) 입니다. 이 데이터셋은 코드에 첨부되어 있으며, 코드가 실행될 때 자동으로 다운로드됩니다.
데이터 로딩 과정
데이터 로딩은 다음 단계로 진행됩니다:
- 훈련(train) 및 검증(validation) 데이터프레임을 로드합니다.
- TensorFlow Dataset (TF.data) 로더를 작성하여 효율적인 학습을 지원합니다. 모델은 Kaggle의 P100 GPU 및 13GB RAM을 가진 CPU에서 학습될 예정입니다. 모든 데이터를 메모리에 한 번에 로드할 수 없으므로, tf.data를 활용하여 데이터를 디스크에서 필요할 때마다 로드(just-in-time loading) 하는 방식을 사용합니다. tf.data의 .cache() 메서드는 사용하지 않습니다. .cache()를 사용하면 데이터가 메모리에 저장되지만, 이는 메모리 부족(Out of Memory, OOM) 오류를 초래할 수 있기 때문입니다.
train_df = pd.read_csv("../input/aitweets/train.csv")
val_df = pd.read_csv("../input/aitweets/test.csv")
print("Train:", len(train_df), " Test:", len(val_df))
train_df.fillna(' ', inplace=True)
val_df.fillna(' ', inplace=True)
train_df.head(3) train_images = train_df["image_id"].to_list()
val_images = val_df["image_id"].to_list()
train_texts = train_df["text"].to_list()
val_texts = val_df["text"].to_list()
train_hashtags = train_df["hashtags"].to_list()
val_hashtags = val_df["hashtags"].to_list()
tokenizer = CLIPTokenizer.from_pretrained(model_name)
def get_tokens(texts):
return tokenizer( texts, padding="max_length", return_tensors="tf", truncation=True)
train_text_tokens = get_tokens(train_texts)
val_text_tokens = get_tokens(val_texts)
train_hashtag_tokens = get_tokens(train_hashtags)
val_hashtag_tokens = get_tokens(val_hashtags)def data_mapper(img, text_input_ids, text_attention_mask, hashtag_input_ids, hasttag_attention_mask):
return get_img_emb(img), tf.squeeze(text_input_ids), tf.squeeze(text_attention_mask), tf.squeeze(hashtag_input_ids), tf.squeeze(hasttag_attention_mask)
train_ds = (
