
1. Introduction
연구 배경 및 문제의식
단안 깊이 추정(monocular depth estimation) 은 단일 2D 이미지로부터 3D 공간의 깊이 정보를 예측하는 기본적인 컴퓨터 비전 과제입니다.
그러나 단일 이미지에서 깊이를 추정하는 것은 기하학적으로 잘 정의되지 않은 문제(ill-posed problem) 입니다.
→ 왜냐하면 2D 이미지에는 원래 3D 장면의 정보가 모두 포함되어 있지 않기 때문입니다.
이를 해결하려면 장면 내의 객체 형태, 크기, 배치, 가림(occlusion) 등에 대한 사전 지식(prior knowledge)이 필요합니다.
기존 접근 방식
- CNN → Transformer로 모델 규모가 커지면서 성능도 향상됨.
- 대표적 방법: MiDaS, 다양한 RGB-D 데이터셋을 활용하여 범용성 확보
- 하지만, 대부분의 기존 방법은:
- 학습 데이터셋의 한계로 새로운 장면(domain) 에서 성능 저하
- 특히 Zero-Shot Generalization (학습하지 않은 환경에 대한 일반화)이 어렵다는 문제점이 있음
저자들의 핵심 아이디어
최근 등장한 확산 모델(Diffusion Model) 은 대규모 인터넷 이미지로 훈련되었고, 장면에 대한 폭넓은 시각 지식을 갖고 있음.
-
이러한 시각 지식을 이용하면, 기존 방식보다 더 일반화된 깊이 추정이 가능할 수 있다는 가정 하에 Marigold라는 모델을 제안합니다.
-
Stable Diffusion 기반의 Latent Diffusion Model (LDM) 구조 사용
-
텍스트-이미지 생성기로 훈련된 기존 모델을, 깊이 추정기로 재활용(Repurpose)
모델 훈련 방식
-
실제 깊이 데이터가 아닌, 합성(synthetic) RGB-D 데이터만으로 학습
- 사용한 데이터셋: Hypersim (실내), Virtual KITTI (실외) -
단일 GPU로 2~3일이면 fine-tuning 가능
-
Affine-invariant depth 추정:
- 실제 크기(metric scale)가 아닌, 상대적인 깊이 관계를 유지하는 방식
- 카메라의 내부 파라미터(intrinsics)가 없어도 사용 가능함
성능 및 기여 요약
-
학습에 실제 깊이 데이터 없이도 여러 데이터셋에서 SOTA 성능 달성
-
제안된 Marigold 모델은 다음을 특징으로 함:
1. 간단하고 효율적인 fine-tuning 프로토콜 (Stable Diffusion → Depth Estimator로 변환)
2. 다양한 자연 이미지에서 뛰어난 성능을 보이는 범용성 높은 깊이 추정기
2. Method
Marigold는 기존의 Stable Diffusion 모델을 활용해, 단일 이미지로부터 Affine-Invariant Monocular Depth를 추정하는 모델입니다.
→ 여기서 핵심은: 텍스트-이미지 생성 모델을, 깊이 추정기로 변환하는 것!
- 주요 구성요소:
1. Latent Diffusion Framework 사용
2. Depth 예측을 위한 fine-tuning 방식 설계
3. 합성 데이터로만 학습
4. U-Net 구조 일부만 수정하여 효율 유지
2.1 Generative Formulation (생성 기반 공식화)
Marigold는 딥러닝 기반 확산 모델을 통해, 깊이 맵을 생성하는 문제로 단안 깊이 추정을 재정의합니다.
- 입력: RGB 이미지(x)
- 출력: 깊이 맵(d)
- 학습 목표: 조건부 분포(D) 학습하기
확산 과정(Forward Diffusion):
깊이 맵 d에 점진적으로 gaussian 노이즈를 추가해 d_t를 얻습니다
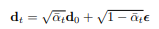
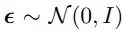
역방향 과정(Reverse Process):
학습된 denoising 네트워크를 이용하여 점차 노이즈를 제거하며 d0를 복원합니다.
