https://mlsysbook.ai/contents/core/frameworks/frameworks.html

6.1 Overview
Overview에서는 AI 프레임워크(Framework)가 왜 중요한지, 어떤 역할을 하는지를 다룹니다. 특히 대규모 머신러닝(ML) 및 심층학습(DL) 환경에서 프레임워크가 제공하는 기본적 동작 원리, 시스템 수준에서의 구성 요소, 그리고 이러한 프레임워크가 사용자와 하드웨어 사이에서 어떤 식으로 추상화 계층을 형성하는지를 상세히 설명합니다. 궁극적으로, 프레임워크는 연구자, 개발자, 엔지니어에게 효율적이고 일관된 개발 환경을 제공하며, 모델 구축, 교육, 추론 과정을 단순화하고 최적화하는 중요한 도구임을 강조합니다.
- 프레임워크의 등장 배경과 필요성:
-
초기 머신러닝 개발에서는 모델 작성과 학습 과정에 있어 수많은 반복적이고 수동적인 작업이 필수적이었습니다.
-
데이터 전처리, 모델 정의, 파라미터 초기화, 역전파(backpropagation) 구현, GPU/CPU 자원 관리 등 많은 로우 레벨(low-level) 작업이 필요했기에 생산성과 재사용성이 낮았습니다.
-
이러한 문제를 해결하고자 프레임워크가 등장하였고, 이를 통해 개발자는 하위 계층의 복잡한 구현 세부사항에서 벗어나 고급 추상화로 작업이 가능해졌습니다.
- 프레임워크의 역할과 추상화 계층:
-
프레임워크는 추상화 레이어를 제공합니다. 예를 들어, TensorFlow, PyTorch와 같은 딥러닝 프레임워크는 자동 미분(automatic differentiation), 계산 그래프 관리, 효율적인 텐서 연산 등의 기능을 내장하고 있습니다. 개발자는 이 기능들을 사용하여 마치 수학 수식으로 모델을 정의하듯 직관적으로 코드를 작성할 수 있습니다.
-
이러한 추상화를 통해 개발자는 하드웨어별 최적화(GPU, TPU, CPU SIMD 명령어, 메모리 관리 등) 세부사항을 직접 다루지 않고도 높은 성능을 낼 수 있습니다. 즉, 프레임워크는 사용자와 하드웨어 사이를 매개하는 계층 역할을 하며, 내부적으로 다양한 최적화 기술을 활용해 최종적인 계산 효율을 극대화합니다.
- 일관성 있는 인터페이스 제공:
-
프레임워크는 모델 구축부터 학습, 평가, 추론에 이르기까지 일관성 있는 인터페이스를 제공합니다. 이는 팀 단위 협업과 코드 재사용성을 극대화하는 데 기여합니다.
-
예를 들어, PyTorch나 TensorFlow에서는 텐서(Tensor)라는 공통 데이터 구조를 기반으로 다양한 연산을 일관된 방식으로 지원합니다. 이를 통해 사용자들은 새로운 연산이나 새로운 모델 구조를 쉽게 도입할 수 있고, 다른 사람들의 코드나 라이브러리를 보다 쉽게 통합할 수 있습니다.
- 수평적·수직적 확장성:
-
현대의 머신러닝 작업은 단일 GPU나 단일 머신을 넘어 수많은 노드와 디바이스로 확장됩니다(분산 학습, 클러스터 환경). 프레임워크는 이러한 분산 환경을 지원하는 기능을 갖추고 있습니다.
-
또한, 가속기 종류(GPU, TPU, ASIC 등)에 상관없이 공통 API를 통한 추상화를 지원하여, 코드의 재작성 없이도 다양한 하드웨어 백엔드로 쉽게 전환할 수 있게 합니다. 이를 통해 연구에서 프로덕션 환경으로의 이행이 용이해집니다.
- 자동화와 최적화:
-
프레임워크는 자동 미분과 같은 기능을 통해, 역전파 계산을 사람이 직접 구현하지 않아도 모델 학습이 가능하도록 합니다. 이는 연구 단계에서 모델 디자인에만 집중할 수 있는 환경을 제공하여 생산성을 높입니다.
-
내부적으로 효율적인 커널 실행, 연산 그래프 최적화, 메모리 사용 최적화 등을 통해 성능 최적화를 자동으로 수행합니다. 이는 사용자가 저수준의 세부사항에 신경 쓰지 않고도 최대한의 성능을 이끌어낼 수 있도록 돕습니다.
- 에코시스템과 커뮤니티의 중요성:
-
프레임워크는 단순히 코드 라이브러리를 넘어 광범위한 에코시스템(확장 가능한 라이브러리, 모델 저장 포맷, 시각화 툴, 데이터 로더, 배포 도구, 커뮤니티)으로 발전하고 있습니다.
-
이를 통해 다양한 수준(초보자부터 전문가까지)의 사용자들이 프레임워크를 활용하여 연구 성과를 공유하고 협업하며, 이를 프로덕션에도 적용하는 생태계를 형성할 수 있습니다.