tf.data.Dataset.from_tensor_slices((train_images, train_text_tokens["input_ids"], train_text_tokens["attention_mask"], train_hashtag_tokens["input_ids"], train_hashtag_tokens["attention_mask"]))
.shuffle(1000)
.map(data_mapper, num_parallel_calls=tf.data.AUTOTUNE)
.batch(BATCH_SIZE)
.prefetch(tf.data.AUTOTUNE)
)
val_ds = (
tf.data.Dataset.from_tensor_slices((val_images, val_text_tokens["input_ids"], val_text_tokens["attention_mask"], val_hashtag_tokens["input_ids"], val_hashtag_tokens["attention_mask"]))
.map(data_mapper, num_parallel_calls=N_CPU)
.batch(BATCH_SIZE)
)
print("Train Dataset Shapes")
for i in train_ds.take(1):
print(len(i))
for nm, tensor in zip(["Image", "Text Input Id", "Text Attention Mask", "HashTag Input Id", "HashTag Attention Mask"], i):
print(f"{nm}: {tensor.shape}")
# print("\n")
# print("Val Dataset Shapes")
# for i in val_ds.take(1):
# for nm, tensor in zip(["Image", "Input Id", "Attention Mask"], i):
# print(f"{nm}: {tensor.shape}")Model Building - CLIP Text and Image Models
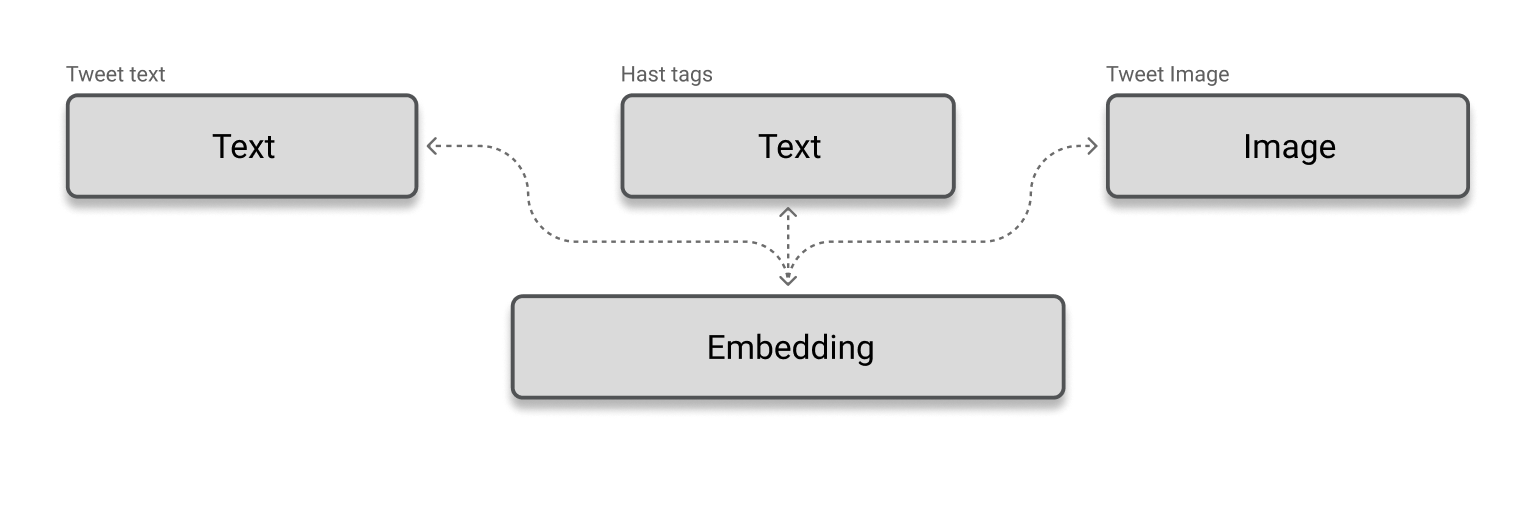
이 섹션에서는 CLIP (Contrastive Language-Image Pretraining) 을 활용하여 검색(Retrieval) 을 위한 멀티모달 메트릭 학습 모델을 구축하고 훈련합니다.
CLIP - Overview and Advantages
CLIP (Contrastive Language-Image Pre-Training) 은 OpenAI에서 2021년에 개발한 최신 신경망 모델로, 텍스트와 이미지 간의 관계를 이해하도록 설계되었습니다.
CLIP은 다음과 같은 다양한 작업에서 뛰어난 성능을 발휘합니다.
✅ 이미지 분류(Image Classification)
✅ 객체 탐지(Object Detection)
✅ 자연어 처리(Natural Language Processing, NLP)
CLIP의 특징 및 장점
대규모 이미지-캡션 데이터셋을 사용하여 사전 학습되었으며, 단어 및 구문을 특정 시각적 개념과 연결할 수 있습니다. 텍스트와 이미지를 공통된 임베딩 공간에 매핑하여, 이미지 캡셔닝(Image Captioning), 시각적 질의 응답(Visual Question Answering, VQA) 같은 작업에 매우 효과적입니다. 가장 큰 강점은 새로운 작업 및 도메인에 추가 학습 없이도 강력한 일반화 능력을 발휘한다는 점입니다.
