Mask R-CNN
Introduction
컴퓨터 비전의 주요 과제 3가지
1) Classification
2) Object detection
3) Image segmentation
중 Faster R-CNN까지는 2-stage에 기초한 특히 2) Object detection 를 위해 고안된 모델들이였다.
이번에 설명할 Mask R-CNN은 3) Image segmentation을 수행하기 위해 고안된 모델이다.
Faster R-CNN과 크게 다르지 않는 구조로써 mask branch와 FPN, 그리고 RoI align이 추가된 것 말고는 없다.
Mask R-CNN
Faster R-CNN은 이전 글에서 설명했듯이 Fast R-CNN에 RPN(region proposal network)를 추가한 구조로
Faster R-CNN = RPN + Fast R-CNN 이라 볼 수 있다.
여기에 Mask R-CNN이 Faster R-CNN으로부터 달라진 것은 다음과 같다.
1) Fast R-CNN의 classification, localization(bounding box regression) branch에 새롭게 mask branch가 추가됐다.
2) RPN 전에 FPN(feature pyramid network)가 추가됐다.
3) Image segmentation의 masking을 위해 RoI align이 RoI pooling을 대신하게 됐다.
위 3가지를 설명하기에 앞서 먼저 Mask R-CNN의 구조를 살펴보도록 하자.
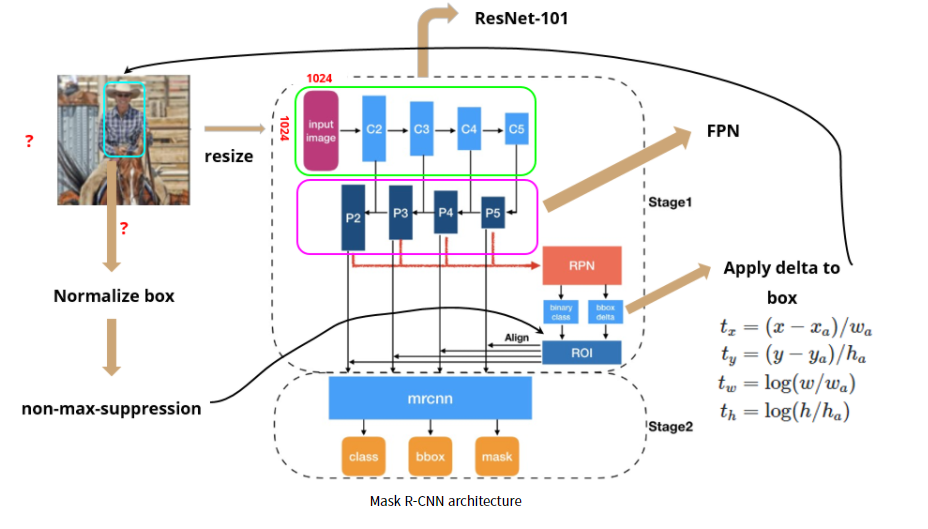
N x N 사이즈의 인풋 이미지가 주어졌을때 Mask R-CNN의 process는 다음과 같다.
-
800~1024 사이즈로 이미지를 resize해준다. (using bilinear interpolation)
-
Backbone network의 인풋으로 들어가기 위해 1024 x 1024의 인풋사이즈로 맞춰준다. (using padding)
-
ResNet-101을 통해 각 layer(stage)에서 feature map (C1, C2, C3, C4, C5)를 생성한다.
-
FPN을 통해 이전에 생성된 feature map에서 P2, P3, P4, P5, P6 feature map을 생성한다.
-
최종 생성된 feature map에 각각 RPN을 적용하여 classification, bbox regression output값을 도출한다.
-
output으로 얻은 bbox regression값을 원래 이미지로 projection시켜서 anchor box를 생성한다.
-
Non-max-suppression을 통해 생성된 anchor box 중 score가 가장 높은 anchor box를 제외하고 모두 삭제한다.
-
각각 크기가 서로다른 anchor box들을 RoI align을 통해 size를 맞춰준다.
-
Fast R-CNN에서의 classification, bbox regression branch와 더불어 mask branch에 anchor box값을 통과시킨다.
Resize input image
Mask R-CNN에서는 backbone으로 ResNet-101을 사용하는데 ResNet 네트워크에서는 이미지 input size가
800~1024일때 성능이 좋다고 알려져있다. (VGG는 224 x 224)
따라서 이미지를 위 size로 맞춰주는데 이때 bilinear interpolation을 사용하여 resize해준다.
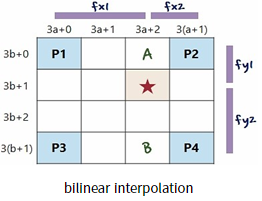
bilinear interpolation은 여러 interpolation기법 중 하나로 동작과정은 다음과 같다.