6.2 Framework Evolution
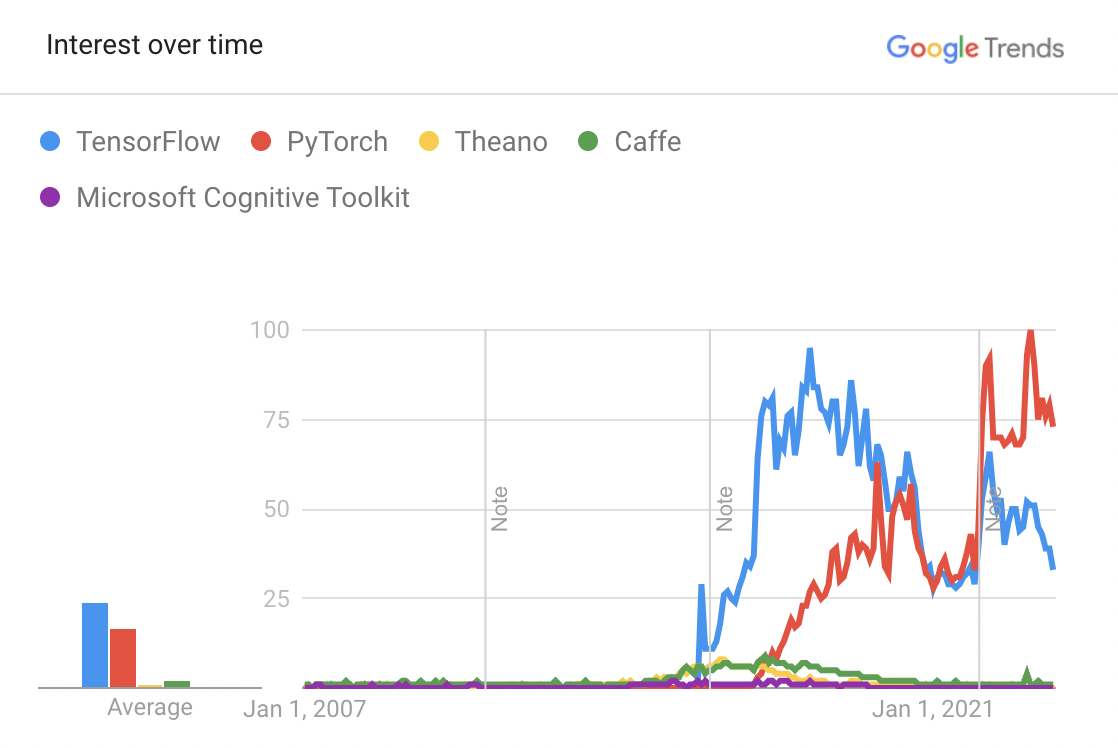
6.2 섹션은 머신러닝 및 딥러닝 프레임워크가 처음 등장한 이래로 어떤 식으로 발전해 왔는지, 그리고 이러한 진화가 시스템 설계 및 개발자 경험에 어떤 영향을 미쳤는지를 설명합니다. 초기의 단순한 수치 계산 라이브러리 수준에서 시작한 프레임워크들이 점차적으로 고수준 추상화, 자동 미분(Automatic Differentiation), 동적 계산 그래프(Dynamic Computation Graph) 지원, 멀티 플랫폼/하드웨어 추상화, 생태계 확장 등 다양한 기능들을 통합하며 발전한 과정을 다룹니다.
- 초기 시대: 저수준 수치 라이브러리 활용
-
초기 머신러닝 연구자들은 주로 C/C++ 혹은 Fortran 기반의 BLAS, LAPACK, CUDA, OpenMP와 같은 저수준 수치 해석 라이브러리를 이용해 모델을 구현했습니다.
-
이 단계에서는 자동 미분이나 모델 추상화 기능이 전무했고, 연구자가 직접 그래디언트를 계산하거나 메모리 관리를 수행해야 했습니다.
-
Tensor나 Array 형태의 원시 연산에 집중한 NumPy 같은 라이브러리도 있었지만, 이는 여전히 모델 정의와 최적화 과정에서 많은 수작업과 boilerplate 코드를 필요로 했습니다.
- 정적 계산 그래프(Static Computation Graph)의 등장
-
Theano, TensorFlow(초기 버전) 등의 프레임워크는 모델을 정적 계산 그래프로 표현하는 방식을 도입했습니다.
-
사용자는 모델과 연산을 그래프 형태로 정의하고, 학습 시점에 해당 그래프를 컴파일하여 효율적인 실행 계획(Execution Plan)을 확보했습니다.
-
이러한 정적 그래프 방식은 성능 최적화(커널 퓨전, 연산 그래프 축소)와 분산/병렬화 지원에 유리했으나, 모델을 동적으로 변경하거나 디버깅하는 데에는 상대적으로 불편했습니다. 즉, 유연성보다는 성능 중심의 접근이었습니다.
