1. Introduction
이번 글에서는 2022년 CVPR에 발표된 High-Resolution Image Synthesis with Latent Diffusion Models 논문을 리뷰합니다. 이 논문은 Stable Diffusion이라고 불리며, 이번 글에서도 Stable Diffusion이라고 지칭하겠습니다.
최근들어 GLIDE, Imagen, DALLE2 등 엄청난 수준의 이미지를 생성하는 Diffusion Model들이 많이 발표되었는데요. 하지만 이 모델들은 모두 공통적인 한계를 갖고 있습니다. 바로 저화질 이미지만을 생성할 수 있다는 것이죠. 때문에 저화질 이미지를 Upscale하기 위한 Super Resolution 모델을 따로 학습하여 붙여주어야 했죠. 이러한 문제는 이미지 픽셀값을 바로 생성해야 하는 Diffusion Model의 근본적인 문제로부터 기인합니다. 다음 그래프는 Bit Rate에 따른 Loss를 바탕으로 GAN, Autoencoder 와 Diffusion Model을 비교한 그래프입니다.
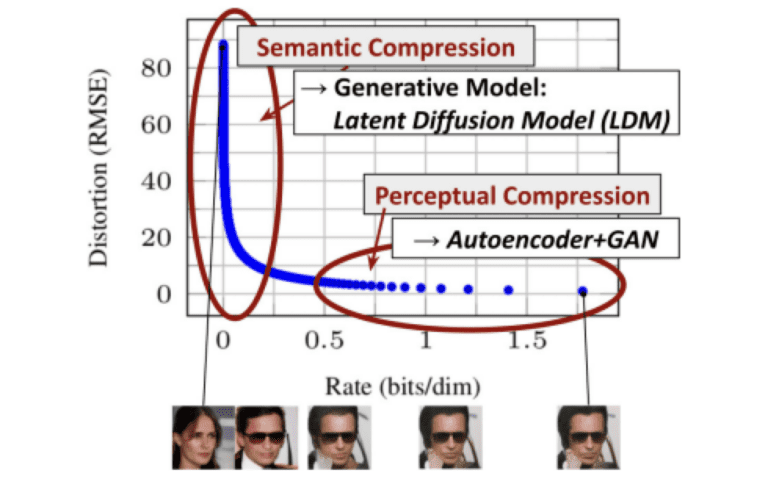
Bit Rate가 작아질수록 사람의 눈에는 인지가 안되는 부분일텐데요. GAN과 Autoencoder는 Bit Rate가 비교적 큰 Perceptual한 부분을 학습 하는데에 주력하는 모습을 볼 수 있습니다. 반면 Diffusion Model은 Bit Rate가 작은, Non Perceptual한 부분을 학습하는데에 초점을 맞추고 있는 모습이죠. 사실 사람 눈에 이 부분은 그다지 중요하지 않은데 말이죠. 따라서 Stable Diffusion은 이러한 부분을 개선하여 Perceptual 한 부분에 초점을 맞춰 학습하는 Diffusion Model을 제안합니다. 본문에서 자세한 내용을 살펴보겠습니다.
2. Stable Diffusion
이번 챕터에서는 Stable Diffusion 모델의 제안 방법을 자세히 살펴보겠습니다.
2-1. Architecture
먼저 큰 그림을 살펴보겠습니다. 위에서 Diffusion Model은 Non Perceptual 한 부분을 학습하는데에 초점을 맞추는것이 문제라고 말씀드렸는데요. 이는 Diffusion Model의 특성상 Image pixel 값을 직접 예측해야 한다는 문제에서 기인합니다. 그렇다면 Pixel값을 직접 예측하지 않고 다른 방식을 사용해야 겠는데요. 저자들은 이를 위해 Auto Encoder를 사용합니다. Diffusion Model이 픽셀값을 직접 예측하는것이 아닌, Auto Encoder로부터 압축된 Latent Embedding을 예측하는 방법이죠. 그림으로 표현하면 다음과 같습니다.

위 그림은 기존 Diffusion Model과 Stable Diffusion Model의 Architecture를 비교하고 있습니다. 아래의 Stable (Latent) Diffusion Model의 양측에 Auto Encoder가 자리한 모습을 볼 수 있는데요. Diffusion Model은 그 사이에서 Latent Embedding을 학습하는 구조임을 알 수 있습니다.
이 구조를 조금 더 자세히 표현하면 다음과 같습니다.
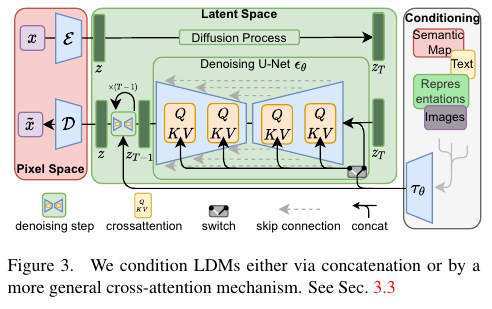
가장 왼쪽의 빨간색 음영 부분은 Auto Encoder를 표현하고 있습니다. 가운데 초록색 음영 부분은 Latent Diffusion Model을 표현하고 있고요. 오른쪽의 회색 음영은 Condition 입력 부분을 표현하고 있습니다. 이렇게 입력된 Condition은 Diffusion Model 내부에서 Cross Attention 연산을 사용하여 적용되는 모습이 보이는데요. 자세한 내용은 아래에서 살펴보겠습니다.
2-2. Perceptual Image Compression
이렇게 Auto Encoder를 학습하는 과정을 저자들은 Perceptual Image Compression이라고 표현하는데요. 이는 기존의 Auto Encoder 학습 방법과 동일하게 Perceptual Loss를 사용하여 이루어집니다. 이렇게 학습된 Auto Encoder 덕분에 Diffusion Model은 Auto Encoder로부터 출력되는 Latent Embedding을 생성하도록 학습할 수 있죠.
2-3. Latent Diffusion Models
다음은 Latent Diffusion Model에 대해 살펴보겠습니다. 기존 Diffusion Model의 Loss Function은 다음과 같이 표현됩니다.
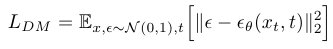
Noise를 Pixel 값으로 직접 예측하는 모습을 볼 수 있죠. 반면 Latent Diffusion Model의 Loss Function은 다음과 같이 표현됩니다.