학습 손실 (Loss):
노이즈 복원을 예측하는 MSE 손실을 최소화합니다.
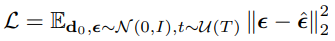
2.2 Network Architecture (네트워크 구조)
Marigold는 Stable Diffusion v2의 구조를 최대한 유지하면서 depth prediction이 가능하도록 미세 조정합니다.
🔹 VAE (Variational AutoEncoder):
- RGB 이미지 및 깊이맵을 latent space로 변환
- 원래 Stable Diffusion은 RGB만 처리 → 깊이맵을 3채널로 복제해서 입력
- 학습 후에는 VAE 디코더로 다시 깊이맵 복원
🔹 Denoising U-Net:
- 이미지 latent와 깊이 latent를 특성 차원으로 결합(concatenate)
- 첫 번째 layer의 입력 채널 수를 2배로 확장
- 기존의 weight tensor를 복제하고 0.5로 나눠, 규모 유지 및 안정성 확보
2.3 Fine-Tuning Protocol (파인튜닝 전략)
🔸 Affine-invariant 정규화
깊이맵은 일반적으로 절대 단위(metric)가 없음
→ 따라서 범용적 예측이 가능한 affine-invariant depth를 정규화로 만들어야 함
- 입력 깊이맵의 2% ~ 98% 백분위값을 기준으로 정규화:
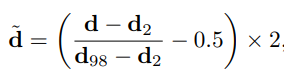
🔸 합성 데이터로만 훈련
-
Hypersim (실내), Virtual KITTI (실외) 사용
-
이유:
-
센서로 수집된 실제 깊이맵에는 종종 결측치 또는 노이즈 존재
-
합성 데이터는 전 픽셀의 GT (Ground Truth) 존재
-
VAE는 결측 픽셀을 처리하지 못함 → 합성 데이터가 더 적합
🔸 다중 해상도 노이즈 (Multi-resolution noise)
- Gaussian noise 대신 여러 스케일의 노이즈를 중첩
- 학습의 다양성과 안정성 향상
- Annealed noise schedule: 점진적으로 multi-res에서 Gaussian으로 변환
2.4 Inference (추론)
전체 과정
1.이미지 x를 VAE로 인코딩하여 z(x) 획득
2.깊이 latent는 표준 정규분포에서 무작위로 초기화
3.수정된 U-Net을 통해 T단계 노이즈 제거 수행
4.최종 latent z(d)_0을 VAE 디코더로 복원 → 평균을 취해 depth map 도출
Test-Time Ensembling (테스트 시간 앙상블)
- 확산 과정은 stochastic (무작위) → 결과가 매번 조금씩 다름
- 같은 이미지로 여러 번 추론 → 각 결과를 Affine 정렬한 뒤 평균
- 앙상블 수(N)가 늘수록 성능 향상
3. Experiments – 실험
3.1 Implementation – 구현 세부 사항
-
프레임워크: PyTorch 기반으로 구현
-
기반 모델: Stable Diffusion v2 (텍스트 조건 제거함)
-
학습 손실: DDPM의 원래 목표 함수 (v-objective [Ho et al. 2020])
-
훈련 스케줄러:
- 학습 중: DDPM 스케줄러 (1000 단계)
- 추론 중: DDIM 스케줄러 (50단계만 사용, 빠른 추론) -
추론 앙상블: 서로 다른 노이즈로 10회 추론 → 평균화
-
하드웨어
-
GPU: 단일 Nvidia RTX 4090
-
훈련 시간: 약 2.5일
-
배치 크기: 32 (gradient accumulation 사용, 16번 누적)
-
최적화 기법: Adam optimizer (learning rate = 3 × 10⁻⁵)
-
데이터 증강: 수평 플립 (random horizontal flipping)
3.2 Evaluation – 평가
학습 데이터셋
실제 깊이 데이터가 아닌, 합성(synthetic) 데이터만 사용
주된 이유는 센서 기반 실측 깊이의 노이즈/결측치 문제를 회피하기 위함입니다.
