Abstract(개요)
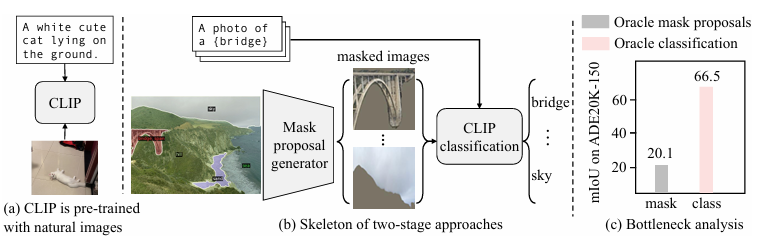
이 논문은 개방형 어휘 의미 분할(open-vocabulary semantic segmentation)을 위한 새로운 접근 방식을 제안합니다. 기존의 의미 분할 모델들은 사전에 정의된 카테고리 집합에 대해서만 훈련되어, 훈련 데이터에 없는 새로운 클래스를 인식하는 데 제한이 있었습니다.
저자들은 대규모 이미지-텍스트 데이터로 사전 훈련된 CLIP(Contrastive Language-Image Pre-training) 모델을 활용해 이 문제를 해결하고자 합니다. 구체적으로, CLIP 모델을 픽셀 수준의 분할 작업에 적합하도록 수정한 Mask-adapted CLIP(MaskCLIP)을 제안합니다.
이 접근 방식은 한정된 분할 데이터셋으로만 훈련되었음에도 불구하고, 훈련 중 접하지 않은 새로운 클래스와 도메인에 대해 효과적인 제로샷(zero-shot) 분할 능력을 보여줍니다. 실험 결과는 MaskCLIP이 표준 벤치마크에서 기존의 개방형 어휘 분할 방법들을 뛰어넘는 성능을 보여주며, 특히 훈련에 사용되지 않은 새로운 카테고리에서 우수한 일반화 능력을 증명합니다.
이 연구는 제한된 주석 데이터만으로도 유연하고 확장 가능한 의미 분할 시스템을 구축할 수 있는 새로운 가능성을 제시합니다.
핵심 기여점
Mask-adapted CLIP(MaskCLIP): 기존 CLIP 모델을 분할 태스크에 적합하도록 수정
개방형 어휘 분할: 훈련 중 접하지 않은 새로운 카테고리의 객체도 분할 가능
자기 지도 학습 활용: 대규모 이미지-텍스트 쌍 데이터로 사전 훈련된 CLIP의 잠재력 활용
Related Work
Pre-trained Vision-Language Models
사전 훈련된 비전-언어 모델(Pre-trained Vision-Language Models, VLMs)은 이미지(시각 정보)와 텍스트(언어 정보)를 동시에 이해하고 처리할 수 있는 인공지능 모델입니다. 이 모델들은 대규모 이미지-텍스트 쌍 데이터를 사용하여 사전 훈련되어, 두 모달리티(시각과 언어) 간의 연결과 관계를 학습합니다.
주요 특징
- 다중 모달리티 학습: 이미지와 텍스트 두 가지 다른 형태의 데이터를 함께 처리하고 이해합니다.
- 표현 학습: 이미지와 텍스트의 공유 의미 공간(shared semantic space)을 학습하여 두 모달리티 간의 의미적 연결을 포착합니다.
- 전이 학습: 사전 훈련된 지식을 다양한 하위 작업에 전이할 수 있습니다.
- 제로샷/퓨샷 능력: 일부 모델들은 명시적인 훈련 없이도 새로운 작업이나 카테고리를 인식할 수 있는 능력을 갖추고 있습니다.
주요 모델 예시
- CLIP(Contrastive Language-Image Pre-training): OpenAI에서 개발한 모델로, 4억 개의 이미지-텍스트 쌍으로 훈련되었습니다. 이미지와 텍스트 사이의 대조 학습을 통해 두 모달리티 간의 연결을 학습합니다.
- DALL-E: 텍스트 설명으로부터 이미지를 생성할 수 있는 모델입니다.
- ViLBERT, LXMERT, VisualBERT: BERT 구조를 기반으로 한 비전-언어 모델들로, 이미지와 텍스트의 교차 어텐션을 활용합니다.
- ALBEF, BLIP: 최근에 개발된 모델들로, 더 효율적인 학습 방법과 향상된 성능을 제공합니다.