- 동적 계산 그래프(Dynamic Computation Graph) 프레임워크의 부상
-
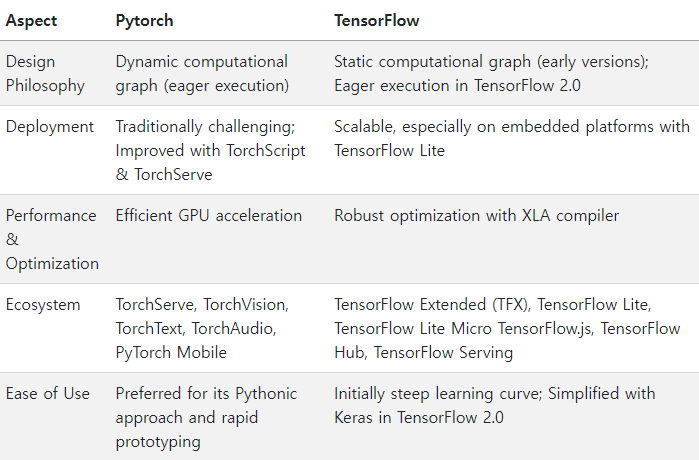
PyTorch, DyNet, Chainer 등은 동적 계산 그래프를 지원하며, 모델 정의 과정에서 그래프가 즉각적으로 생성되고 실행되는 방식을 채택했습니다(eager execution).
-
이는 Pythonic한 직관적 코딩 스타일을 가능케 했으며, for 루프나 if 문 등 일반적인 프로그래밍 제어 흐름과 쉽게 결합될 수 있었습니다.
-
연구자와 개발자들은 직관적으로 모델 구조를 변경하고 디버깅하기 수월해졌고, 이를 통해 빠른 프로토타이핑과 실험이 용이해졌습니다.
-
다만 초기에는 정적 그래프 방식에 비해 성능 최적화가 어렵다는 단점이 있었으나, 이후 최적화 기법이 발전하면서 동적 그래프 프레임워크도 점차 고성능을 구현하게 되었습니다.
- 자동 미분(Automatic Differentiation)의 고도화
-
초기에는 사용자가 직접 역전파(Backpropagation) 공식을 구현해야 했으나, Theano와 Torch 시절부터 시작해 TensorFlow, PyTorch, JAX 등의 프레임워크는 자동 미분 기능을 강력히 지원하고 있습니다.
-
자동 미분은 모델 정의만 하면 내부적으로 그래디언트를 자동 계산해주므로, 다양한 모델 구조를 빠르게 탐색하고 실험할 수 있게 했습니다.
-
이후 자동 미분 엔진들은 연산 그래프 최적화, 저수준 커널 호출 최적화, 메모리 재사용 방안 개선 등 점진적으로 개선되었습니다.
- 성능 최적화 및 컴파일러 기술 도입
-
XLA(TensorFlow), JIT 컴파일(PyTorch의 TorchScript), JAX의 JIT 등을 통해 동적 그래프 기반 프레임워크도 정적 컴파일 최적화의 혜택을 누릴 수 있게 되었습니다.
-
이러한 노력은 프레임워크가 동적 그래프의 유연성과 정적 그래프의 성능 최적화를 모두 추구하는 방향으로 진화하고 있음을 보여줍니다.
-
저수준 커널 튜닝, 혼합정밀 연산(Mixed Precision), 메모리 레이아웃 최적화 등 다양한 기술이 적용되며, 다양한 하드웨어(특히 GPU, TPU, 특수 목적 ASIC)에서 최고의 성능을 끌어내기 위한 작업이 활발히 진행되었습니다.
- 범용성 및 생태계 확장
-
초기 프레임워크들은 주로 연구 목적에 초점을 두었으나, 점차 생산 환경(Production)까지 고려하는 방식으로 진화했습니다.
-
모델 서빙, 분산 학습, 데이터 파이프라인, 하이퍼파라미터 최적화, 모니터링, MLOps와 연계된 종합 생태계가 형성되고 있습니다.
-
TensorFlow Extended(TFX), PyTorch Lightning, ONNX(Open Neural Network Exchange), HuggingFace Transformers 등의 등장으로 개발자들은 더욱 폭넓은 도구 세트와 에코시스템을 활용할 수 있게 되었습니다.
- 플랫폼/하드웨어 독립성 및 상호운용성
-
모델 포맷의 표준화(ONNX)와 다양한 백엔드 지원을 통해, 한 프레임워크에서 개발한 모델을 다른 환경에서 재사용하거나 다양한 하드웨어 가속기에서 동일 모델을 실행할 수 있는 유연성이 확대되었습니다.
-
이는 연구에서 프로덕션으로 이어지는 파이프라인을 단순화하고, 특정 프레임워크 또는 특정 벤더에 종속되는 것을 방지하는 방향의 진화를 보여줍니다.

