Qwen-2VL
Qwen-2VL은 Qwen 시리즈의 두 번째 비전-언어(Vision-Language) 모델로, 다양한 멀티모달 작업에서 뛰어난 성능을 발휘하는 모델입니다. Qwen 시리즈는 Alibaba Group의 연구소에서 개발한 대형 언어 모델(Large Language Model, LLM)로, 자연어 처리와 컴퓨터 비전 분야에서 활발히 활용되고 있습니다.
Qwen-2VL의 주요 특징:
-
멀티모달 학습:
- Qwen-2VL은 텍스트와 이미지를 동시에 처리할 수 있는 능력을 갖추고 있습니다. 이를 통해 이미지 캡셔닝, 시각적 질문 응답, 이미지 생성 등 다양한 멀티모달 작업을 수행할 수 있습니다.
-
거대 데이터 학습:
- 대규모의 이미지-텍스트 쌍 데이터셋을 학습하여, 다양한 시각적 정보를 이해하고 자연어로 표현할 수 있습니다.
-
고성능 아키텍처:
- Qwen-2VL은 Transformer 기반의 아키텍처를 사용하여 높은 연산 효율성과 성능을 자랑합니다. 또한, 멀티헤드 어텐션 메커니즘을 통해 이미지와 텍스트 간의 연관성을 효과적으로 학습합니다.
-
응용 가능성:
- Qwen-2VL은 다양한 산업 분야에 적용될 수 있습니다. 예를 들어, 전자상거래에서는 제품 이미지와 설명을 자동으로 생성하거나, 의료 분야에서는 의료 영상을 분석하고 관련 정보를 제공하는 데 사용될 수 있습니다.
-
오픈 소스:
- Qwen-2VL은 오픈 소스로 공개되어, 연구자나 개발자가 직접 모델을 활용하거나 수정하여 자신만의 응용 프로그램을 개발할 수 있습니다. 이 GitHub 리포지토리에는 모델 사용법, 학습 데이터, 예제 코드 등이 포함되어 있어 접근성이 높습니다.
요약:
Qwen-2VL은 강력한 비전-언어 모델로, 텍스트와 이미지를 결합한 다양한 작업에서 높은 성능을 발휘합니다. 오픈 소스로 제공되기 때문에 연구 및 개발에 매우 유용하며, 실제 응용 가능성이 높아 다양한 분야에서 활용될 수 있습니다.
Model Architecture
Qwen-2VL의 Model Architecture Updates는 이전 버전 대비 성능을 개선하고 효율성을 높이기 위해 도입된 여러 가지 중요한 아키텍처 개선 사항을 포함합니다. 이러한 업데이트는 모델이 더 나은 성능을 발휘하고 다양한 멀티모달 작업에서 효과적으로 대응할 수 있도록 설계되었습니다.
1. Cross-Modality Attention
- Cross-Modality Attention 메커니즘은 이미지와 텍스트 간의 상호작용을 강화하는 데 중점을 둡니다. 이 메커니즘은 이미지와 텍스트 사이의 상관 관계를 보다 깊이 이해할 수 있도록 설계되었으며, 이미지의 특정 부분과 텍스트의 특정 단어 사이의 연관성을 효율적으로 학습합니다.
- 이를 통해 Qwen-2VL은 이미지 캡셔닝과 같은 작업에서 텍스트와 이미지의 의미적 연관성을 더 정확하게 표현할 수 있습니다.
2. Enhanced Vision Encoder
- Qwen-2VL에서는 Vision Encoder가 강화되었습니다. Vision Encoder는 이미지 데이터를 처리하는 데 중요한 역할을 하며, Convolutional Neural Network(CNN)나 Vision Transformer(ViT)와 같은 최신 기술이 적용되었습니다.
- 이러한 강화된 인코더는 이미지의 세부적인 특징을 더 잘 추출하여, 텍스트와의 연관성을 높이는 데 기여합니다.
3. Unified Transformer Backbone
- Qwen-2VL은 텍스트와 이미지를 동일한 Transformer Backbone을 통해 처리합니다. 이는 텍스트와 이미지 데이터를 통합된 방식으로 처리하여 두 모달리티 간의 정보를 효과적으로 결합할 수 있게 해줍니다.
- 이 통합된 접근법은 모델의 효율성을 높이며, 특히 멀티모달 작업에서 성능을 크게 향상시킵니다.
4. Multi-Head Attention Mechanism
- Qwen-2VL에서는 Multi-Head Attention Mechanism이 더욱 정교하게 조정되었습니다. 이 메커니즘은 서로 다른 부분의 정보에 동시에 주의를 기울일 수 있어, 이미지와 텍스트 간의 상호작용을 더 잘 이해하게 됩니다.