- Hypersim (실내):
- 461개의 실내 장면
- 54,000개 RGB-D 샘플 사용
- 크기: 480 × 640
- 거리 값을 일반적인 깊이값으로 변환
- Virtual KITTI (실외):
- 5개 도로 장면
- 20,000개 샘플 사용
- 원래 KITTI 벤치마크 해상도로 자름
- 최대 깊이 80m 설정
평가 데이터 셋
| 데이터셋 | 유형 | 세부 설명 |
|---|---|---|
| NYUv2 | 실내 | Kinect 기반 RGB-D; 공식 테스트셋 (654장) 사용 |
| ScanNet | 실내 | RGB-D; validation 중 800장 샘플링 |
| KITTI | 실외 도로 | Eigen split (652장) 사용 |
| ETH3D | 고해상도 | 실외 거리 측정 (454장) |
| DIODE | 혼합형 | 실내 + 실외; 전체 validation split 사용 (325 + 446장) |
평가지표
Affine-invariant 방식이므로, 예측 깊이를 ground truth에 선형 정렬 (s×d + t) 후 다음 두 지표 계산:
-
AbsRel: 평균 상대 오차 (절댓값)
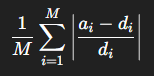
-
δ₁(δ1 accuracy): 예측이 1.25 배수 이내인 픽셀 비율
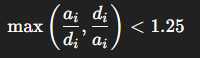
성능 비교 결과 (표)
총 6개의 대표 모델과 비교:
| 모델 | AbsRel (NYUv2) ↓ | δ₁ (KITTI) ↑ | 데이터 사용량 |
| ------------------- | ---------------- | ------------ | --------------------------- |
