1. Introduction
이번 글에서는 2023년 CVPR에 발표된 GLIGEN: Open-Set Grounded Text-to-Image Generation 논문을 리뷰합니다. 이 논문은 GLIGEN이라고 불리며, 이번 글에서도 GLIGEN이라고 지칭하겠습니다
1-1. 기존 Diffusion Model의 한계
최근 몇 년 사이에 다양한 Diffusion Model이 발표되었는데요. 특히 Open AI가 발표한 GLIDE부터는 Text Guidance 기능이 추가되면서 실제 존재하지 않는 상상속의 이미지를 생성하는것이 가능해졌습니다. GLIDE 발표 이후 Imagen, DALLE2 등 다양한 Text Guided Diffusion Model이 발표되며 Diffusion Model의 전성기를 알렸죠. 뿐만 아니라 Stable Diffusion은 Text Condition 뿐만 아니라 다양한 형태의 Condition도 입력으로 받아 이미지를 생성할 수 있음을 보였습니다.
하지만 앞서 언급한 모든 Diffusion Model들은 두 가지의 공통적인 한계를 갖고 있는데요.
첫 번째 한계는 여러 Condition을 동시에 입력으로 받을 수 없다는 점입니다. GLIDE, Imagen, DALLE2 등은 Text 만을 Condition으로 받을 수 있고요. Stable Diffusion은 다양한 형태의 Condition을 받을 수 있지만 하나의 Condition만 골라서 받아야 하죠. 즉 이들은 공통적으로 Bounding Box와 이를 설명하는 Text를 동시에 Condition으로 입력 받을 수 없다는 한계를 갖고 있습니다.
두 번째 한계는 Diffusion Model을 학습하기 위해 많은 Computing Resource가 필요하다는 점입니다. Diffusion Model을 학습하기 위해서는 당연한 것이라고 생각할 수도 있는데요. 이때 필요한 GPU 양을 생각해보면 이 부분이 얼마나 큰 Bottleneck인지 알 수 있습니다.
1-2. 기존 Diffusion Model 대비 GLIGEN의 장점
이에 GLIGEN에서는 두 가지 한계를 모두 극복한 모델을 제안합니다. 우선 GLIGEN은 Multi Condition을 입력 받을 수 있습니다. 앞서 예를 든 사례처럼 Bounding Box와 이를 설명하는 Text를 동시에 입력으로 받을 수 있죠. 이렇게요.

위 그림은 GLIGEN이 생성한 이미지 예시를 보여주고 있습니다. 입력으로는 두 가지 형태의 Condition을 받았는데요.
첫 번째는 Bounding Box와 Class 입니다. 가장 왼쪽 그림에 색깔별 Bounding Box를 볼 수 있습니다. 그리고 아래쪽에 각 Bounding Box에 들어갈 Class에 해당하는 Grounded Text를 볼 수 있습니다.
두 번째는 그림을 설명하는 Text, 즉 Caption입니다. 생성할 이미지 전체에 대한 자세한 묘사를 표현하고 있죠.
두번째, 세번째, 네번째 그림은 이러한 Caption과 Condition을 받아 GLIGEN이 생성한 이미지입니다. 원하는대로 위치까지 잘 맞춰 이미지를 생성한 모습을 볼 수 있습니다.
다음으로 Diffusion Model을 학습하기 위한 Computing Resource 문제도 해결했는데요. 이를 위해 기존 Diffusion Model의 모든 가중치는 고정한 채 새로 추가된 모듈만 학습하는 방법을 제안합니다. 이에 대한 구체적인 방법은 아래에서 확인하도록 하겠습니다.
2. GLIGEN
이번 챕터에서는 GLIGEN의 동작 방법에 대해 살펴보겠습니다.
2-1. Architecture
먼저 전체 Architecture 입니다. GLIGEN에서 중요하게 생각하는 두 가지 포인트를 말씀드렸는데요. 첫 번째는 Multi Modal을 Condition으로 받아야 한다는 것이고요. 두 번째는 기존 Diffusion Model을 그대로 활용한 채 일부 연산을 위한 모듈만 추가한다는 점이었습니다. 이 두가지 포인트를 염두에 두고 GLIGEN의 Architecture를 살펴보겠습니다. GLIGEN의 Architecture는 다음과 같습니다.
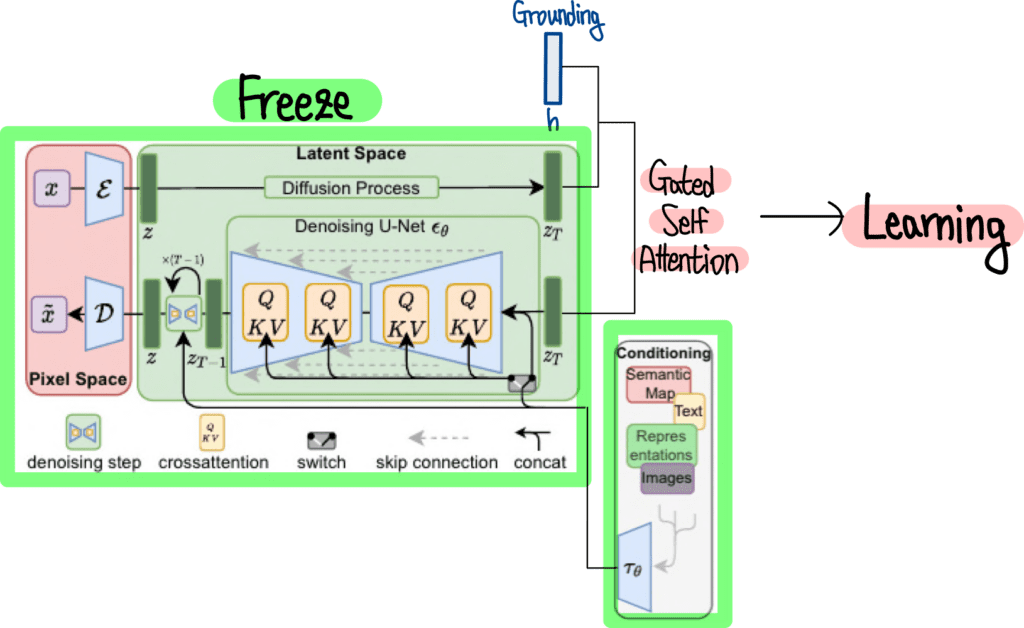
GLIGEN Architecture의 몸통 부분은 어디서 많이 본 그림이죠? 바로 Stable Diffusion Architecture 입니다. GLIGEN은 Stable Diffusion을 그대로 활용하고 있습니다. Stable Diffusion의 모든 파라미터는 고정되어 기존의 학습한 내용을 유지합니다. 그 말은 Stable Diffusion의 Image Generation 능력은 그대로 활용하면서 새로운 Condition인 Grounding에 대한 연산만 추가해주면 된다는 말이죠. 이렇게 Grounding에 대한 추가 연산은 그림 우측 상단의 Grounding h와 Gated Self Attention 모듈에서 볼 수 있습니다. 이제 아래에서 이 부분에 대한 자세한 내용을 살펴보겠습니다.
2-2. Making Grounding
먼저 Grounding 제작 방법을 살펴보겠습니다. Grounding이란 추가 Condition이라고 이해하면 되는데요. 예를 들면 이런 형태가 되겠죠.