model = TFCLIPModel.from_pretrained("openai/clip-vit-base-patch32")
vision_weights = tf.Variable(model.weights[-2])
text_weights = tf.Variable(model.weights[-1])
del model
# Clear the Keras backend now that we deleted the original model.
tf.keras.backend.clear_session()CLIP_text_model = TFCLIPTextModel.from_pretrained(
"openai/clip-vit-base-patch32",
)
CLIP_vision_model = TFCLIPVisionModel.from_pretrained(
"openai/clip-vit-base-patch32",
)
def get_image_model(n_dims=512):
x = inputs = tf.keras.layers.Input((COLOR_CHANNELS, IMG_SIZE, IMG_SIZE), name="image")
x = CLIP_vision_model(x).pooler_output # pooled CLS states
kernel_weights = tf.constant_initializer(vision_weights.numpy())
# Projection layer
embed = tf.keras.layers.Dense(n_dims, name="image_embedding", kernel_initializer=kernel_weights)(x)
model = tf.keras.models.Model(inputs=inputs, outputs=embed, name="image_model")
return model
def get_text_model(n_dims=512, model_name="text_model"):
inputs1 = tf.keras.layers.Input((N_TOKENS), dtype=tf.int32, name="input_ids")
inputs2 = tf.keras.layers.Input((N_TOKENS), dtype=tf.int32, name="attention_mask")
x = CLIP_text_model(input_ids=inputs1, attention_mask=inputs2).pooler_output # pooled CLS states
kernel_weights = tf.constant_initializer(text_weights.numpy())
# Projection layer
embed = tf.keras.layers.Dense(n_dims, name="text_embedding", kernel_initializer=kernel_weights)(x)
model = tf.keras.models.Model(inputs=[inputs1, inputs2], outputs=embed, name=model_name)
return model
img_model = get_image_model()
text_model = get_text_model(model_name="text_model")
hashtag_model = get_text_model(model_name="hashtag_model")Model Training Loop
Metric Learning Loss Function
Tensorflow Similarity 라이브러리의 tfsim.losses.MultiNegativesRankLoss() 손실 함수를 사용할 것입니다. 현재 데이터셋에는 긍정(positive) 예제만 존재하므로, 이 경우 다중 부정(negative) 순위 손실이 적합한 선택입니다. 이 손실 함수는 (xi, yi) 쌍을 제외한 모든 쌍을 부정 쌍으로 간주합니다.
loss_fn = tfsim.losses.MultiNegativesRankLoss()
val_loss = 0
base_image_embeddings = []
base_text_embeddings = []
for image_batch, text_input_ids_batch, text_attention_mask_batch, hashtag_input_ids_batch, hashtag_attention_mask_batch in tqdm(val_ds):
image_embedding = img_model(image_batch, training=False)
text_embedding = text_model([text_input_ids_batch, text_attention_mask_batch], training=False)
hashtag_embedding = hashtag_model([hashtag_input_ids_batch, hashtag_attention_mask_batch], training=False)
image_embedding = tf.math.l2_normalize(image_embedding, axis=1)
text_embedding = tf.math.l2_normalize(text_embedding, axis=1)
hashtag_embedding = tf.math.l2_normalize(hashtag_embedding, axis=1)
base_image_embeddings.append(image_embedding.numpy())
base_text_embeddings.append(text_embedding.numpy())
# Compute the loss value for this minibatch.
loss_value = loss_fn([text_embedding, hashtag_embedding], image_embedding)
val_loss += float(loss_value)
print(f"Mean Validation Loss before model finetuning : {val_loss / len(val_ds)}")
base_image_embeddings = np.concatenate(base_image_embeddings)
base_text_embeddings = np.concatenate(base_text_embeddings)base_sim_mat = np.matmul(base_text_embeddings, base_image_embeddings.T)
for k in tqdm([1,10,50,100]):
print("R@{}: {}".format(k, recall_at_k(base_sim_mat, k)))
gc.collect() Custom Training Loop
다음은 각 단계에서 수행되는 작업을 설명하는 커스텀 케라스 트레이닝 루프에 대한 설명입니다:
- 순전파(forward pass): 이미지 및 텍스트 모델을 통해 임베딩을 추출합니다.