6.3 Deep Dive into TensorFlow
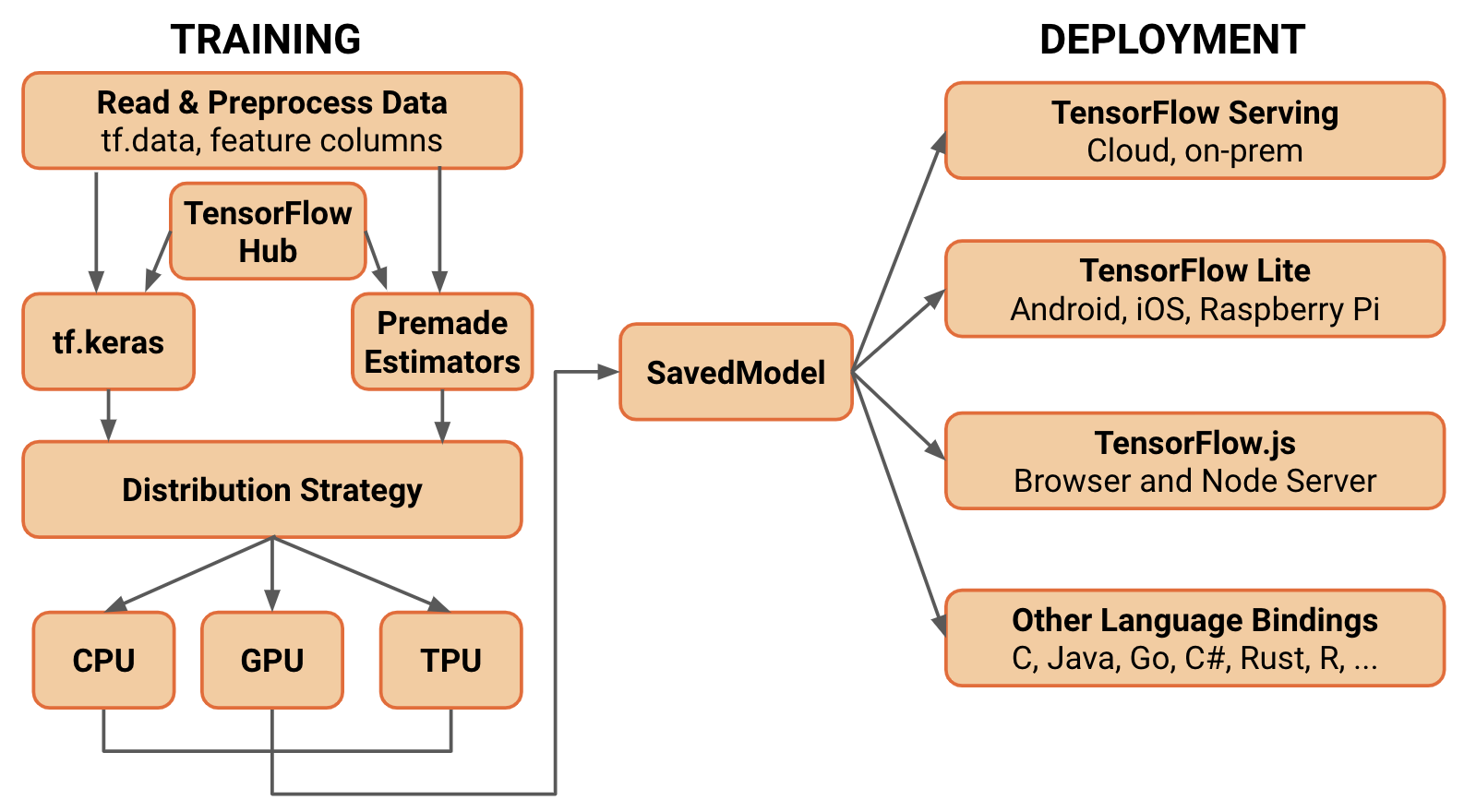
6.3 섹션은 딥러닝 프레임워크 중 가장 널리 알려진 하나인 TensorFlow에 대해 내부 동작 방식, 디자인 결정, 주요 기능, 성능 최적화 전략 등을 깊이 있게 소개합니다. TensorFlow는 Google Brain 팀에서 시작되어 다양한 하드웨어 가속기(GPU, TPU) 지원, 풍부한 에코시스템, 대규모 커뮤니티, 프로덕션급 안정성을 갖춘 프레임워크로 발전해왔습니다. 6.3에서는 TensorFlow가 어떻게 고수준 추상화와 로우레벨 연산을 모두 지원하고, 정적 그래프 기반에서 Eager Execution 기반으로 변화하는 과정을 포함해, 다양한 특징을 기술합니다.
- 텐서(Tensor)와 연산(Ops)
-
TensorFlow의 기본 데이터 구조는 텐서(tensor)이며, 이는 N차원 배열을 의미합니다. 텐서는 GPU, TPU와 같은 가속기 메모리에 효율적으로 배치될 수 있습니다.
-
텐서를 다루는 각종 연산(Op)들은 C++로 구현된 고성능 커널을 활용하며, Python API는 이들 연산을 고수준에서 호출하는 역할을 합니다.
- 정적 계산 그래프(Static Computation Graph) 개념(초기 TensorFlow 1.x)
-
초기 TensorFlow는 정적 계산 그래프를 사용하는 모델이었습니다. 사용자는 파이썬 코드로 그래프(연산과 노드) 정의를 마친 뒤, tf.Session()을 통해 그래프를 ‘실행(Run)’하는 방식을 택했습니다.
