nanoVLM: 순수 PyTorch로 구현한 초경량 비전-언어 모델
nanoVLM 소개
Hugging Face가 최근 공개한 nanoVLM은 단 750줄의 순수 PyTorch 코드로 구성된 초경량 비전-언어 모델입니다. 복잡한 종속성이나 무거운 프레임워크 없이, 단일 GPU에서도 학습 가능한 이 프로젝트는 비전-언어 모델 구조를 처음부터 끝까지 이해하고자 하는 분들에게 매우 훌륭한 학습 자료입니다. 특히 Andrej Karpathy의 nanoGPT에서 영감을 받아 설계되었으며, 연구 및 실험 중심의 멀티모달 학습에 적합합니다.
nanoVLM은 이미지와 텍스트라는 서로 다른 두 모달리티를 동시에 처리할 수 있는 비전-언어 모델(Vision-Language Model, VLM)을 단순한 구조로 구현한 프로젝트입니다. Hugging Face의 연구원들이 개발했으며, 교육 목적은 물론, 실험과 커스터마이징이 쉬운 베이스라인 모델을 제공합니다.
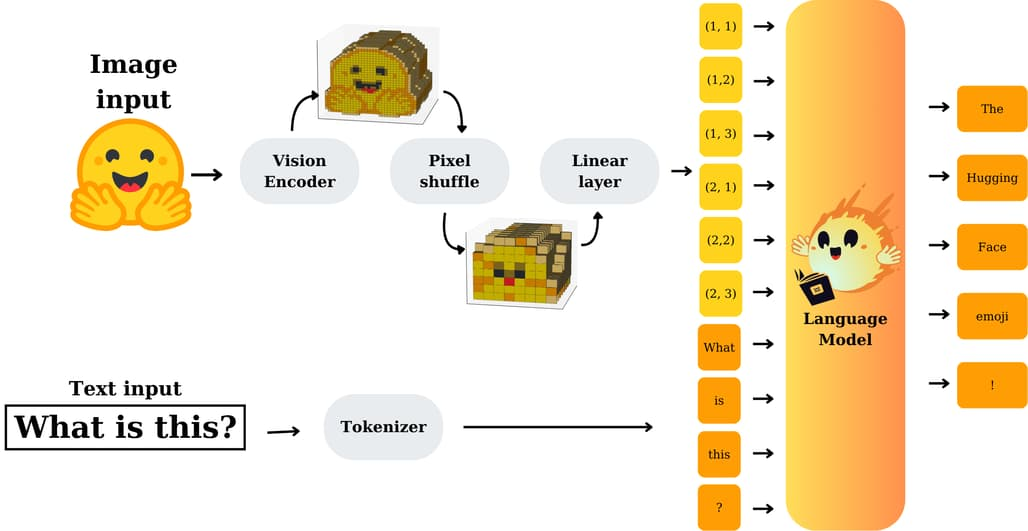
nanoVLM 프로젝트는 다음과 같은 철학을 기반으로 설계되었습니다:
- 읽기 쉽고 간결한 구조: 전체가 약 750줄의 PyTorch 코드로 작성되어 있어, 초보자도 모델 구조를 파악하기 용이합니다.
- 모듈화된 설계: Vision Encoder, Text Decoder, 그리고 이 둘을 연결하는 Projection Layer가 깔끔하게 분리되어 있어, 실험에 유연하게 대응할 수 있습니다.
- 학습 친화적인 구성: 222M 파라미터의 모델을 기준으로 H100 GPU 하나로 약 6시간이면 학습이 완료됩니다. 사용된 데이터셋은 공개된 Multimodal-Instructions-1.1이며, 약 170만 개의 샘플을 포함합니다.
특히 모델 아키텍처 자체가 실용성과 직관성을 고려해 구성되어 있기 때문에, 기존 VLM 구조를 학습하고 싶은 분들에게 최적입니다. 기존 VLM은 성능 면에서 우수하지만, 대부분 코드나 학습 과정이 비공개이거나 너무 복잡하여 실험에 부적합합니다. 반면 nanoVLM은 초경량 구조를 통해 학습 진입 장벽을 대폭 낮춘 것이 특징입니다.
nanoVLM의 주요 기능
- 간결한 PyTorch 구현: 모델 정의부터 학습까지 전체 로직이 단일 프로젝트 안에서 정리되어 있어 파악이 빠릅니다.