- L2 정규화: 임베딩을 L2 정규화하여 임베딩의 길이가 1이 되고 단위 구의 표면에 위치하게 하여 코사인 유사도를 사용해 비교하기 쉽게 만듭니다.
- 손실 계산: tfsim.losses.MultiNegativesRankLoss() 손실 함수를 사용하여 손실을 계산합니다.
- 기울기 계산: GradientTape 객체를 사용해 모델의 학습 가능한 가중치에 대한 손실의 기울기를 계산합니다.
- 가중치 업데이트: 옵티마이저를 사용하여 손실을 최소화하도록 모델의 가중치를 업데이트합니다.
epochs = 4
lr_schedule = tf.keras.optimizers.schedules.ExponentialDecay(
initial_learning_rate=1e-5,
decay_steps=100,
decay_rate=0.7)
img_optimizer = tf.keras.optimizers.Adam(learning_rate=lr_schedule)
text_optimizer = tf.keras.optimizers.Adam(learning_rate=lr_schedule)
hashtag_optimizer = tf.keras.optimizers.Adam(learning_rate=lr_schedule)
train_step_losses = []
train_epoch_losses = []
@tf.function
def train_step(image_batch, text_batch, hastag_batch):
with tf.GradientTape() as img_tape, tf.GradientTape() as text_tape, tf.GradientTape() as hashtag_tape:
image_embedding = img_model(image_batch, training=True)
text_embedding = text_model(text_batch, training=True)
hashtag_embedding = hashtag_model(hastag_batch,training=True )
image_embedding = tf.math.l2_normalize(image_embedding, axis=1)
text_embedding = tf.math.l2_normalize(text_embedding, axis=1)
hashtag_embedding = tf.math.l2_normalize(hashtag_embedding, axis=1)
# Compute the loss value for this minibatch.
loss_value = loss_fn([text_embedding, hashtag_embedding], image_embedding)
text_loss = loss_fn(text_embedding, image_embedding)
hashtag_loss= loss_fn(hashtag_embedding, image_embedding)
img_grads = img_tape.gradient(loss_value, img_model.trainable_weights)
text_grads = text_tape.gradient(text_loss, text_model.trainable_weights)
hashtag_grads = hashtag_tape.gradient(hashtag_loss, hashtag_model.trainable_weights)
# Run one step of gradient descent by updating
# the value of the variables to minimize the loss.
img_optimizer.apply_gradients(zip(img_grads, img_model.trainable_weights))
text_optimizer.apply_gradients(zip(text_grads, text_model.trainable_weights))
hashtag_optimizer.apply_gradients(zip(hashtag_grads, hashtag_model.trainable_weights))
return loss_value
# Custom Training Loop
for epoch in range(epochs):
print(f"\nEpoch {epoch + 1}")