-
이 방식은 계산 그래프를 사전에 최적화, 컴파일, 스케줄링할 수 있어 성능 측면에 이점이 있었습니다. 특히 대규모 분산 학습이나 TPU 기반 학습에서 정적 그래프는 효율적으로 작동했습니다.
-
그러나 유연성이 떨어지고, 디버깅이 까다로우며, 모델 구조를 동적으로 변경하기 어렵다는 단점이 있었습니다.
- Eager Execution(동적 그래프)와 TensorFlow 2.x로의 전환
TensorFlow 2.x부터는 Eager Execution(즉각 실행 모드)가 기본으로 활성화되어 PyTorch 스타일의 동적 계산 그래프 모델을 지원합니다.
-
이제 사용자는 Python 코드 한 줄 한 줄이 바로 실행되어 결과 텐서를 반환하며, 이를 통해 직관적이고 인터랙티브한 모델 개발과 디버깅이 가능해졌습니다.
-
단, eager 모드에서도 tf.function 데코레이터를 사용하면 내부적으로 그래프를 빌드하고 XLA 컴파일러 최적화를 적용할 수 있어 정적 그래프의 성능 이점도 활용할 수 있습니다. 이로써 유연성과 성능을 모두 잡는 접근이 가능해졌습니다.
- 자동 미분(Automatic Differentiation)과 GradientTape
-
TensorFlow는 자동 미분을 통해 사용자가 직접 복잡한 역전파 코드를 작성하지 않아도 되게 합니다.
-
tf.GradientTape를 사용하면 Eager 모드에서도 편리하게 그래디언트를 계산할 수 있으며, 이를 통해 모델 매개변수 갱신(옵티마이저 사용)이 자동화됩니다.
-
이 자동 미분 엔진은 텐서 연산의 의존 관계를 추적한 뒤, 역전파를 위한 그래디언트 그래프를 구성해 효율적으로 미분 연산을 수행합니다.
- XLA(Accelerated Linear Algebra) 컴파일러 및 최적화
-
TensorFlow는 XLA라는 JIT(Just-In-Time) 컴파일러를 통해 특정 연산 그래프를 최적화하고, 하드웨어별 맞춤 커널을 생성할 수 있습니다.
-
XLA는 연산을 하나로 융합(Fusion)하거나, 불필요한 텐서 복사를 제거하는 등 다양한 최적화 기법을 통해 실행 성능을 높입니다.
-
이를 통해 정적 그래프 성능 최적화의 장점을 여전히 살리면서, 동적 그래프 기반 개발의 생산성을 해치지 않는 균형을 구현합니다.
- 다양한 하드웨어 가속기 지원(GPU, TPU, ASIC 등)
-
TensorFlow는 초기부터 GPU 연산 지원에 특화되어 있었으며, 이후 Google Cloud TPU 지원을 통합하여 대규모 모델 학습에 최적화된 환경을 제공합니다.
-
하드웨어 추상화 계층을 두어, 같은 모델 코드가 GPU, CPU, TPU, ASIC 등 다양한 디바이스 상에서 동작할 수 있게 합니다. 이는 모델 포팅과 확장성 확보에 큰 장점을 제공합니다.
- 분산 학습 지원과 tf.distribute
-
TensorFlow는 클러스터 환경, 여러 GPU 및 TPU를 활용한 분산 학습을 지원합니다. tf.distribute.Strategy API를 이용하면 단일 기기 코드를 쉽게 분산 환경으로 확장할 수 있습니다.
-
MirroredStrategy, MultiWorkerMirroredStrategy, TPUStrategy 등 다양한 전략을 통해 사용자 요구에 맞춘 분산 학습 시나리오를 구현할 수 있습니다.
- 고수준 API: Keras와의 통합
-
TensorFlow 2.x부터는 Keras를 TensorFlow의 공식 고수준 API로 통합하였습니다.
-
tf.keras는 직관적 모델 정의, 레이어 추상화, 손쉬운 모델 훈련/평가 파이프라인 등 개발 생산성을 극대화하는 기능을 제공합니다.
-
이로써 연구용 프로토타이핑부터 프로덕션 모델 배포까지 하나의 통합된 API로 커버할 수 있게 되었습니다.
- 생태계 및 툴링 지원
-
TensorFlow는 모델 서빙(TF Serving), 경량 모델 변환(TF Lite for mobile/edge), 웹 상의 추론(TF.js), 파이프라인 관리(TFX), 실험 추적(TensorBoard) 등 풍부한 생태계 툴을 제공합니다.
-
이러한 도구들을 통해 모델 개발부터 배포, 모니터링까지 엔드-투-엔드 머신러닝 워크플로우를 지원합니다.
- 디버깅, 프로파일링, 메타그래프 활용
- TensorFlow는 tf.debugging API나 TensorBoard Profiler 등을 통해 그래프 실행 시 병목 구간 식별, 메모리 사용량 관찰, 성능 튜닝에 도움을 줍니다.