- 모듈화 아키텍처 :
- Vision Encoder: CLIP에서 가져온 ResNet 계열 구조
- Language Decoder: GPT 스타일의 Transformer 디코더
- Projection Layer: modality간 연결을 위한 선형 변환 - 빠른 학습: 단일 H100 GPU에서 1.7M 샘플 학습에 약 6시간 소요
- 실험 성능: MMStar 벤치마크에서 35.3% 정확도 달성 (222M 기준)
- 검증된 사전학습 모델 제공: Hugging Face Hub에서 lusxvr/nanoVLM-222M를 사용할 수 있음
모델 구조
-
Vision Backbone (models/vision_transformer.py, ≈150줄)
-
Language Decoder (models/language_model.py, ≈250줄)
-
Modality Projection (models/modality_projection.py, ≈50줄)
-
VLM 통합 (models/vision_language_model.py, ≈100줄)
-
학습 루프 (train.py, ≈200줄)
이처럼 모듈별로 분리되어 있어, 원하는 부분만 쉽게 수정하거나 교체하며 실험할 수 있습니다.
주요 성능 예시
-
SigLIP-B/16-224-85M와 HuggingFaceTB/SmolLM2-135M 백본 사용 시 총 222M 파라미터의 모델을 구성
-
단일 NVIDIA H100 GPU에서 1.7M 샘플로 약 6시간 학습 후 MMStar 데이터셋에서 35.3% 정확도 달성
Here’s a structured overview of nanoVLM, the lightweight Vision–Language Model repository from Hugging Face:
빠른 시작 (Quick Start)
-
클론 & 이동
git clone https://github.com/huggingface/nanoVLM.git cd nanoVLM -
환경 설정 (예:
uv사용)uv init --bare --python 3.12 uv sync --python 3.12 source .venv/bin/activate uv add torch numpy torchvision pillow datasets huggingface-hub transformers wandb또는
pip install torch numpy torchvision pillow datasets huggingface-hub transformers wandb의존성:
torch<3,numpy<3,torchvision,pillow,datasets,huggingface-hub,transformers,wandb([GitHub][1])
학습 (Training)
wandb login --relogin
python train.pymodels/config.py에 정의된 기본 설정으로 빠르게 시작할 수 있습니다. ([GitHub][1])
생성 (Generation)
-
단일 GPU:
python generate.py -
다중 GPU (8-way DDP):
torchrun --nproc_per_node=8 train.py -
예시 출력 (assets/image.png + “What is this?”) → “This is a cat sitting on the ground.”
Hub 통합 (Hugging Face Hub)
-
프리트레인 모델 로드
from models.vision_language_model import VisionLanguageModel model = VisionLanguageModel.from_pretrained("lusxvr/nanoVLM-222M") -
학습한 모델 푸시
model.push_to_hub("username/my-awesome-nanovlm-model")(config.json, model.safetensors, README.md 자동 생성)
VRAM 사용량 벤치마크
-
H100에서 배치 사이즈별 피크 VRAM(예시):
- Batch 1: 4.4 GB
- Batch 16: 7.0 GB
- Batch 32: 10.9 GB
- Batch 64: 18.6 GB
-
측정 스크립트:
python measure_vram.py --batch_sizes "1 2 4 8"
기여 및 로드맵
-
기여 가이드라인:
- 순수 PyTorch 의존성 유지
transformers.Trainer,deepspeed등 대규모 프레임워크 도입 지양
-
향후 작업 예정:
- MMStar 평가 개선
- 데이터 패킹(Data Packing)
- 멀티 GPU 학습 지원
- 다중 이미지 입력
- 이미지 분할(SmolVLM 방식)
- VLMEvalKit 통합 ([GitHub][1])
인용 방법
@misc{wiedmann2025nanovlm,
author = {Luis Wiedmann and Aritra Roy Gosthipaty and Andrés Marafioti},
title = {nanoVLM},
year = {2025},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/huggingface/nanoVLM}}
}