Fast R-CNN
Introduction
Fast R-CNN은 이전 R-CNN의 한계점을 극복하고자 나왔다. R-CNN는 다음과 같은 한계점들이 있었다.
1) RoI (Region of Interest) 마다 CNN연산을 함으로써 속도저하
2) multi-stage pipelines으로써 모델을 한번에 학습시키지 못함
그리고 Fast R-CNN에서는 다음 두 가지를 통해 위 한계점들을 극복했다.
1) RoI pooling
2) CNN 특징 추출부터 classification, bounding box regression까지 하나의 모델에서 학습
Process
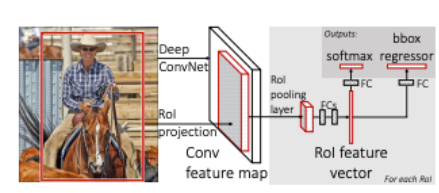
Fast R-CNN에서의 수행과정은 다음과 같다.
1-1. R-CNN에서와 마찬가지로 Selective Search를 통해 RoI를 찾는다.
1-2. 전체 이미지를 CNN에 통과시켜 feature map을 추출한다.
2. Selective Search로 찾았었던 RoI를 feature map크기에 맞춰서 projection시킨다.
3. projection시킨 RoI에 대해 RoI Pooling을 진행하여 고정된 크기의 feature vector를 얻는다.
4. feature vector는 FC layer를 통과한 뒤, 구 브랜치로 나뉘게 된다.
5-1. 하나는 softmax를 통과하여 RoI에 대해 object classification을 한다.
5-2. bounding box regression을 통해 selective search로 찾은 box의 위치를 조정한다.
Fast R-CNN의 가장 핵심적인 아이디어는 RoI Pooling이다.
R-CNN에서 CNN output이 FC layer의 input으로 들어가야했기 때문에 CNN input을 동일 size로 맞춰줘야 했다.
따라서 원래 이미지에서 추출한 RoI를 crop, warp을 통해 동일 size로 조정했었다.
그러나 실제로 "FC layer의 input이 고정인거지 CNN input은 고정이 아니다"
따라서 CNN에는 입력 이미지 크기, 비율 관계없이 input으로 들어갈 수 있고 FC layer의 input으로 들어갈때만 size를 맞춰주기만 하면된다.
Spatial Pyramid Pooling(SPP)
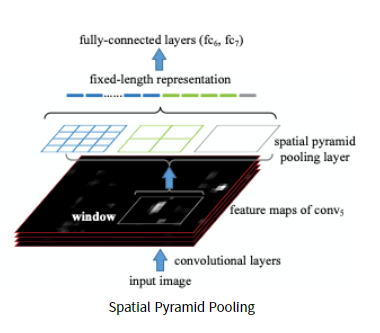
SPP에서는 먼저 이미지를 CNN에 통과시켜 feature map을 추출한다.
그리고 미리 정해진 4x4, 2x2, 1x1 영역의 피라미드로 feature map을 나눠준다. 피라미드 한칸을 bin이라 한다.
bin내에서 max pooling을 적용하여 각 bin마다 하나의 값을 추출하고,
최종적으로 피라미드 크기만큼 max값을 추출하여 3개의 피라미드의 결과를 쭉 이어붙여 고정된 크기 vector를 만든다.
정리하자면,
4x4, 2x2, 1x1 세 가지 피라미드가 존재하고, max pooling을 적용하여 각 피라미드 크기에 맞게 max값을 뽑아낸다.
각 피라미드 별로 뽑아낸 max값들을 쭉 이어붙여 고정된 크기 vector를 만들고 이게 FC layer의 input으로 들어간다.
따라서 CNN을 통과한 feature map에서 2천개의 region proposal을 만들고 region proposal마다
SPPNet에 집어넣어 고정된 크기의 feature vector를 얻어낸다.
이 작업을 통해 모든 2천개의 region proposal마다 해야했던 2천번의 CNN연산이 1번으로 줄었다.
ROI Pooling
다시 돌아와 Fast R-CNN에서 이 SPP가 적용되는 것을 보면 다음과 같다.
