Faster R-CNN
Introduction
R-CNN에서는 3가지 모듈 (region proposal, classification, bounding box regression)을 각각 따로따로 수행한다.
(1)region proposal 추출 → 각 region proposal별로 CNN 연산 → (2)classification, (3)bounding box regression
Fast R-CNN에서는 region proposal을 CNN level로 통과시켜 classification, bounding box regression을 하나로 묶었다.
(1)region proposal 추출 → 전체 image CNN 연산 → RoI projection, RoI Pooling → (2)classification, bounding box regression
그러나 여전히 region proposal인 Selective search알고리즘을 CNN외부에서 연산하므로 RoI 생성단계가 병목이다.
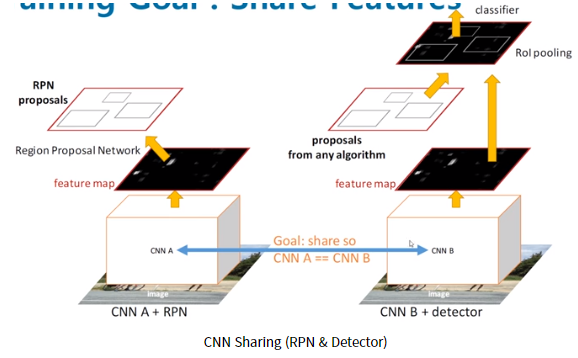
따라서 Faster R-CNN에서는 detection에서 쓰인 conv feature을 RPN에서도 공유해서
RoI생성역시 CNN level에서 수행하여 속도를 향상시킨다.
"Region Proposal도 Selective search 쓰지말고 CNN - (classification | bounding box regression)
이 네트워크 안에서 같이 해보자!"
Faster R-CNN
Selective search가 느린이유는 cpu에서 돌기 때문이다.
따라서 Region proposal 생성하는 네트워크도 gpu에 넣기 위해서 Conv layer에서 생성하도록 하자는게 아이디어이다.
Faster R-CNN은 한마디로 RPN + Fast R-CNN이라할 수 있다.
Faster R-CNN은 Fast R-CNN구조에서 conv feature map과 RoI Pooling사이에 RoI를 생성하는
Region Proposal Network가 추가된 구조이다.
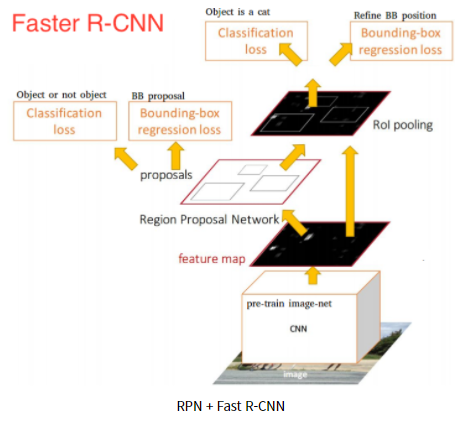
그리고 Faster R-CNN에서는 RPN 네트워크에서 사용할 CNN과
Fast R-CNN에서 classification, bbox regression을 위해 사용한 CNN 네트워크를 공유하자는 개념에서 나왔다.
결국 위 그림에서와 같이 CNN을 통과하여 생성된 conv feature map이 RPN에 의해 RoI를 생성한다.
주의해야할 것이 생성된 RoI는 feature map에서의 RoI가 아닌 original image에서의 RoI이다.
그래서 코드 상에서도 anchor box의 scale은 original image 크기에 맞춰서 (128, 256, 512)와 같이 생성하고 이 anchor box와 network의 output 값 사이의 loss를 optimize하도록 훈련시킨다.
따라서 original image위에서 생성된 RoI는 아래 그림과 같이 conv feature map의 크기에 맞게 rescaling된다.

이렇게 feature map에 RoI가 투영되고 나면 FC layer에 의해 classification과 bbox regression이 수행된다.
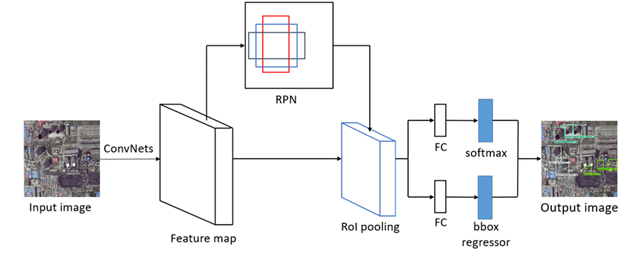
위 그림에서 보다시피 마지막에 FC layer를 사용하기에 input size를 맞춰주기 위해 RoI pooling을 사용한다.
RoI pooling을 사용하니까 RoI들의 size가 달라도 되는것처럼 original image의 input size도 달라도된다.
RPN (Region Proposal Network)

위 그림은 RPN의 개념을 시각적으로 보여주지만 실제 작동 방식은 보기보다 이해하기 어렵습니다. 좀 더 풀어서 그림으로 표현하면 아래와 같습니다.