- 메타그래프(MetaGraph) 및 SavedModel 포맷은 모델, 파라미터, 시그니처를 패키징하여 재사용 또는 다른 플랫폼에 쉽게 배포하는 것을 가능케 합니다.
6.4 Basic Framework Components
개념적 구조와 흐름을 바탕으로, 딥러닝/머신러닝 프레임워크가 내부적으로 어떤 핵심 요소들을 통해 동작하는지, 그리고 이들이 어떻게 상호작용하며 개발자의 생산성과 모델 성능을 향상시키는지에 초점을 맞추어 정리하였습니다.
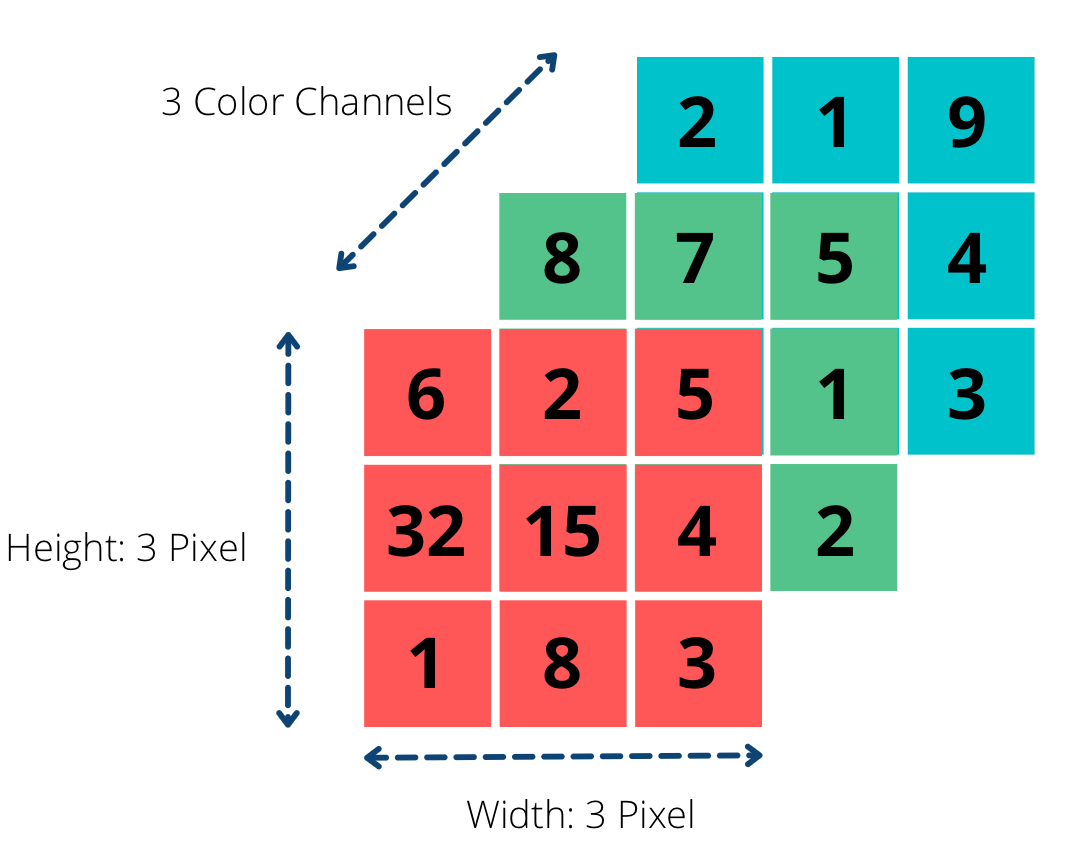
- 텐서(Tensor) 추상화
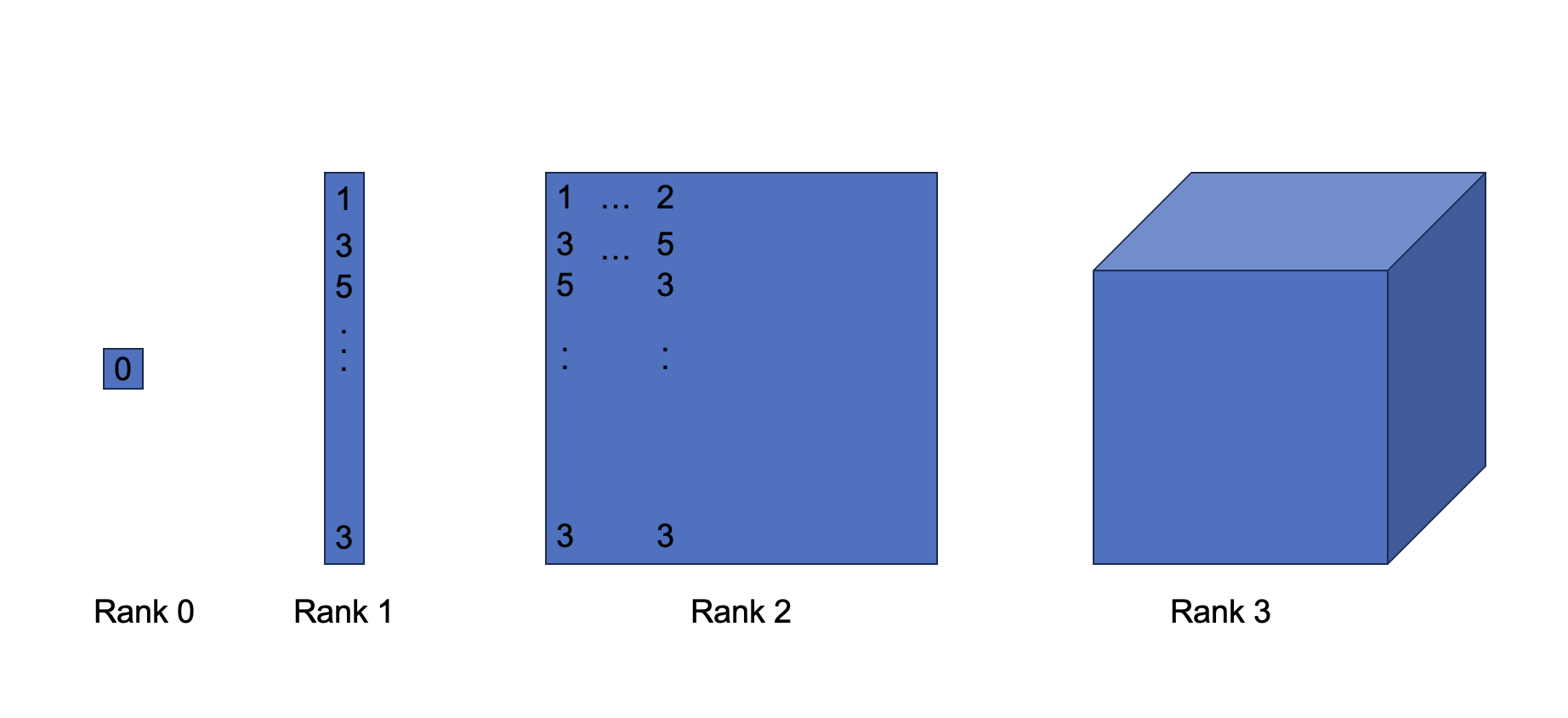
-