Instruction은 기존 Diffusion Model과 달리 Caption과 Grounding 2개로 구성되어 있고요. Caption c는 기존과 동일하게 이미지를 표현하는 Text입니다. Grounding은 (e,l) 두가지로 구성되어 있습니다. 예를 들어 Bounding Box와 Class 정보를 어떻게 GLIGEN이 연산할 수 있는 형태로 변환하는지 살펴보겠습니다.

Bounding Box는 Box 위치 정보와 Class 정보 두 가지로 구성되어 있는데요. 위 그림 bride, groom, wedding cake는 Class 정보를 표현하고 있고요. 빨간색, 초록색, 노란색 박스는 Bounding Box 위치 정보를 표현하고 있습니다. 이 두 정보는 각각의 방법을 사용하여 GLIGEN의 입력으로 변환해주는데요.
먼저 Class 정보는 Pretrained Text Encoder를 사용하여 Text Embedding으로 변환해줍니다. 위 그림에서 연두색 부분에 해당합니다.
Bounding Box의 위치 정보는 Fourier Transform을 사용해 변환해줍니다.
최종적으로 이 둘 정보를 결합하여 MLP를 통해 GLIGEN이 연산할 수 있는 형태로 변환해줍니다. 이를 수식으로 표현하면 다음과 같습니다.
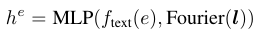
2-3. Gated Self Attention
이제 이렇게 나온 Grounding 정보를 기존 정보들과 결합하여 연산해주어야 하는데요. 이 부분이 사실상 GLIGEN의 핵심이라고 할 수 있습니다. 다른 부분들은 Stable Diffusion 모델을 그대로 사용하고 있으니까요. Gated Self Attention은 다음과 같이 구성되어 있습니다.
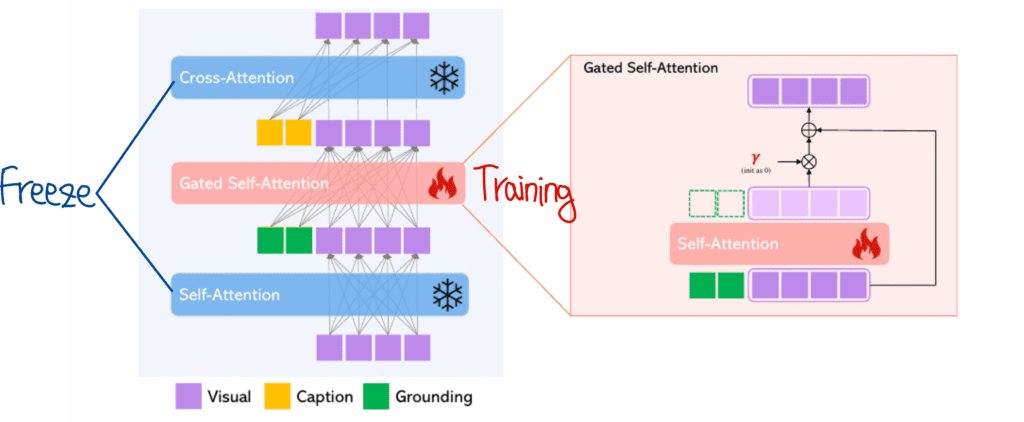
Grounding 정보는 기존의 Visual 정보와 Attention 연산을 수행해주는데요. 위 그림의 Gated Self Attention 부분에서 볼 수 있듯이 Grounding 과 Visual 정보간의 Self Attention을 수행 후 Visual 정보만 추출하는 모습을 볼 수 있습니다. 이렇게 나온 Visual 정보에는 Scale을 조절하기 위해 𝛾를 곱해주고요. 다시 기존 Visual 정보에 더해주고 있습니다. 이 과정을 수식으로 표현하면 다음과 같습니다.
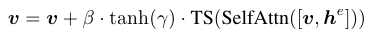
𝛾는 Scale 조절을 위한 학습 가능한 Scalar 값이고요. 학습을 시작할때는 0으로 시작합니다. 즉 Gated Self Attention 정보는 받지 않고 시작하는 것이죠. 그리고 학습이 진행됨에 따라 자연스럽게 적절한 값을 찾아갑니다.
TS는 Token Selection Operation으로, 간단히 Visual 정보만 선택해주는 연산이라고 생각하면 됩니다.
𝛽는 Scheduled Sampling을 위한 값으로 학습 동안은 1을 유지합니다.