RPN이 작동하는 알고리즘은 다음과 같습니다
- CNN을 통해 뽑아낸 피쳐 맵을 입력으로 받습니다. 이 때 피쳐맵의 크기를 H x W x C로 잡습니다. 각각 가로 x 세로 x 채널수 입니다.
- 피쳐맵에 3*3 컨볼루션을 256 혹은 512 채널만큼 수행합니다. 위 그림에서 intermediate layer에 해당합니다. 이 때 padding을 1로 설정해주어 H x W가 보존될 수 있도록 해줍니다. intermediate layer 수행 결과 H x W x 256 또는 H x W x 512 크기의 두 번째 피쳐 맵을 얻습니다.
- 두 번째 피쳐 맵을 받아서 classification과 bounding box regression 예측 값을 계산해주어야 합니다. 이 때 주의해야할 점은 Fully connected layer가 아니라 1*1 컨볼루션을 이용하여 계산하는 Fully connected network의 특징을 갖습니다. 이는 입력 이미지의 크기에 상관없이 동작할 수 있도록 하기 위함이며 자세한 내용은 Fully connected network 포스트에 기재하겠습니다.
- 먼저 classification을 수행하기 위해서 1*1 컨볼루션을(2[object인지 아닌지 나타내는 지표 수] x 9[앵커 수]) 채널 수 만큼 수행해주며 그 결과고 H x W x 18 크기의 피쳐맵을 얻습니다. H x W 상의 하나의 인덱스는 피쳐맵 상의 좌표를 의미하고, 그 아래 18개 채널은 각각 해당 좌표를 앵커로 삼아 k개의 앵커 박스들이 object인지 아닌지에 대한 예측 값을 담고 있습니다. 즉, 한번의 1 x 1 컨볼루션으로 H x W 개의 앵커 좌표들에 대한 예측을 모두 수행한 것입니다. 이제 이 값들을 적절히 reshape 해준 다음 softmax를 적용하여 해당 앵커가 오브젝트일 확률 값을 얻습니다.
- 두 번째는 bounding box regression 예측 값을 얻기 위해 1 x 1컨볼루션을 (4*9) 채널 수 만큼 수행합니다. 리그레션이기 때문에 결과로 얻은 값을 그대로 사용합니다.
- 이제 앞서 얻은 값들로 RoI를 계산합니다. 먼저 classification을 통해서 얻은 물체일 확률 값들을 정렬한 다음 높은 순으로 K개의 앵커만 추려냅니다. 그 다음 K개의 앵커들에 각각 bounding box regression을 적용해 줍니다. 그 다음 Non-maximum-suppression을 적용하여 RoI를 구해줍니다.
1x1 convolution 이란?
input 차원이 nxnx4라고 할때 1x1 convolution 2개를 이용하면 결국 input nxn짜리 4개에 대해 convolution 2개랑 아래와 같은 연산을 하는 것이다.

따라서 1x1 convolution은 fully connected layer와 같다고 한다.
다시 돌아와서 RPN에서 이렇게 1x1 convolution을 이용하여 classification과 bbox regression을 계산하는데
이때 네트워크를 가볍게 만들기 위해 binary classification으로 bbox에 물체가 있나 없나만 판단한다.
무슨 물체인지 classification하는 것은 마지막 classification 단계에서 한다.
RPN단계에서 classification과 bbox regression을 하는 이유는 결국 학습을 위함이다.
위 단계로부터 positive / negative examples들을 뽑아내는데 다음 기준에 따른다.
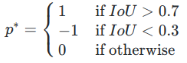
IoU가 0.7보다 크거나, 한 지점에서 모든 anchor box중 가장 IoU가 큰 anchor box는 positive example로 만든다.
IoU가 0.3보다 작으면 object가 아닌 background를 뜻하므로 negative example로 만들고
이 사이에 있는 IoU에 대해서는 애매한 값이므로 학습 데이터로 이용하지 않는다.
Loss Function
이제 RPN을 학습시키기 위해 손실함수를 알아보겠습니다. RPN은 앞서서 classification과 bounding box regression을 수행하였는데요 손실 함수는 이 두 가지 테스크에서 얻은 로스를 더한 형태입니다
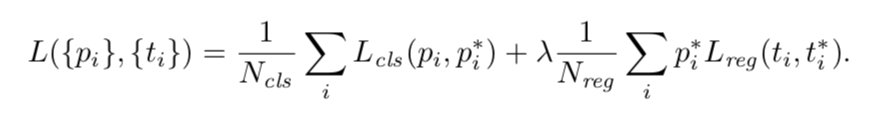
여기서 i는 하나의 앵커를 말합니다. pi는 classification을 통해서 얻은 해당 앵커가 오브젝트일 확률을 의미합니다. ti는 bounding box regression을 통해서 얻은 박스 조정 값 벡터를 의미합니다. pi과 ti은 ground truth 라벨에 해당합니다. classification은 이제 너무 익숙하게 사용하는 log loss를 통해서 계산합니다. regression loss의 경우 fast r-cnn에서 소개된 smooth L1 함수를 사용합니다.
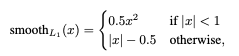
특이한 점은 각각 Ncls와 Nreg를 나누어 주는 부분이 있습니다. 이는 특별한 의미가 있는 것은 아니고 Ncls은 minibatch 사이즈이며 논문에서는 256입니다. Nreg는 앵커 개수에 해당하며 약 2400개(256 x 9)에 해당합니다. 람다는 classification loss와 regression loss 사이에 가중치를 조절해주는 부분인데 논무에서는 10으로 나와 있습니다. 사실상 두 로스는 동일하게 가중치가 매겨집니다.
