
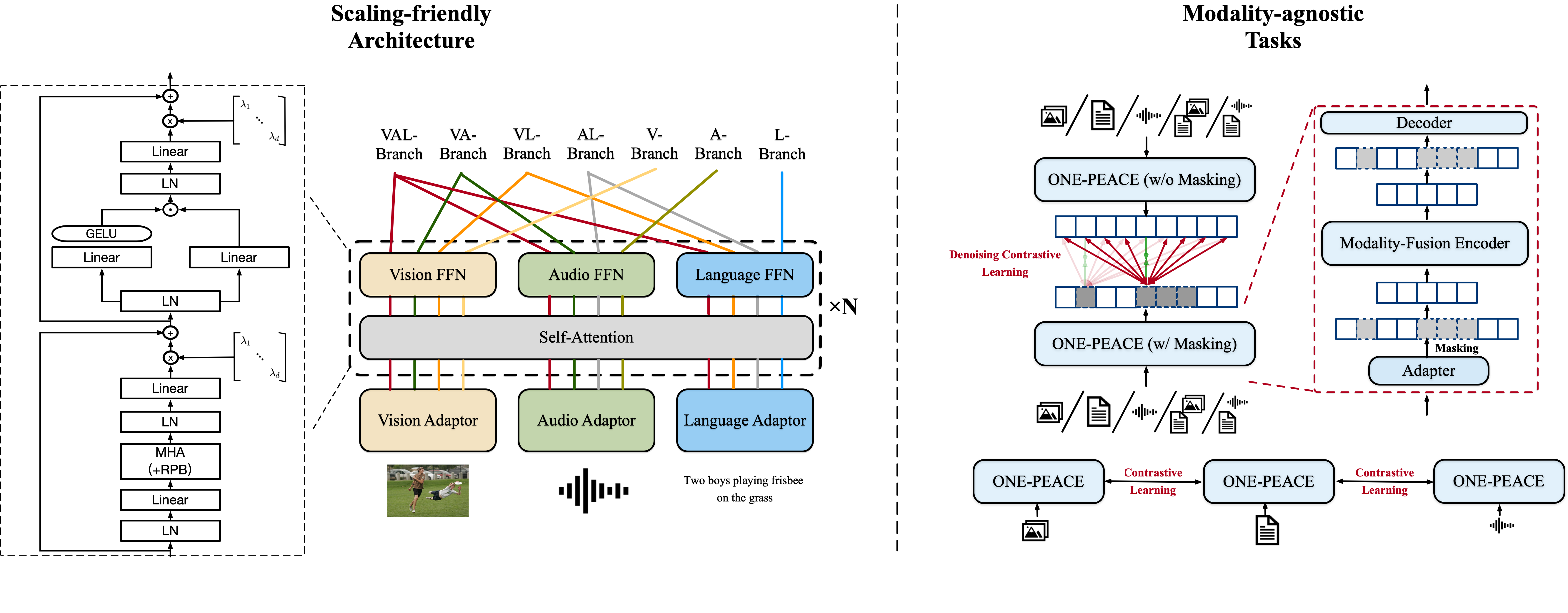
- 비젼, 오디오, 언어 모달리티를 모두 아우르는 General Represenation Model
- 사전학습된 모델 없이도 통합된 작업들에 훌륭한 결과를 냄
- 강력한 Emergent Zero-shot Retrieval로 훈련 데이터에서 페어링 되지 않은 모달리티를 얼라인 가능
- Audio-to-Image, Audtio+Text-to-Image, Audio+Image-to-Image

따라가기도 벅찬 AI Engineer 겸 부앙단
- 비젼, 오디오, 언어 모달리티를 모두 아우르는 General Represenation Model
- 사전학습된 모델 없이도 통합된 작업들에 훌륭한 결과를 냄
- 강력한 Emergent Zero-shot Retrieval로 훈련 데이터에서 페어링 되지 않은 모달리티를 얼라인 가능
- Audio-to-Image, Audtio+Text-to-Image, Audio+Image-to-Image