epoch_loss = 0
# Iterate over the batches of the dataset.
for step, (image_batch, text_input_ids_batch, text_attention_mask_batch,hashtag_input_ids_batch, hashtag_attention_mask_batch) in enumerate(train_ds):
loss_value = train_step(image_batch, [text_input_ids_batch, text_attention_mask_batch],[hashtag_input_ids_batch,hashtag_attention_mask_batch ])
epoch_loss += float(loss_value)
train_step_losses.append(float(loss_value) / image_batch.shape[0])
# Log every batch
if step % 200 == 0:
print(f"Training loss (for one batch) at step {step + 1}: {float(loss_value):.4f}")
print("Seen so far: %s samples" % ((step + 1) * BATCH_SIZE))
print(f"Epoch loss: {epoch_loss / len(train_ds)}")
train_epoch_losses.append(epoch_loss / len(train_ds))fig, axs = plt.subplots(1, 2, figsize=(10, 5))
# Plot the epoch losses on the left subplot
axs[0].plot(train_epoch_losses)
axs[0].set_title("Training Loss per Epoch")
axs[0].set_xlabel("Epoch")
axs[0].set_ylabel("Loss")
# Plot the step losses on the right subplot
axs[1].plot(train_step_losses)
axs[1].set_title("Training Loss per Step")
axs[1].set_xlabel("Steps")
axs[1].set_ylabel("Loss")
# Show the plot
plt.show() 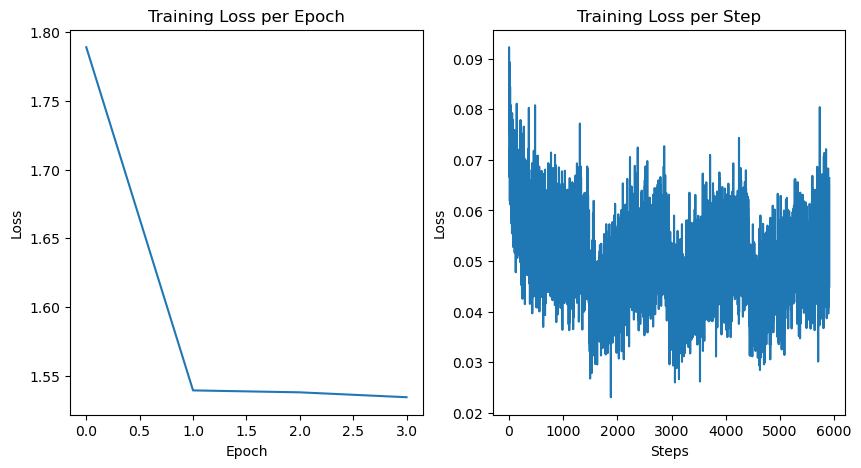
이제 파인튜닝 후 검증 데이터에 대한 성능을 확인해봅시다.
val_loss = 0
image_embeddings = []
text_embeddings = []
for image_batch, text_input_ids_batch, text_attention_mask_batch, hashtag_input_ids_batch, hashtag_attention_mask_batch in tqdm(val_ds):
image_embedding = img_model(image_batch, training=False)
text_embedding = text_model([text_input_ids_batch, text_attention_mask_batch], training=False)
hashtag_embedding = hashtag_model([hashtag_input_ids_batch, hashtag_attention_mask_batch], training=False)
image_embedding = tf.math.l2_normalize(image_embedding, axis=1)
text_embedding = tf.math.l2_normalize(text_embedding, axis=1)
hashtag_embedding = tf.math.l2_normalize(hashtag_embedding, axis=1)
image_embeddings.append(image_embedding.numpy())
text_embeddings.append(text_embedding.numpy())
# Compute the loss value for this minibatch.
loss_value = loss_fn([text_embedding, hashtag_embedding], image_embedding)
val_loss += float(loss_value)
print(f"Mean Validation Loss: {val_loss / len(val_ds)}")
image_embeddings = np.concatenate(image_embeddings)
text_embeddings = np.concatenate(text_embeddings)finetuned_sim = np.matmul(text_embeddings, image_embeddings.T)
for k in tqdm([1,10,50,100]):
print("R@{} : {}".format(k, recall_at_k(finetuned_sim, k)))Indexing and Retrieval Using TF Similarity
이제 표현을 생성할 수 있는 모델을 갖추었으므로, 다음 작업은 데이터의 표현 인덱스를 구축하고 이 인덱스에서 검색/회수를 수행하는 것입니다. TFSimilarity는 이 과정을 쉽게 만들어줍니다.