2 x 2의 이미지를 위 그림과 같이 4 x 4로 Upsampling을 한다면 2 x 2에 있던 pixel value가 각각
P1, P2, P3, P4로 대응된다. 이때 총 16개 중 4개의 pixel만 값이 대응되고 나머지 12개는 값이 아직 채워지지 않았는데
이를 bilinear interpolation으로 값을 채워주는 것이다. 계산하는 방법은 아래와 같다.

이렇게 기존의 image를 800~1024사이로 resize해준 후 네트워크의 input size인 1024 x 1024로 맞춰주기 위해
나머지 값들은 zero padding으로 값을 채워준다.
Backbone-ResNet101
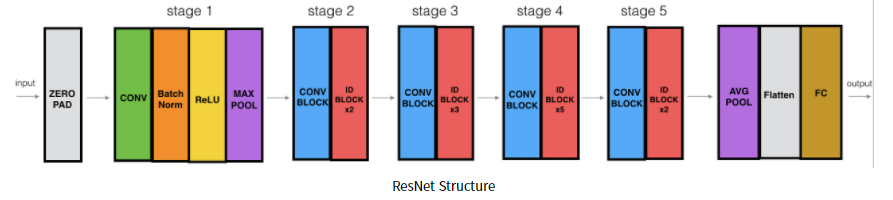
Mask R-CNN에서는 Backbone으로 ResNet모델을 사용한다. ResNet 모델은 다음과같다.
Feature Pyramid Network
이전의 Faster R-CNN에서는 backbone의 결과로 나온 1개의 feature map에서 roi를 생성하고
classification 및 bbox regression을 진행했다. 해당 feature map은 backbone 모델에서 최종 layer에서의 output인데 이렇게 layer를 통과할수록 아주 중요한 feature만 남게되고 중간중간의 feature들은 모두 잃어버리고 만다.
그리고 최종 layer에서 다양한 크기의 object를 검출해야하므로 여러 scale값으로 anchor를 생성하므로 비효율적이다.
따라서 이를 극복하기 위한 방법이 FPN이다.
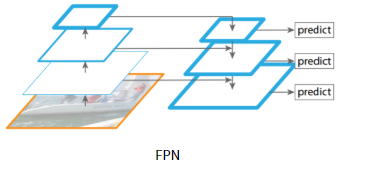
FPN에서는 위 그림과 같이 마지막 layer의 feature map에서 점점 이전의 중간 feature map들을 더하면서
이전 정보까지 유지할 수 있도록 한다. 이렇게 함으로써 더이상 여러 scale값으로 anchor를 생성할 필요가 없게됐고
모두 동일한 scale의 anchor를 생성한다. 따라서 작은 feature map에서는 큰 anchor를 생성하여 큰 object를,
큰 feature map에서는 다소 작은 anchor를 생성하여 작은 object를 detect할 수 있도록 설계되었다.
마지막 layer에서의 feature map에서 이전 feature map을 더하는 것은 Upsampling을 통해 이루어진다.
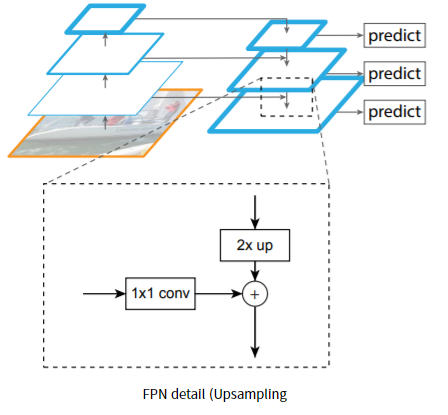
위 그림과 같이 먼저 2배로 upsampling을 한 후 이전 layer의 feature map을 1x1 Fully convolution 연산을 통해
filter개수를 똑같이 맞춰준후 더함으로써 새로운 feature map을 생성한다.
결과적으로 ResNet을 통해 C1, C2, C3, C4, C5 feature map을 생성하고 C1은 사용하지 않고
C5부터 F5, F4, F3, F2를 생성한다. 이때 F5에서 maxpooling을 통해 F6을 추가로 생선한다. (단지 경험상 좋다고한다)
최종적으로 F2, F3, F4, F5, F6 이렇게 5개의 feature map이 생성되는데 이때 F2~F5의 경우
RPN에 보내기전에 3x3 covolution 연산을 거친 후 보낸다. F2~F5는 upsampling과 이전 feature map을 더함으로써
feature data가 조금 망가졌을 수 있기에 3x3연산을 한 번 더해주는 것이다.
반면, F6은 F5에서 max pooling을 한 결과이므로 3x3연산을 하지않고 RPN에 그대로 전달된다.
RPN
위 과정을 통해 생성된 F2, F3, F4, F5, F6을 각각 RPN모델에 전달하는데 Faster R-CNN와 달리 이제 각 feature map에서
1개 scale의 anchor를 생성하므로 결국 각 pyramid feature map마다 scale 1개 x ratio 3개 = 3개의 anchor를 생성한다.
