Vision Transformer(ViT)는 CV(Computer Vision) 분야에 Transformer를 적용하여 객체 탐지 및 이미지 분류 등의 분야에서 뛰어난 성능을 보이는 모델입니다. 특히 이미지로부터 특징(feature)을 추출하는 Visual Encoder로써 많이 사용되고 있습니다.
Vision Transformer(ViT)에 대한 시각적 설명
이 글은 이미지 분류 작업에서 최첨단(SotA, State-of-the-Art)의 성능을 보이는 딥러닝 모델인 Vision Transformers(ViTs)에 대한 시각적 설명 글입니다. Vision Transformer는 원래 자연어 처리(NLP)를 위해 설계된 Transformer 아키텍처를 이미지 데이터 적용한 것입니다. 이 글에서는 데이터의 흐름을 이해하는데 도움이 되는 시각화와 함께 간단한 설명을 통해 Vision Transformer의 동작 방식을 이해할 수 있도록 합니다.
아래의 링크로 가시면 스크롤로 내리면서 이미지로 이해하기 쉽게 설명되어 있습니다. 이 글에서는 대략적인 설명만 하겠습니다. 자세한 사항은 아래 링크를 참조하세요.
https://blog.mdturp.ch/posts/2024-04-05-visual_guide_to_vision_transformer.html?utm_source=pytorchkr
0. 데이터 살펴보기

일반적인 합성곱 신경망(CNN)과 마찬가지로 Vision Transformer도 지도 학습(Supervised Learning) 방식으로 학습합니다. 즉, 이미지와 이에 맞는 레이블(label)로 구성된 데이터셋으로 모델이 학습합니다.
1. 데이터 하나만 집중해서 보기

Vision Transformer가 내부적으로 어떻게 동작하는지 알아보기 위해, 하나의 데이터(배치 크기 1)에 대해서만 먼저 집중해보겠습니다. 그리고 이 질문을 함께 생각해보시죠: Transformer에 이 데이터를 입력하기 위해서는 어떻게 준비(전처리)해야 할까요?
2. 레이블은 잠시 치워두기

레이블은 나중에 더 관련성있게 살펴보겠습니다. 지금은 이미지 하나만 남겨놓고 보겠습니다.
3. 이미지를 패치로 쪼개기

전체 이미지를 동일한 크기의 패치(p x p) 이미지로 나누어 Transformer 내부에서 사용할 수 있도록 준비합니다.
4. 이미지 패치들을 평탄화하기

패치들을 p' = p² x c 크기의 벡터로 평탄화(flaten)합니다. 이 때 p는 패치의 한 변의 크기이고, c는 채널 수입니다.
5. 패치로부터 임베딩 만들기
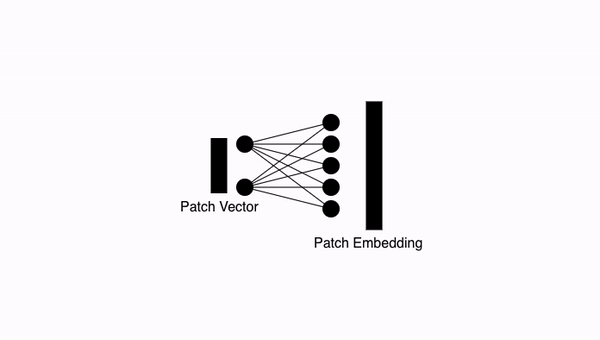
앞에서 이미지 패치로부터 만든 벡터들을 선형 변환을 통해 인코딩합니다. 이렇게 만들어진 패치 임베딩 벡터(Patch Embedding Vector) 는 고정된 크기 d를 갖습니다.
6. 모든 패치들을 임베딩하기

이미지 패치들을 모두 고정된 크기의 벡터로 임베딩하게 되면 n x d 크기의 배열을 얻게 됩니다. 여기서 n은 이미지 패치의 개수이고, d는 하나의 패치가 임베딩된 크기입니다.
7. 분류 토큰(CLS) 추가하기