학습 방법
- 대조 학습(Contrastive Learning): 관련 있는 이미지-텍스트 쌍은 가깝게, 관련 없는 쌍은 멀게 표현 공간에 매핑하는 방식입니다. CLIP이 대표적인 예입니다.
- 마스킹 기반 학습(Masked Learning): 이미지나 텍스트의 일부를 가리고 이를 예측하는 과정에서 두 모달리티 간의 관계를 학습합니다.
- 생성적 학습(Generative Learning): 한 모달리티에서 다른 모달리티를 생성하는 방식으로 학습합니다(예: 텍스트로부터 이미지 생성).
응용 분야
- 이미지 검색: 텍스트 쿼리로 이미지를 검색하거나 그 반대의 경우
- 시각적 질문 응답(VQA): 이미지에 관한 질문에 답변하는 시스템
- 이미지 캡셔닝: 이미지를 설명하는 텍스트 생성
- 개방형 이미지 분류: 사전 정의되지 않은 카테고리의 이미지 분류
- 의미 분할: 이미지의 각 픽셀을 의미적 카테고리로 분류
- 객체 탐지: 이미지 내 객체 위치 파악 및 분류
장점과 한계
장점:
- 대규모 데이터를 통한 강력한 일반화 능력
- 다양한 작업에 적용 가능한 유연성
- 제한된 주석 데이터로도 효과적인 성능
한계:
- 훈련 데이터의 편향성이 모델에 반영될 수 있음
- 계산 자원 요구량이 많음
- 세부적인 이해나 추론에는 여전히 제한이 있음
개방형 어휘 분할(Open-Vocabulary Segmentation)
1. 정의와 목표:
-
개방형 어휘 분할은 훈련 데이터에 명시적으로 포함되지 않은 새로운 클래스나 카테고리의 객체도 분할할 수 있는 능력을 목표로 합니다.
-
전통적인 분할 모델들이 고정된 카테고리 집합에 제한되는 것과 달리, 자연어 설명만으로도 새로운 객체를 인식하고 분할할 수 있습니다.
2. 기존 접근법의 한계:
-
논문은 기존의 분할 모델들이 훈련 과정에서 보지 못한 클래스에 대해 일반화하는 능력이 제한적임을 지적합니다.
-
대부분의 분할 모델은 특정 데이터셋의 미리 정의된 카테고리 집합에만 최적화되어 있습니다.
3. 최근 연구 동향:
- 논문은 개방형 어휘 분할을 위한 여러 접근법을 검토합니다:
- 의미 분할과 텍스트 임베딩을 결합하는 방법
- 새로운 클래스에 대한 제로샷 전이를 가능하게 하는 프레임워크
- 언어 정보를 활용하여 분할 모델의 일반화 능력을 향상시키는 기법
4. 도전 과제:
- 픽셀 수준의 세밀한 분할과 개방형 어휘 인식 사이의 갭을 해소하는 것
- 이미지 전체에 대한 글로벌 표현과 픽셀별 지역적 표현을 효과적으로 연결하는 것
- 한정된 주석 데이터로도 광범위한 시각적 개념을 인식할 수 있는 능력 확보
5. CLIP 기반 접근법의 가능성:
- 논문은 CLIP과 같은 사전 훈련된 비전-언어 모델이 개방형 어휘 분할에 특히 적합할 수 있음을 제안합니다.
- 이러한 모델들이 이미 다양한 시각적 개념과 언어적 표현 사이의 연결을 학습했기 때문입니다.
- 그러나 이미지 수준의 인식에 최적화된 CLIP을 픽셀 수준의 분할에 적용하기 위해서는 적절한 수정이 필요함을 강조합니다.
6. 평가 방법론:
- 논문은 개방형 어휘 분할 모델을 평가하기 위한 방법론도 논의합니다.
- 특히 '보이는 클래스'(seen classes)와 '보이지 않는 클래스'(unseen classes)에 대한 성능을 구분하여 평가하는 중요성을 강조합니다.
Prompt Tuning
1. 텍스트 프롬프트의 역할:
- 개방형 어휘 분할에서 텍스트 프롬프트는 분류하고자 하는 클래스나 개념을 모델에 알려주는 역할을 합니다.