| MiDaS | 11.1 | 63.0 | 2M (real) |
| DPT | 9.8 | 90.1 | 1.2M real + 188K synthetic |
| Omnidata | 7.4 | 83.5 | 11.9M real + 310K synthetic |
| HDN | 6.9 | 86.7 | 300K real |
| Marigold (ours) | 5.5 | 91.6 | 74K synthetic only |
| → 앙상블 없이 | 6.0 | 90.4 | - |
주목할 점:
실제(real) 깊이맵 없이도 최고 성능 달성
NYUv2, KITTI, ETH3D 등에서 압도적 우세
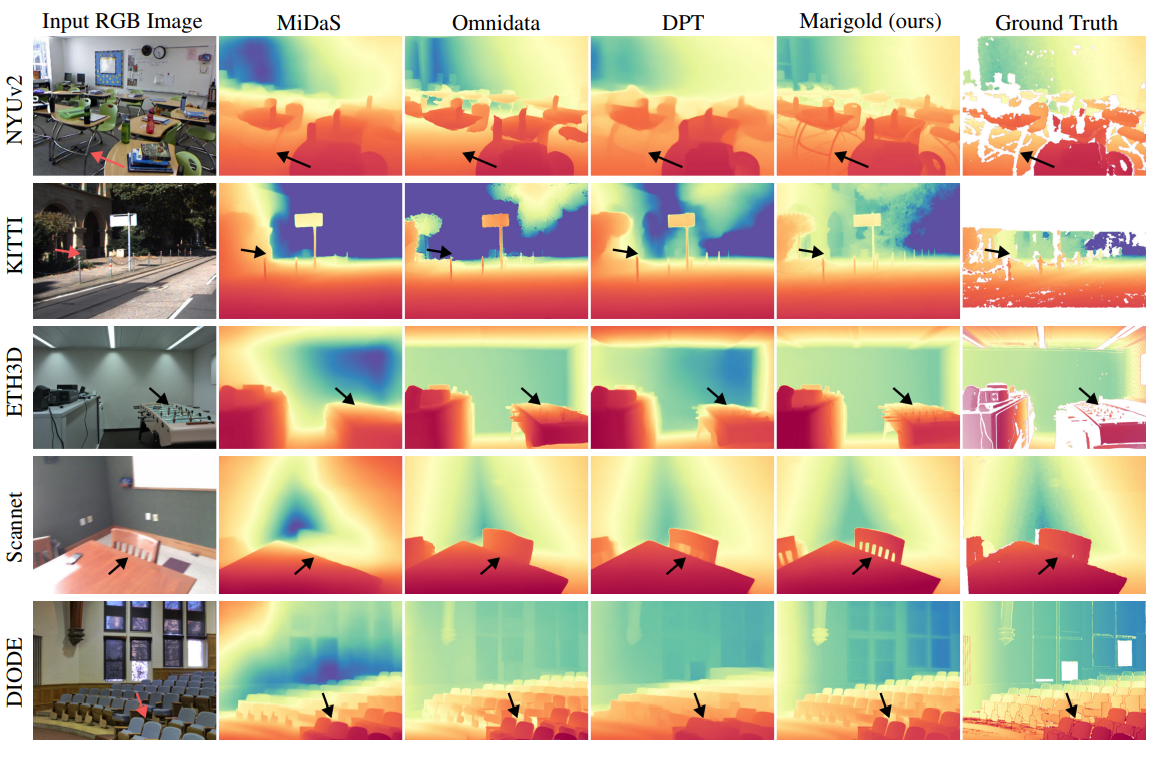
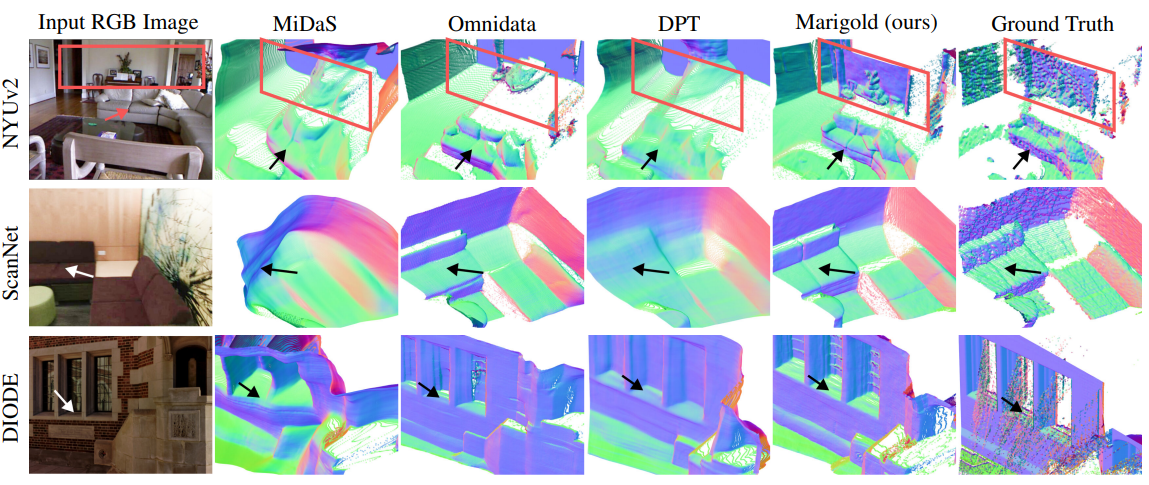
Marigold는:
- 얇은 구조물 (ex: 의자 다리)까지 잘 포착
- 정확한 벽면 및 바닥 형상 재현
- 3D surface normal 시각화에서도 부드럽고 정확함
4.3 Ablation Studies – 구성 요소 분석
앙상블 크기 실험
추론 횟수(N)에 따른 성능 변화 (Figure 6 참조)
N=1 → N=20까지 증가시킬수록 성능 개선
N=10 이상부터 성능 향상 둔화
노이즈 종류 실험
| 구성 | NYUv2 AbsRel ↓ | KITTI AbsRel ↓ |
|---|---|---|
| 표준 Gaussian 노이즈만 사용 | 7.7 | 14.2 |
| Multi-resolution 노이즈만 사용 | 5.8 | 12.1 |
| + Annealing 스케줄 사용 | 5.6 | 11.3 |
→ 결론: 다중 해상도 노이즈 + 점진적 변화 → 수렴 빠르고 성능 향상