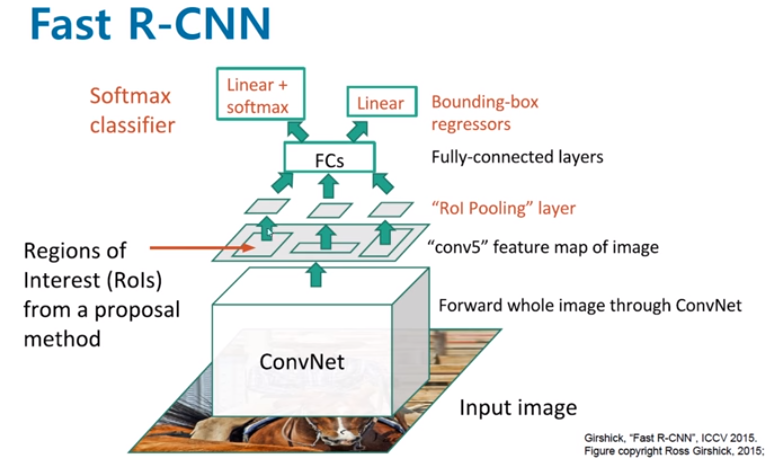
실제로 Fast R-CNN에서는 1개의 피라미드를 적용시킨 SPP로 구성되어있다. 또한 피라미드의 사이즈는 7x7이다.
Fast R-CNN에서 적용된 1개의 피라미드 SPP로 고정된 크기의 feature vector를 만드는과정을 "RoI Pooling"이라 한다.
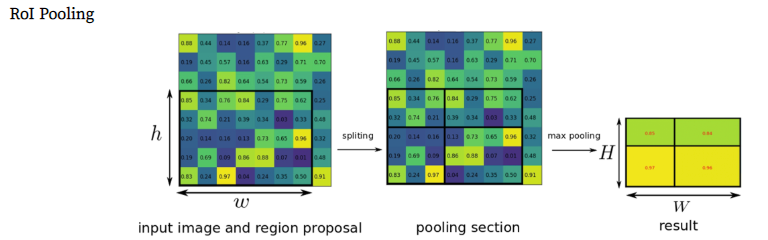
Fast R-CNN에서 먼저 입력 이미지를 CNN에 통과시켜 feature map을 추출한다.
그 후 이전에 미리 Selective search로 만들어놨던 RoI(=region proposal)을 feature map에 projection시킨다.
위 그림의 가장 좌측 그림이 feature map이고 그 안에 hxw크기의 검은색 box가 투영된 RoI이다.
(1) 미리 설정한 HxW크기로 만들어주기 위해서 (h/H) * (w/H) 크기만큼 grid를 RoI위에 만든다.
(2) RoI를 grid크기로 split시킨 뒤 max pooling을 적용시켜 결국 각 grid 칸마다 하나의 값을 추출한다.
위 작업을 통해 feature map에 투영했던 hxw크기의 RoI는 HxW크기의 고정된 feature vector로 변환된다.
이렇게 RoI pooling을 이용함으로써
"원래 이미지를 CNN에 통과시킨 후 나온 feature map에 이전에 생성한 RoI를 projection시키고
이 RoI를 FC layer input 크기에 맞게 고정된 크기로 변형할 수가 있다"
따라서 더이상 2000번의 CNN연산이 필요하지 않고 1번의 CNN연산으로 속도를 대폭 높일 수 있었다.
end-to-end : Trainable
다음은 R-CNN의 두번째 문제였던 multi-stage pipeline으로 인해 3가지 모델을 따로 학습해야했던 문제이다.
R-CNN에서는 CNN을 통과한 후 각각 서로다른 모델인 SVM(classification), bounding box regression(localization)
안으로 들어가 forward됐기 때문에 연산이 공유되지 않았다.
(* bounding box regression은 CNN을 거치기 전의 region proposal 데이터가 input으로 들어가고
SVM은 CNN을 거친 후의 feature map이 input으로 들어가기에 연산이 겹치지 않는다.)
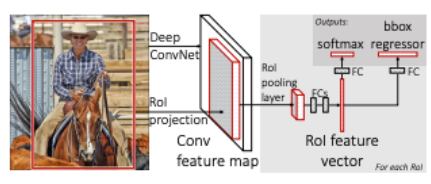
그러나 위 그림을 다시보면 RoI Pooling을 추가함으로써 이제 RoI영역을
CNN을 거친후의 feature map에 투영시킬 수 있었다.
따라서 동일 data가 각자 softmax(classification), bbox regressor(localization)으로 들어가기에 연산을 공유한다.
이는 이제 모델이 end-to-end로 한 번에 학습시킬 수 있다는 뜻이다.
Loss Function
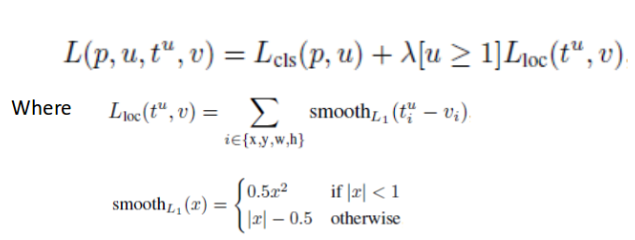
이제 Fast R-CNN의 Loss function은 위와 같이 classification과 localization loss를 합친 function으로써
한 번의 학습으로 둘다 학습시킬 수가 있다.