모델을 효과적으로 학습하기 위해, 패치 임베딩에 추가로 분류 토큰(CLS token)이라 부르는 벡터를 추가합니다. 이 벡터는 신경망을 통해 학습 가능한 매개변수로, 무작위로 초기화됩니다. 참고로, CLS 토큰은 하나만 있으며, 모든 데이터들에 동일한 벡터를 추가합니다.
8. 위치 임베딩 벡터 추가하기
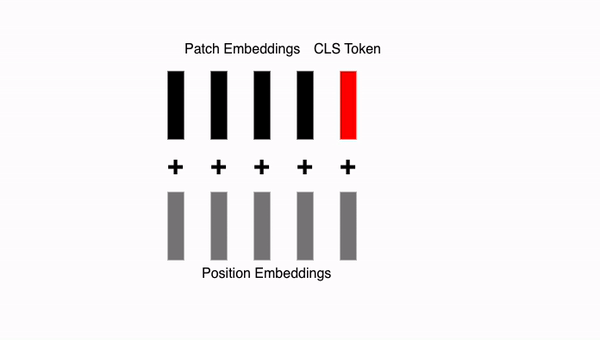
지금까지의 패치 임베딩에는 별도의 위치 정보가 없습니다. 모든 패치 임베딩에 학습 가능한, 무작위로 초기화된 위치 임베딩 벡터(Positional Embedding Vector) 를 더하여 이 문제를 해결합니다. 또한, 앞에서 추가한 분류 토큰(CLS token) 에도 이러한 위치 벡터를 추가합니다.
9. Transformer에 입력하기
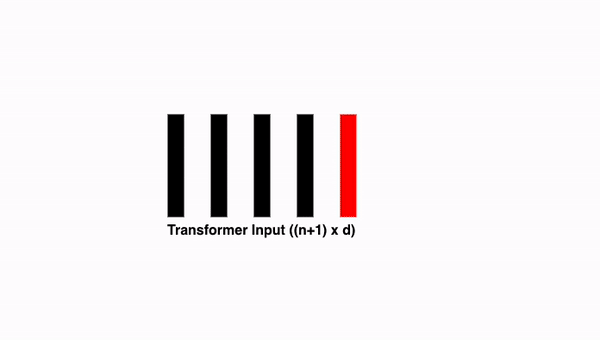
위치 임베딩 벡터를 추가하면 (n+1) x d 크기의 배열이 남습니다. 이 배열을 Transformer의 입력으로 제공할 것이며, 이에 대해서는 다음 단계에서 더 자세히 설명하겠습니다.
10.1. Transformer: QKV 만들기

Transformer 입력 패치 임베딩 벡터는 여러 큰 벡터에 선형적으로 임베딩됩니다. 이러한 새로운 벡터는 동일한 크기의 세 부분으로 분리됩니다. 이는 각각 Q는 쿼리(Query) 벡터, K는 키(Key) 벡터, V는 값(Value) 벡터입니다. 모든 벡터들을 (n+1)개씩 얻게 됩니다.
10.2. Transformer: 어텐션 스코어 계산하기

먼저 어텐션 스코어 A를 계산하기 위해 모든 쿼리 벡터 Q에 모든 키 벡터 K를 곱합니다.
10.3. Transformer: 어텐션 스코어 매트릭스
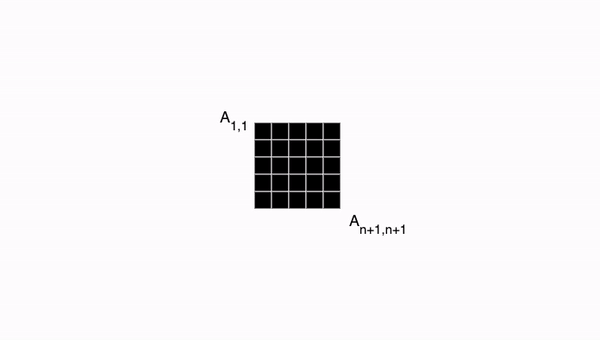
이렇게 얻은 어텐션 스코어 행렬 A의 모든 행의 합이 1이 되도록 모든 행에 softmax 함수를 적용합니다.
10.4. Transformer: 집계된 컨텍스트 정보 계산하기

첫 번째 패치 임베딩 벡터에 대한 집계된 문맥 정보(aggregated contextual information) 를 계산하기 위해, 어텐션 행렬의 첫 번째 행에 대해서 연산을 합니다. 여기에 값 벡터 V의 가중치를 사용하여 첫 번째 이미지 패치 임베딩에 대한 집계된 문맥 정보 벡터(aggregated vector) 를 생성합니다.
10.5. Transformer: 모든 패치에 대해서 집계된 컨텍스트 정보 구하기