정의: 텐서는 N차원 배열 구조를 말하며, 프레임워크의 가장 기초적인 데이터 단위입니다.
-
특징: 텐서는 CPU, GPU, TPU 등 다양한 하드웨어 메모리에 효율적으로 매핑될 수 있으며, 데이터 타입(부동소수점, 정수, 복소수 등)과 형태(shape)를 갖습니다.
-
역할: 텐서는 모든 모델 파라미터(가중치, 편향) 및 입력/출력 데이터, 중간 특징량을 표현하는 핵심 매개체로, 프레임워크 내 대부분 연산의 대상입니다.
- 연산(Operation)과 계산 그래프(Computation Graph)
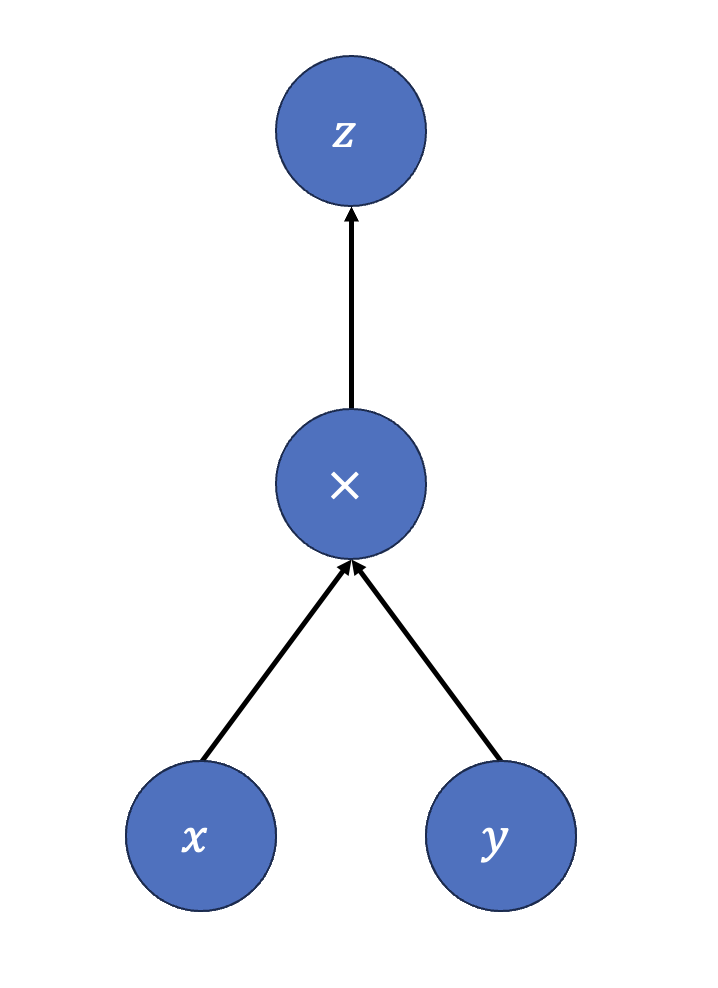
-
연산(Operation): 텐서를 입력받아 또 다른 텐서를 출력하는 기본적인 함수(예: 행렬곱, 합산, 활성화 함수).