- 특히, 다양한 모달리티 간의 상호 연관성을 파악하는 데 있어 매우 중요한 역할을 합니다.
5. Efficient Positional Encoding
- 모델은 Efficient Positional Encoding을 통해 텍스트와 이미지의 순서와 위치 정보를 효과적으로 반영합니다. 이러한 포지셔널 인코딩은 이미지 내의 객체 위치나 텍스트 내의 단어 순서를 정확하게 이해하도록 도와줍니다.
- 이로 인해 이미지와 텍스트 사이의 정교한 관계를 모델이 더 잘 파악할 수 있게 됩니다.
6. Advanced Pre-training Strategies
- Qwen-2VL은 보다 진보된 사전 학습 전략을 사용합니다. 이 모델은 다양한 데이터셋을 활용하여 사전 학습되었으며, 특히 대규모 이미지-텍스트 쌍 데이터셋을 통해 훈련되었습니다.
- 이러한 사전 학습 단계에서 모델은 다양한 시각적 및 언어적 개념을 미리 학습하여, 이후 다운스트림 작업에서 우수한 성능을 발휘할 수 있습니다.
7. Fine-Tuning Flexibility
- Qwen-2VL은 특정 작업에 맞게 미세 조정(Fine-Tuning)할 수 있는 유연성을 갖추고 있습니다. 사용자는 자신의 데이터셋에 맞게 모델을 쉽게 미세 조정할 수 있으며, 이를 통해 다양한 응용 프로그램에 최적화된 모델을 개발할 수 있습니다.
요약:
Qwen-2VL의 Model Architecture Updates는 크로스 모달리티 어텐션, 강화된 비전 인코더, 통합된 트랜스포머 백본, 다중 헤드 어텐션 메커니즘, 효율적인 포지셔널 인코딩, 진보된 사전 학습 전략, 미세 조정 유연성 등을 포함합니다. 이러한 업데이트를 통해 모델의 성능이 크게 향상되었으며, 다양한 멀티모달 작업에서 더 높은 효율성과 정확성을 제공합니다.
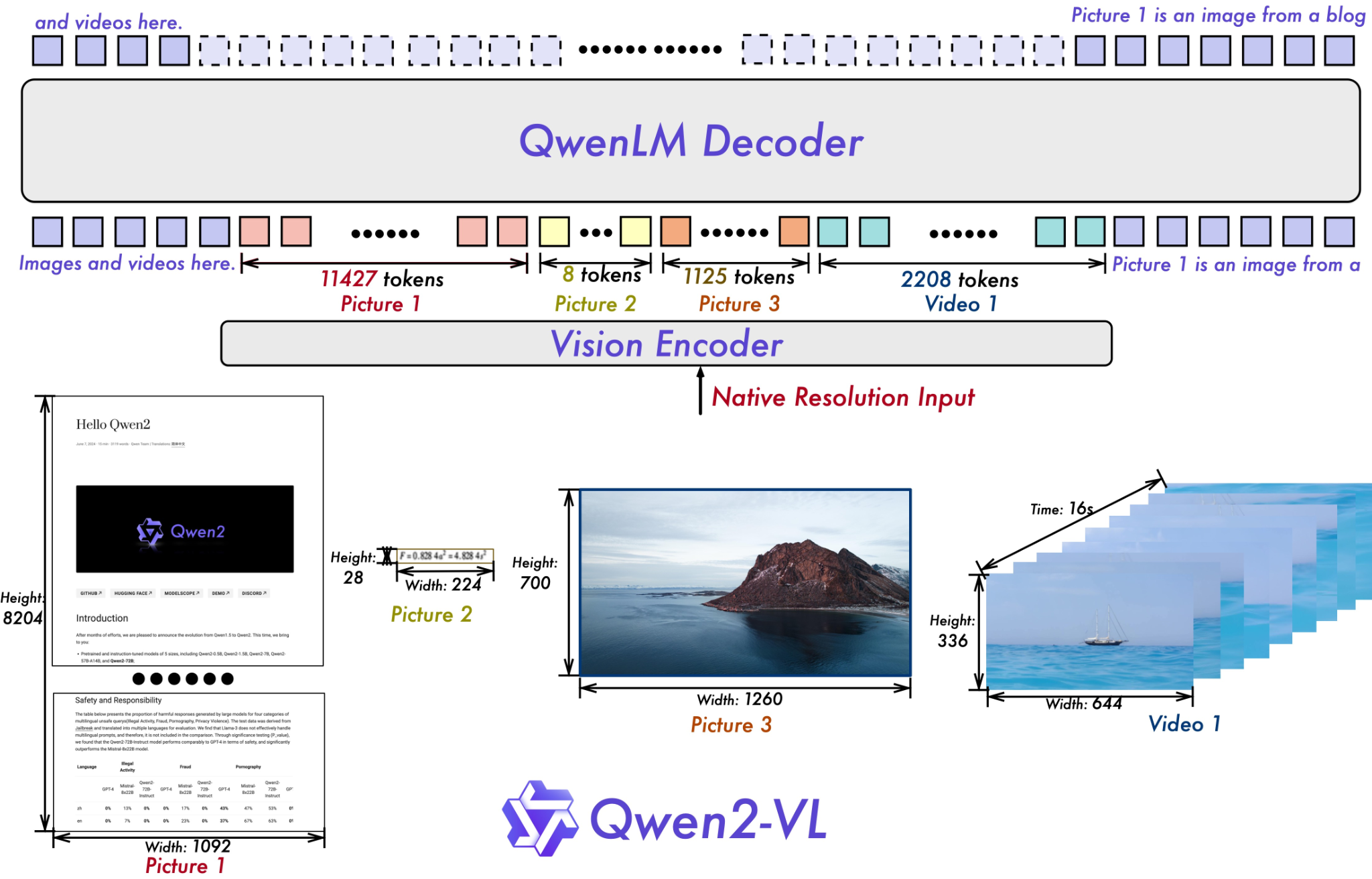
위 그림은 Qwen2-VL 모델의 아키텍처를 시각적으로 설명한 것입니다. 이 그림은 텍스트와 이미지, 비디오를 처리하는 전체 과정과 이를 어떻게 토큰화하여 모델에 입력하는지에 대한 설명을 담고 있습니다.
구성 요소별 설명:
-
Vision Encoder (비전 인코더):
- 그림 하단에 위치한 다양한 해상도의 이미지와 비디오가 입력으로 들어갑니다.