어텐션 스코어 행렬의 다른 행들에 대해서도 위 과정을 반복하여 N+1개의 집계된 문맥 정보 벡터를 구합니다. 즉, 모든 패치마다 하나씩 (=N개) + 분류 토큰(CLS Token)에 대해서 하나 (=1) 입니다. 여기까지 해서 첫번째 어텐션 헤드(Attention Head)를 구합니다.
10.6. Transformer: 멀티-헤드 어텐션

(Transformer의) 멀티-헤드 어텐션을 다루고 있으므로, 다른 QKV들에 대해서 10.1부터 10.5까지의 전체 프로세스를 반복합니다. 위 그림에서는 2개의 헤드만 가정했지만, 일반적으로 ViT는 더 많은 헤드를 갖습니다. 이렇게 여러 개의 집계된 문맥 정보 벡터(Multiple Aggregated Contextual Information Vectors)가 생성됩니다.
10.7. Transformer: 마지막 어텐션 레이어 단계
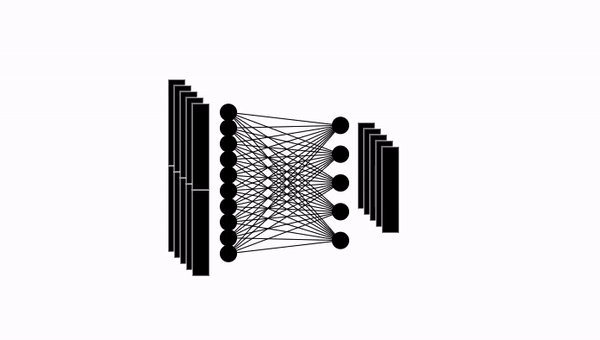
이렇게 생성한 여러 헤드들을 쌓은 뒤, 패치 임베딩의 크기와 같은 d 크기의 벡터로 매핑시킵니다.
10.8. Transformer: 어텐션 레이어 결과 구하기
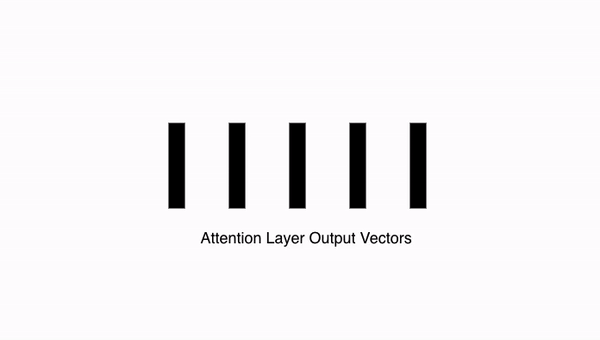
이렇게 이전 단계로부터 어텐션 레이어가 완성되었고, 입력 시에 사용했던 것과 정확히 같은 크기의 임베딩들을 얻었습니다.
10.9. Transformer: 잔차 연결하기
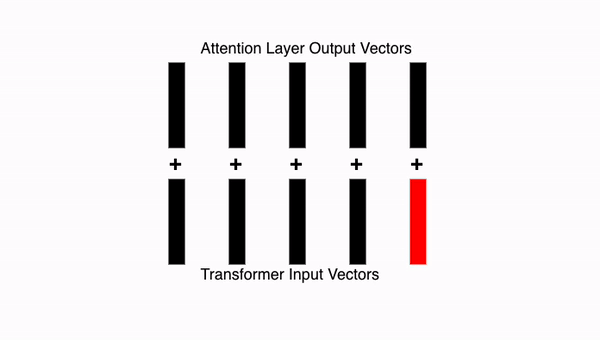
Transformer에서는 잔차 연결(Residual Connection) 을 많이 사용하는데, 이것은 단순히 이전 레이어의 입력을 현재 레이어의 출력에 더해주는 것입니다. 여기서도 잔차 연결을 하겠습니다.
10.10. Transformer: 잔차 연결 결과 구하기
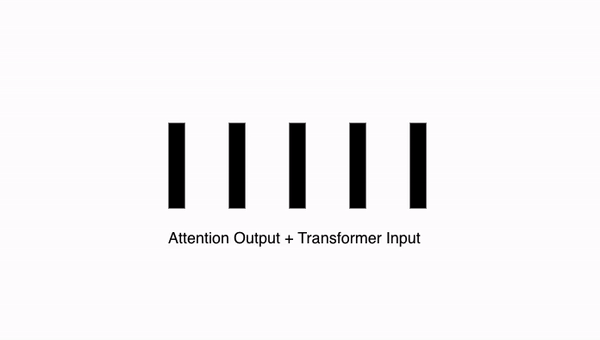
이러한 잔차 연결을 통해 (동일한 크기 d인 벡터들끼리 더하여) 같은 크기의 벡터가 생성됩니다.
10.11. Transformer: 피드-포워드 네트워크에 통과시키기