-
계산 그래프(Computation Graph): 연산들이 서로 어떻게 연결되어 모델을 구성하는지 나타내는 추상화. 텐서가 노드이고 연산이 에지(또는 반대로 정의할 수도 있음)로 표현되는 경우도 있습니다.
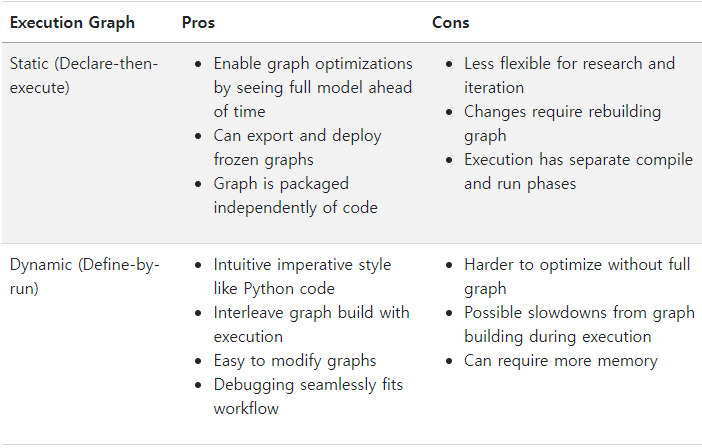
-
정적 vs 동적 그래프:

정적 그래프: 실행 전에 전체 그래프를 정의하고 최적화/컴파일하는 방식.
동적 그래프: 실행 시점에 그래프를 바로 구성하고 연산을 실행하는 방식.
- 자동 미분(Automatic Differentiation) 엔진
-
기능: 사용자 대신 모델의 그래디언트를 자동으로 계산해주는 메커니즘.
-
원리: 순전파(forward pass) 시 각 연산의 중간 결과를 저장하고, 역전파(backward pass)에서 이들을 활용해 연쇄법칙(chain rule)에 따라 그래디언트를 산출.
-
장점: 연구자, 개발자는 모델 구조 설계에만 집중할 수 있고, 복잡한 수학적 도함수 계산을 직접 구현할 필요가 없게 됩니다.
- 런타임(Execution Runtime)과 디바이스 할당(Placement)
-
런타임: 계산 그래프를 실제로 실행하는 엔진. 주어진 연산을 어떤 순서로, 어떤 디바이스(CPU, GPU, TPU)에서, 어떤 방식으로 실행할지 결정합니다.
-
디바이스 할당(Placement): 텐서와 연산을 특정 디바이스에 할당하는 과정으로, 성능 최적화를 위해 중요합니다.
-
스케줄링(Scheduling): 병렬 실행 가능성을 극대화하고 리소스 사용 효율을 높이기 위해 연산 순서를 재배치하거나 동시 실행을 관리하는 과정.
- 최적화(Optimization) 및 컴파일러 연계
-
컴파일러 연계: XLA, TVM, Halide 같은 컴파일러 또는 내부 최적화 엔진을 통해 연산 그래프를 최적화.
-
최적화 기법: 커널 퓨전(Fusion)으로 메모리 접근 횟수를 줄이거나 불필요한 계산을 제거하는 연산 그래프 단순화, 혼합 정밀도(Mixed Precision) 사용 등.
-
성능 향상: 이러한 최적화를 통해 모델 학습 및 추론 속도를 대폭 개선하고, 자원 사용 효율을 높입니다.
- 고수준 API 레이어
-
고수준 API 예: TensorFlow의 Keras, PyTorch의 Torch.nn, JAX의 Flax 등.
-
역할: 복잡한 모델 정의 과정을 간소화하고, 레이어 추상화, 훈련 루프 관리, 체크포인트 저장 등의 반복적 작업을 손쉽게 지원.
-
장점: 초보자나 프로토타이핑 단계에서 생산성을 향상시키며, 표준화된 코드 패턴을 통한 협업과 재사용을 촉진합니다.
- 유틸리티와 생태계 지원(데이터 로더, 모델 저장/배포, 시각화 도구 등)
-
데이터로더(Data Loader): 대용량 데이터셋을 효율적으로 처리하고, 배치(batch) 단위로 모델에 공급하는 기능.
-
체크포인트 및 모델 저장: 학습한 모델 파라미터를 저장하고 로드하는 기능.
-
시각화 및 디버깅 툴: TensorBoard, Profiler 등을 통한 성능 및 학습 과정 모니터링.
-
모델 배포 지원: 모바일/임베디드 장치용 경량화(TF Lite, PyTorch Mobile), 웹 기반(TF.js), 서빙 서버(TF Serving) 등.