입력으로 픽셀값 x가 아닌 Latent Embedding z가 들어가는 차이를 볼 수 있습니다. 이렇게 Auto Encoder로 정보를 압축해준 덕분에 High Frequency와 사람 눈으로 인식이 안되는 Noise성 정보들은 모두 제거되었다고 볼 수 있습니다. 따라서 좀더 Semantic한 부분에 집중할 수 있으면서도 계산 복잡도는 줄어드는 장점이 있죠.
2-4. Conditioning Mechanisms
이번에는 Condition 입력 방법에 대해 살펴보겠습니다. Architecture 우측 회색 음영 부분에는 다양한 형태의 Condition이 입력되는 모습을 표현해주고 있는데요. Stable은 다양한 Condition을 입력 받을 수 있지만 이중 한 가지만 입력으로 받습니다. 이 Condition은 각자에 맞는 적절한 Encoder 𝜏가 필요하죠. 예를 들어 Text를 Condition으로 받기 위해서는 Pretrained LLM의 Text Encoder가 필요하겠죠.
이렇게 입력된 Condition은 Diffusion Model 내에서 연산중인 Image 정보 Zt와 연산 되어야 합니다. 이때 이 둘의 상관 관계를 잘 고려하여 Image 정보 Zt에 반영해주어야 하죠. 이렇게 서로 다른 정보의 상관 관계를 고려하기 위해 가장 많이 사용되는 방법이 바로 Cross Attention 이죠. Self Attention이 하나의 정보에 대한 상관 관계를 계산하는 방법이었다면 Cross Attention은 동일한 메커니즘을 사용하여 두 정보의 상관 관계를 고려하는 방법이라고 할 수 있습니다.
Stable Diffusion에 적용된 Cross Attention을 수식으로 표현하면 다음과 같습니다.
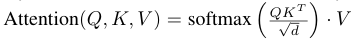
이때의 Query, Key, Value 는 각각 다음과 같이 표현됩니다.
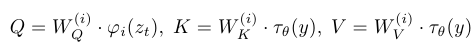
이때의 Zt는 Image 정보고요, y는 Condition 정보입니다. 따라서 이는 ‘이미지와 Condition의 상관 관계를 고려하여 Condition 정보에 가중치를 반영 하는것’ 이라고 해석할 수 있습니다. 이렇게 가중치가 반영된 Condition 정보는 최종적으로 Zt에 다시 더해집니다.
이렇게 Cross Attention까지 적용된 최종 Stable Diffusion Loss Function은 다음과 같이 표현됩니다.
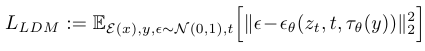
Latent Embedding z와 Process Time t, 그리고 Condtion y까지 모두 반영된 모습을 볼 수 있습니다.
Experiments
3-1. Image Generation
먼저 다양한 데이터셋에 대한 Image Generation 결과입니다.

사람 얼굴, 교회, 침실, ImageNet 등등 다양한 데이터셋을 사용하여 이미지를 잘 생성하는 모습을 볼 수 있습니다.
3-2. Text To Image
다음은 Text를 Condition으로 받아 생성한 이미지입니다.

세상에 존재하지 않는 개념의 이미지들도 잘 생성하는 모습을 볼 수 있습니다.
3-3. Layout To Image
Stable Diffusion은 Text가 아닌 Condition도 입력으로 받을 수 있는데요. 대표적으로 Layout이 있습니다. 쉽게 말해서 Bounding Box와 Class 정보를 입력으로 받는 것인데요. 이는 Text를 입력으로 받는 것 보다 위치 정보를 명확하게 전달할 수 있다는 장점이 있죠. 이렇게 Layout 정보를 Condition으로 받아 생성한 이미지들은 다음과 같습니다.
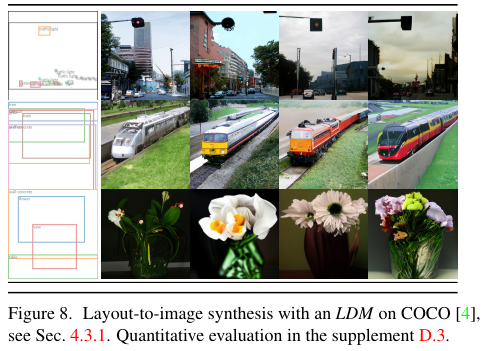
3-4. Super Resolution
Stable Diffusion을 사용하여 Super Resolution도 수행할 수 있는데요. 방법은 기존 Diffusion Model에서와 동일합니다. Super Resolution 결과는 다음과 같습니다.

3-5. Inpainting
마지막으로 Inpainting 결과를 살펴볼건데요. Inpainting은 GLIDE에서와 동일한 방법을 적용하였습니다. 결과는 다음과 같습니다.

출처 : https://ffighting.net/deep-learning-paper-review/diffusion-model/stable-diffusion/
