Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection
개방형 객체 검출에 관한 연구로, 인간 언어 입력(예: 카테고리 이름 또는 참조 표현)을 사용하여 임의의 객체를 검출할 수 있는 모델인 Grounding DINO를 제안합니다. 이 모델은 Transformer 기반 DINO 검출기를 기반으로 하여 언어와 시각 정보의 긴밀한 결합을 통해 개방형 객체 검출을 가능하게 합니다.
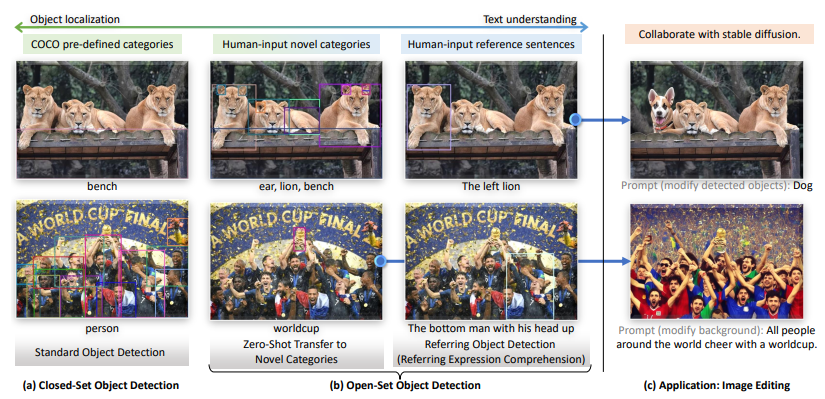
주요 내용:
언어와 시각 정보의 융합을 통해, 사전에 정의된 카테고리가 없는 새로운 객체를 인식할 수 있도록 설계되었습니다.
모델은 COCO, LVIS, ODinW, RefCOCO 등의 다양한 벤치마크에서 뛰어난 성능을 보였으며, 특히 COCO zero-shot 검출 벤치마크에서 52.5 AP를 기록하였습니다.
세 가지 주요 단계에서 언어와 시각 정보를 결합하는 방법을 사용하여, 모델의 객체 검출 능력을 크게 향상시켰습니다.
이 논문은 또한 Stable Diffusion과 결합하여 이미지 편집 등 다양한 응용 프로그램에 적용할 수 있음을 보여줍니다.
요약:
Grounding DINO는 언어 입력을 사용해 개방형 환경에서 새로운 객체를 탐지할 수 있도록 설계된 모델입니다. 이는 기존 폐쇄형 검출 모델에서 언어 정보를 융합하여 개방형 객체 검출로 확장된 형태로, 다양한 벤치마크에서 탁월한 성능을 입증했습니다.
1. Introduction
이 논문은 인공지능의 개방형 객체 검출 능력을 증대시키는 방법을 탐구합니다. Grounding DINO라는 모델을 제안하며, 이는 인간의 언어 입력(예: 카테고리 이름 또는 표현)을 통해 임의의 객체를 검출할 수 있는 능력을 가지고 있습니다. 기존의 폐쇄형 객체 검출기를 개방형 객체 검출기로 확장하는 주요 아이디어는 언어 정보를 시각 정보와 긴밀하게 융합하는 것입니다.
Grounding DINO는 Transformer 기반 DINO 모델에 기반하여 설계되었으며, 대규모의 사전 훈련된 데이터를 통해 다양한 개념을 학습합니다. 이 모델은 특히 새로운 객체를 검출하는 능력을 크게 향상시키며, COCO, LVIS, ODinW 등 다양한 벤치마크에서 우수한 성능을 보였습니다 .
이러한 접근 방식은 다양한 응용 프로그램, 특히 이미지 편집 및 참조 객체 검출(Referring Expression Comprehension, REC)에서도 활용될 수 있습니다 .
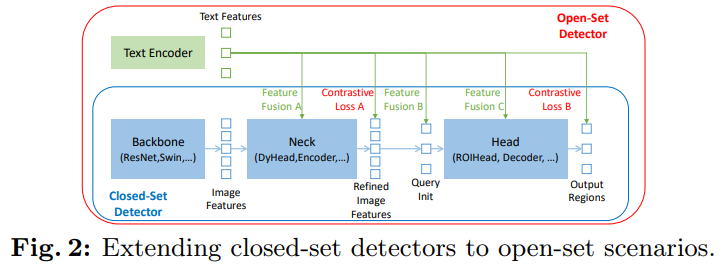
Fig. 2는 폐쇄형 객체 검출기를 개방형 객체 검출기로 확장하는 방법을 설명합니다. 이 그림은 폐쇄형 객체 검출기의 세 가지 주요 모듈과 그 확장 방식을 시각적으로 나타냅니다:
Backbone: 이미지에서 특징을 추출하는 단계입니다. 일반적으로 ResNet이나 Swin과 같은 네트워크 구조가 사용됩니다.
Neck: 특징을 증강하는 단계입니다. 이 단계에서는 DyHead나 Transformer Encoder 등이 사용됩니다.
Head: 마지막으로 객체의 영역을 정제하고 박스를 예측하는 단계입니다. 이 단계에서는 ROIHead나 Decoder가 사용됩니다.