- 이미지 인덱스 생성
- 데이터셋 인덱싱
- 검색 쿼리 실행 및 결과 회수
imgs_list = val_df["image_id"].to_list()
text_list = val_df["text"].to_list()
image_index = tfsim.models.SimilarityModel(img_model.inputs, img_model.outputs)
brute_force_search = tfsim.search.NMSLibSearch(
distance='cosine',
method='brute_force',
dim=img_model.output_shape[1]
)
image_index.create_index(search=brute_force_search)# #index in batches to avoid memory allocation issues in the .predict part of .index. This results in mostly silent OOM error.
index_batch = 1000
n = len(imgs_list)
batches = (n + index_batch - 1) // index_batch
for batch in tqdm(range(batches)):
start = batch * index_batch
end = min((batch + 1) * index_batch, n)
imgs = tf.convert_to_tensor(np.array([get_img_emb(fp) for fp in imgs_list[start:end]]))
image_index.index(imgs, data=[{"imgs": i, "desc": d} for i, d in zip(imgs_list[start:end], text_list[start:end])], verbose=0)def search(model, query, k=4):
query_tokens = tokenizer(
[query],
padding="max_length",
return_tensors="tf",
truncation=True,
)
q_input_ids = tf.convert_to_tensor(np.array(query_tokens["input_ids"]))
q_attention_mask = tf.convert_to_tensor(np.array(query_tokens["attention_mask"]))
query_emb = model.predict([q_input_ids, q_attention_mask])
lookups = image_index._index.batch_lookup(predictions=query_emb, k=k, verbose=0)[0]
n_images = len(lookups)
n_columns = 2
n_rows = (n_images + n_columns - 1) // n_columns
fig, axs = plt.subplots(n_rows, n_columns, figsize=(15, n_rows * 5))
fig.suptitle(f'Query : {query} Images', fontsize=20, y=1.02)
for i, lookup in enumerate(lookups):
matching_img = mpimg.imread("../input/aitweets/images/images/" + lookup.data["imgs"])
matching_desc = lookup.data["desc"]
row, col = i // n_columns, i % n_columns
axs[row, col].imshow(matching_img)
axs[row, col].set_title('\n'.join(textwrap.wrap(matching_desc, width=70)), fontsize=10)
axs[row, col].axis('off')
# Hide empty subplots
for i in range(n_images, n_rows * n_columns):
row, col = i // n_columns, i % n_columns
axs[row, col].axis('off')
# Adjust layout to avoid overlapping titles
plt.tight_layout()
plt.show()
return lookupssearch_query = "Langchain for AI"
lookups = search(text_model, search_query, k=4)
img_model.save("image_model.h5")
text_model.save("text_model.h5")
hashtag_model.save("hastag_model.h5")Conclusion / Next Steps
이번 포스트에서는 CLIP 모델을 기반으로 하는 다중 모달(metric learning) 모델을 구축하여, 주어진 텍스트에 따라 트윗 데이터셋에서 관련 이미지를 검색할 수 있는 방법을 살펴보았습니다. 이 자체만으로도 작성자들이 트윗의 참여도를 향상시키는 데 큰 도움이 될 수 있습니다. 테스트 셋에서 파인튜닝 전후의 손실 값과 검색 정확도(3 에포크 후 r@100이 27%에서 57%로 향상됨)를 통해 모델 학습 과정의 효과를 확인할 수 있습니다.
Next Steps
-
결과 순위 재정렬을 통한 품질 개선
검색된 결과를 재정렬함으로써 시스템의 성능을 더욱 개선할 수 있는 여러 방법이 있습니다. 예를 들어, 최신성, 참여도(좋아요, 리트윗 등)와 같은 기준에 따라 결과를 재배열할 수 있으며, 이러한 기준을 최대화하도록 검색 결과의 순위를 재조정하는 TF Ranking 등의 커스텀 모델을 학습시킬 수도 있습니다. -
모델 배포
학습된 모델을 API로 배포하고, 사용자들이 참여도 높은 트윗을 작성할 수 있도록 돕는 프론트엔드 사용자 경험을 구축하는 방법을 모색할 수 있습니다.