- 입력된 이미지와 비디오는 각각 고유의 해상도를 유지한 채로 비전 인코더에 의해 처리됩니다. 예를 들어,
Picture 1은 1092 x 8204의 해상도,Picture 2는 224 x 28의 해상도,Picture 3은 1260 x 700의 해상도를 가지며,Video 1은 644 x 336의 해상도와 16초의 길이를 가집니다. - 비전 인코더는 이러한 이미지를 처리하여 각각의 이미지 및 비디오 특징을 추출합니다. 이 과정에서 이미지와 비디오가 각각 여러 개의 토큰으로 변환됩니다.
-
Tokenization (토큰화):
- 비전 인코더에 의해 처리된 이미지와 비디오 데이터는 각각 토큰으로 변환됩니다. 예를 들어,
Picture 1은 11427개의 토큰으로,Picture 2는 8개의 토큰으로,Picture 3은 1125개의 토큰으로,Video 1은 2208개의 토큰으로 변환됩니다. - 토큰화된 데이터는 QwenLM 디코더로 전달됩니다.
- 비전 인코더에 의해 처리된 이미지와 비디오 데이터는 각각 토큰으로 변환됩니다. 예를 들어,
-
QwenLM Decoder (QwenLM 디코더):
- 토큰화된 이미지와 비디오 데이터가 QwenLM 디코더에 입력됩니다. 디코더는 텍스트와 비주얼 데이터 간의 상호작용을 통해 의미를 이해하고 최종 출력을 생성합니다.
- 디코더는 텍스트, 이미지, 비디오의 복합 데이터를 함께 처리하며, 이 과정에서 다양한 텍스트와 비주얼 정보가 결합되어 높은 수준의 의미를 학습하고 표현하게 됩니다.
-
Native Resolution Input (원본 해상도 입력):
- 비전 인코더는 입력되는 이미지와 비디오의 원본 해상도를 그대로 유지하여 처리합니다. 이는 이미지의 세부 사항을 더 정확하게 반영할 수 있게 해줍니다.
결론:
이 그림은 Qwen2-VL 모델이 텍스트와 이미지를 어떻게 처리하고 학습하는지를 보여줍니다. 비전 인코더는 다양한 해상도의 이미지와 비디오를 처리하여 토큰으로 변환하고, QwenLM 디코더는 이를 바탕으로 복합적인 멀티모달 데이터를 이해하고 출력하는 역할을 합니다. 각 입력 데이터의 해상도와 토큰 수가 각각 다르며, 이를 통해 모델이 다양한 시각 정보를 효과적으로 처리할 수 있음을 알 수 있습니다.
Qwen-2VL GitHub 리포지토리에서 추가 정보를 확인할 수 있습니다.