개방형 객체 검출기는 여기에 언어 정보를 추가하여, 새로운 객체를 일반화할 수 있도록 합니다. 이를 위해, 세 가지 단계에서 언어와 시각 정보의 융합이 일어나며, 이를 통해 각 영역에서 새로운 객체를 검출할 수 있게 됩니다:
Phase A: Neck 단계에서 특징을 융합.
Phase B: Query 초기화 단계에서 언어를 기반으로 특징을 선택.
Phase C: Head 단계에서 언어와 시각 정보를 결합하여 객체 영역을 예측.
2. Related Work
Related Work 섹션에서는 개방형 객체 검출 및 Transformer 기반 객체 검출기에 대한 기존 연구들을 설명합니다. Grounding DINO는 이러한 연구들에 기초하여 개발되었습니다.
Detection Transformers: Grounding DINO는 DETR(Detection Transformer) 계열 모델인 DINO를 기반으로 하고 있습니다. DETR은 처음으로 Transformers를 사용한 객체 검출을 제안한 모델로, 이후 DAB-DETR(앵커 박스 도입)과 DN-DETR(쿼리 안정화 기술 도입) 등의 다양한 개선된 모델들이 등장했습니다. 하지만 이러한 모델들은 폐쇄형 객체 검출에 초점을 맞추고 있어 새로운 클래스를 인식하기 어렵다는 한계가 있습니다.
Open-Set Object Detection: 개방형 객체 검출은 언어 정보의 일반화를 통해 기존의 경계 상자 주석을 사용하여 임의의 클래스를 탐지할 수 있도록 훈련된 모델입니다. 예를 들어, OV-DETR은 CLIP 모델을 사용하여 이미지와 텍스트 임베딩을 쿼리로 활용해 특정 카테고리의 객체를 추출합니다. ViLD는 CLIP 모델을 R-CNN과 결합하여 언어와 영역 임베딩을 학습시키는 방법을 사용합니다.
Grounding DINO는 이러한 연구들을 발전시켜 언어와 시각 정보를 더 깊이 융합하고, zero-shot 검출 성능을 향상시키는 것을 목표로 합니다.
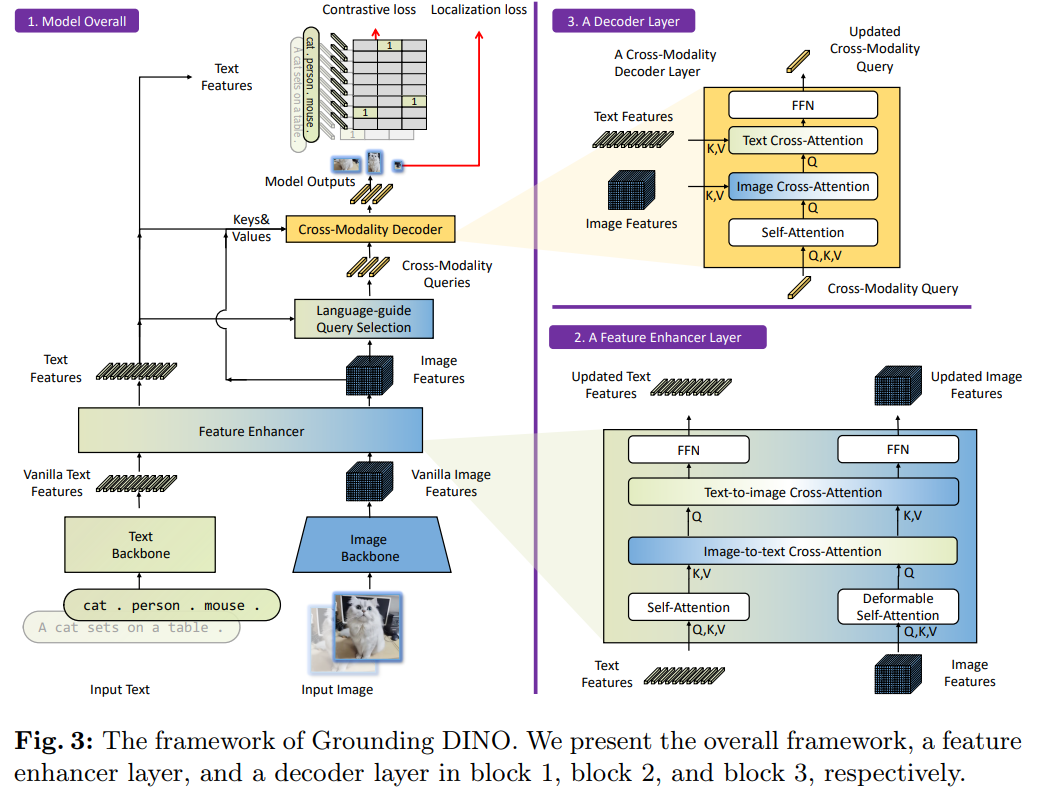
Fig. 3는 Grounding DINO 모델의 전체적인 구조와 각 레이어(층)의 작동 방식을 시각적으로 설명한 그림입니다. 이 그림은 세 가지 주요 구성 요소로 나뉩니다:
모델 전체 구조(Overall Model):
입력으로 이미지와 텍스트를 받아서 객체 검출 결과를 출력합니다.