RPN의 동작과정은 생성하는 anchor의 개수가 달라진것 말고는 모두 동일하므로 생략한다.
RPN을 통해 output으로 classification값, bbox regression값이 나오는데 이때 bbox regression값은 delta값이다.

위 그림에서의 t값들, 즉 delta값을 output 으로 받게된다. 따라서 이 delta값에 anchor정보를 연산해서
원래 이미지에 대응되는 anchor bounding box 좌표값으로 바꿔주게 된다.
Non-max-suppression
원래 이미지에 anchor 좌표를 대응시킨 후에는 각각 normalized coordinate로 대응시킨다.
이는 fpn에서 이미 각기 다른 feature map크기를 갖고있기에 모두 통일되게 정규좌표계로 이동시키는 것이다.
이렇게 수천개의 anchor box가 생성되면 NMS알고리즘을 통해 anchor의 개수를 줄인다.
각 object마다 대응되는 anchor가 수십개 존재하는데 이때 가장 classification score가 높은 anchor를 제외하고
주위에 다른 anchor들은 모두 지우는 것이다.
NMS알고리즘은 anchor bbox들을 score순으로 정렬시킨 후 score가 높은 bbox부터 다른 bbox와 IoU를 계산한다.
이때 IoU가 해당 bbox와 0.7이 넘어가면 두 bbox는 동일 object를 detect한 것이라 간주하여 score가 더 낮은 bbox는
지우는 식으로 동작한다.
최종적으로 각 객체마다 score가 가장 큰 box만 남게되고 나머지 box는 제거한다.
RoI align
기존의 Faster R-CNN에서 RoI pooling은 object detection을 위한 모델이였기에
정확한 위치 정보를 담는것이 중요하지 않았다. 따라서 아래 그림과 같이 인접 픽셀들로 box를 이동시킨 후
pooling을 진행했다.
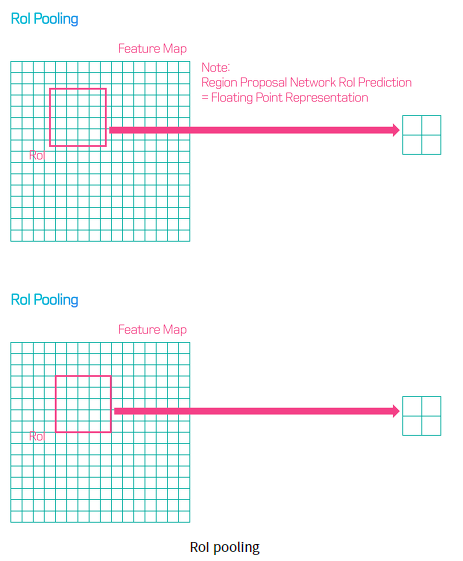
이렇게 RoI가 소수점 좌표를 가지면 좌표를 반올림하는 식으로 이동시킨후 pooling을 했는데
이러면 input image의 위치정보가 왜곡되기 때문에 segmentation에서는 문제가 된다.
따라서 bilinear interpolation을 이용해서 위치정보를 담는 RoI align을 이용한다.
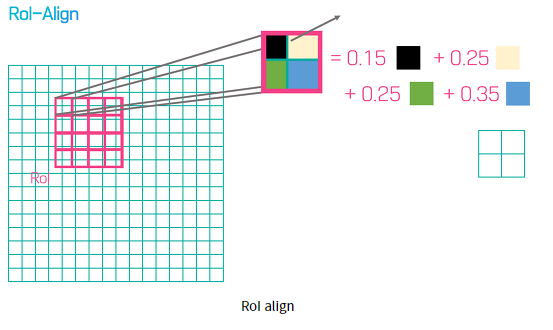
Loss function
Mask R-CNN은 2-stage 기법입니다. 첫 번째 stage는 RPN에서 RoI를 생성합니다. 두 번째 stage는 생성한 RoI를 이용하여 class, boxx offset, binary mask를 출력합니다. mask branch는 각 RoI에 대하여 Km^2 차원의 출력값을 생성합니다. K는 class의 수이고, m은 mask의 크기입니다. mask branch는 각 K class에 대해 출력값을 계산하고, class branch에서 출력한 class를 지닌 mask만 Loss를 계산합니다. 학습 동안에 각 RoI에 대하여 multi-task loss를 계산합니다.
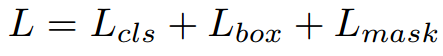
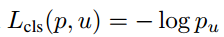
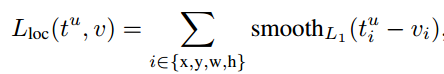
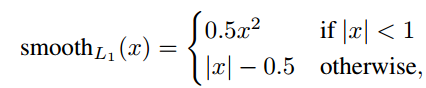
Lmask는 Crosss-entropy loss 입니다.
Lmask는 class branch에서 출력한 K class에 대해서만 loss를 계산합니다.