참고로 Gated Self Attention은 왜 Cross Attention을 사용하지 않았을까 의문이 들 수 있는데요. 저자들은 이 부분에 대해 실험적으로 Self Attention의 성능이 더 좋았기 때문이라고 답하고 있습니다.
2-4. Loss Function
이렇게 만들어진 GLIGEN을 학습하기 위한 Loss Function은 다음과 같습니다.
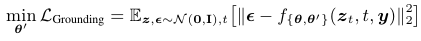
𝜃는 기존 Stable Diffusion 파라미터를 의미하고요. 𝜃’은 새롭게 추가된 파라미터를 의미합니다. GLIGEN에서는 𝜃’만 학습해줍니다.
3. Experiments
다음으로 이렇게 학습한 GLIGEN이 생성한 이미지들을 살펴보겠습니다.
3-1. Grounded Text To Image
먼저 Bounding Box 정보를 Ground로 하고 전체 이미지를 설명하는 Caption을 입력으로 받아 생성한 이미지들을 살펴보겠습니다.

위 그림은 GLIGEN과 Stable Diffusion이 생성한 이미지들을 비교한 그림입니다. 두 모델 모두 Caption이 묘사한 이미지를 생성해 주었는데요. Stable Diffusion 또한 Caption의 내용에 맞게 이미지를 생성한 모습을 볼 수 있습니다. 하지만 Bounding Box에 해당하는 Ground 정보를 반영하지는 못하는 모습이죠. 반면 GLIGEN은 Caption 내용뿐만 아니라 Ground 정보까지 훌륭하게 반영하여 이미지를 생성한 모습을 볼 수 있습니다.
3-2. Beyond Text Modality Grounding
GLIGEN의 하이라이트라고 할 수 있죠. 이번에는 Text Modality 외의 다양한 Ground에 대한 이미지 생성 결과를 살펴보겠습니다.

위 그림은 다양한 형태의 Ground에 대해 GLIGEN이 생성한 이미지를 보여주고 있습니다. Key Point, Depth Map, HED Map, Normal Map, Semantic Map 등 다양한 Ground를 입력으로 했을때의 생성 이미지를 보여주고 있습니다.
4. Conclusion
이번 글에서는 GLIGEN 논문의 핵심 내용을 살펴봤습니다. 먼저 기존 Diffusion Model들의 한계에 대해 살펴봤습니다. Stable Diffusion은 다양한 Modality를 Condition으로 입력받을 수 있지만 동시에 다양한 Condition을 입력받을 수 없다는 점이 한계였죠. 이에 GLIGEN에서는 다양한 Condition을 입력으로 받을 수 있는 방법을 제안했고요. 뿐만 아니라 Stable Diffusion의 파라미터는 그대로 고정한 채로 Ground 정보에 대한 연산 파라미터만 Fine Tuning 하면 된다는 점이 큰 장점이었습니다. 이렇게 학습한 GLIGEN은 다양한 Modality에 대한 입력을 Caption과 동시에 받아 높은 퀄리티의 이미지를 생성하는 모습을 확인했습니다.
출처 : https://ffighting.net/deep-learning-paper-review/diffusion-model/gligen/
Github : Gligen Github