이미지를 처리하는 이미지 백본(Image Backbone)과 텍스트를 처리하는 텍스트 백본(Text Backbone)이 각각 존재하며, 이를 결합하기 위해 Feature Enhancer(특징 강화기)와 Cross-Modality Decoder(크로스 모달리티 디코더)를 사용합니다.
최종적으로 모델은 이미지에서 객체를 검출하고, 해당 객체에 맞는 텍스트 레이블을 출력합니다.
Feature Enhancer Layer(특징 강화 레이어):
이 레이어는 이미지를 self-attention과 image-to-text cross-attention 및 text-to-image cross-attention을 통해 강화된 특징으로 변환합니다.
이미지와 텍스트 간의 특징을 교환하며, 이를 통해 두 모달리티(이미지와 텍스트) 간의 일관된 표현을 학습할 수 있습니다.
Cross-Modality Decoder Layer(크로스 모달리티 디코더 레이어):
이 레이어는 자기 주의(Self-Attention), 이미지 교차 주의(Image Cross-Attention), 텍스트 교차 주의(Text Cross-Attention)를 통해 크로스 모달리티 쿼리를 처리합니다.
텍스트와 이미지 정보를 결합하여 각 쿼리의 표현을 업데이트하고, 이를 통해 객체 박스를 예측하고 관련된 텍스트 레이블을 추출합니다.
3. Grounding DINO
- Grounding DINO 섹션에서는 Grounding DINO 모델의 작동 원리를 설명합니다. 이 모델은 이미지와 텍스트 입력을 통해 객체를 감지하고, 이 객체들과 관련된 명사 구를 출력하는 방식으로 작동합니다. 예를 들어, 주어진 이미지에서 고양이와 테이블을 찾아내고, 텍스트 입력에서 이 두 단어를 추출하여 레이블로 연결합니다 .
Grounding DINO는 듀얼 인코더-싱글 디코더 아키텍처로 구성되어 있습니다. 이 아키텍처는 다음과 같은 주요 모듈들로 이루어져 있습니다:
- 이미지 백본(Image Backbone): 이미지의 특징을 추출.
- 텍스트 백본(Text Backbone): 텍스트의 특징을 추출.
- 특징 강화 모듈(Feature Enhancer): 이미지와 텍스트 특징을 융합.
- 언어 기반 쿼리 선택(Language-guided Query Selection): 객체 검출 쿼리를 초기화.
- 크로스 모달리티 디코더(Cross-Modality Decoder): 이미지와 텍스트 정보를 결합하여 객체 박스를 정제.
이러한 구조를 통해 Grounding DINO는 주어진 텍스트와 일치하는 객체를 이미지에서 찾아내고, 다양한 객체 검출 및 참조 객체 탐지(REC) 작업을 수행할 수 있습니다.
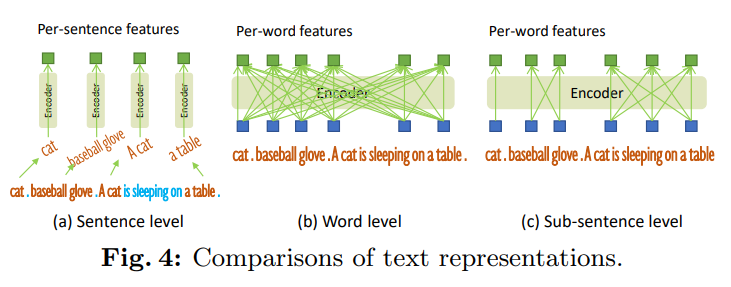
Fig. 4는 텍스트 표현 방식에 대한 비교를 설명하는 그림입니다. 이 그림은 세 가지 텍스트 표현 방법을 보여주며, 각각의 방식이 문장 내 단어들이 어떻게 처리되는지에 따라 다릅니다:
문장 수준 표현(Sentence Level Representation):
전체 문장을 하나의 특징으로 인코딩합니다.
이 방식은 문장의 의미를 포괄적으로 표현할 수 있지만, 세부적인 단어 간의 차이나 상호작용을 반영하지 못할 수 있습니다.
단어 수준 표현(Word Level Representation):
문장을 구성하는 개별 단어들을 각각의 특징으로 인코딩합니다.
이 방식은 여러 카테고리 이름을 하나의 텍스트로 인코딩할 수 있지만, 단어들 간의 불필요한 상호작용이 발생할 수 있습니다. 예를 들어, 서로 관련이 없는 단어들이 함께 학습되면서 상호작용할 수 있습니다.
서브 문장 수준 표현(Sub-Sentence Level Representation):
단어들 간의 불필요한 상호작용을 방지하기 위해 어텐션 마스크를 사용하여, 카테고리 이름들 간의 상호작용을 차단합니다.
이를 통해 각 단어의 특징을 세밀하게 유지하면서도, 불필요한 상호작용을 줄여 정교한 표현을 얻을 수 있습니다.