지금까지의 결과(output)를 비선형 활성함수를 갖는 피드 포워드 인공 신경망에 통과시킵니다.
10.12. Transformer: 최종 결과 구하기
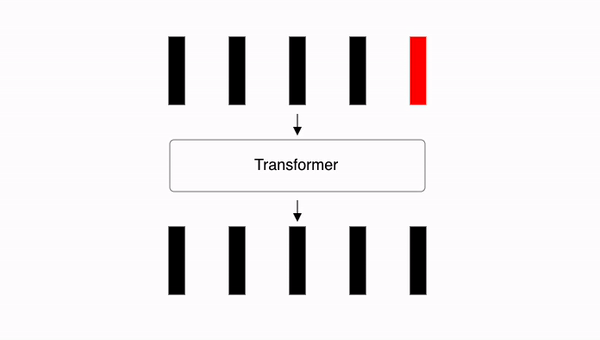
Transformer에는 지금까지 연산 이후로 또다른 잔차 연결이 있지만, 여기서는 설명을 간소화하기 위해 건너뛰고 Transformer 레이어 연산을 마무리하겠습니다. 최종적으로 Transformer는 입력 크기와 같은 출력을 생성합니다.
Transformer 연산 반복하기
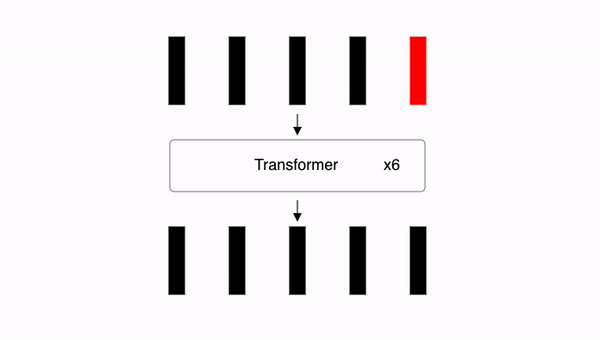
지금까지 진행한 10.1부터 10.12까지의 전체 Transformer 연산을 수차례 반복합니다. 여기에서는 6번을 예시로 들었습니다.
12. 분류 토큰 출력 확인하기

마지막 단계는 분류 토큰(CLS token) 출력을 확인하는 것입니다. 이벡터는 Vision Transformer 여정의 마지막 단계에서 사용하게 됩니다.
13. 최종 단계: 분류 확률 예측하기
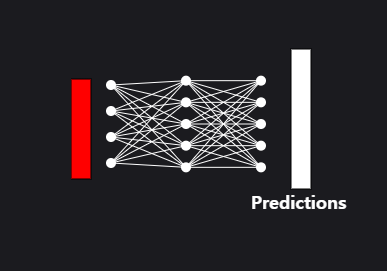
최종적이고 마지막 단계에서는 분류 출력 토큰을 완전 연결(fully-connected)된 또 다른 인공 신경망에 통과시켜 입력 이미지에 대한 분류 확률(classification probabilties)을 예측합니다.
14. Vision Transformer 학습하기
앞에서 예측한 분류 확률(class probabilties)과 정답(true class label)을 비교하는 표준 크로스-엔트로피 손실 함수(Cross-Entropy Loss Function)을 사용하여 Vision Transformer를 학습합니다. 모델은 역전파(backpropagation) 및 경사 하강법(gradient descent)을 사용하여 손실 함수를 최소화하는 쪽으로 모델의 가중치를 갱신하며 학습합니다.