- 적절한 프롬프트 설계는 모델의 성능에 큰 영향을 미칩니다.
2. 기본 프롬프트 템플릿:
- 논문에서는 "a photo of a [CLASS]"와 같은 간단한 템플릿을 기본으로 사용합니다.
- 이 템플릿에 분할하고자 하는 객체 클래스 이름을 삽입하여 텍스트 임베딩을 생성합니다.
3. 프롬프트 앙상블(Prompt Ensemble):
- 더 강력한 표현을 위해 여러 프롬프트 템플릿을 함께 사용하는 앙상블 접근법을 적용합니다.
- "a photo of a [CLASS]", "a picture of a [CLASS]", "a [CLASS] in the scene" 등 다양한 템플릿을 활용합니다.
- 각 템플릿으로부터 생성된 임베딩의 평균을 최종 클래스 표현으로 사용합니다.
4. 맥락적 프롬프트(Contextual Prompts):
- 단순한 클래스 이름 외에도, 객체의 속성이나 맥락을 포함하는 더 풍부한 프롬프트를 실험합니다.
- 예를 들어, "a red [CLASS]", "a [CLASS] in the kitchen" 등과 같이 맥락 정보를 추가합니다.
5. 학습 가능한 프롬프트(Learnable Prompts):
- 고정된 텍스트 템플릿 대신, 학습 가능한 프롬프트 파라미터를 도입합니다.
- 이는 기본 텍스트 임베딩을 초기값으로 하고, 분할 작업에 최적화되도록 미세 조정됩니다.
- 모델이 특정 분할 작업에 더 적합한 프롬프트 표현을 학습할 수 있게 합니다.
6. 클래스 간 관계 활용:
- 논문은 CLIP 텍스트 인코더가 학습한 클래스 간의 의미적 관계를 활용합니다.
- 유사한 개념들 사이의 임베딩 유사성을 분할 과정에서 활용하여 보이지 않는 클래스에 대한 일반화 능력을 향상시킵니다.
7. 실험 및 결과:
- 다양한 프롬프트 전략의 효과를 비교 분석합니다.
- 학습 가능한 프롬프트가 고정된 템플릿보다 일반적으로 더 나은 성능을 보여줍니다.
- 프롬프트 앙상블이 모델의 안정성과 성능을 향상시키는 것을 확인합니다.
Two-stage 모델의 개념과 구조
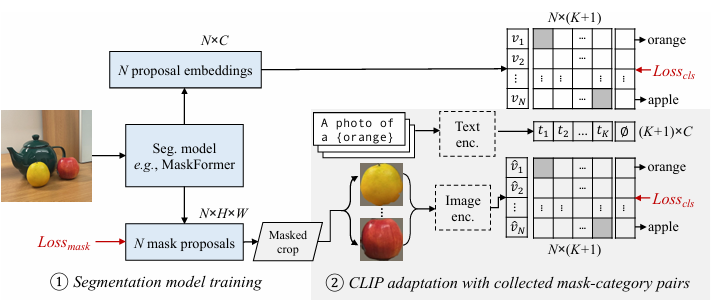
1. 기본 아이디어:
- 의미 분할 과정을 두 개의 분리된 단계로 나누어 처리합니다.
- 첫 번째 단계에서는 클래스에 구애받지 않는 마스크/영역 제안(class-agnostic mask/region proposals)을 생성합니다.
- 두 번째 단계에서는 각 마스크/영역에 적절한 클래스 레이블을 할당합니다.
2. 첫 번째 단계: 마스크 생성(Mask Generation):
- 이미지에서 의미적으로 일관된 영역이나 객체를 구분하는 세그먼트 마스크를 생성합니다.
- 이 단계에서는 구체적인 클래스 정보 없이 "무엇인가가 있다"는 것만 인식합니다.
- 주로 다음과 같은 방법들이 사용됩니다:
- 클래스에 구애받지 않는 인스턴스 분할(class-agnostic instance segmentation)
- 범용 의미 분할(panoptic segmentation)의 변형
- 자기 지도 학습 방식의 마스크 생성
- 클러스터링 기반 세그먼트 제안
3. 두 번째 단계: 레이블 할당(Label Assignment):
- 첫 번째 단계에서 생성된 각 마스크/영역에 대해 적절한 클래스 레이블을 할당합니다.
- 이 단계에서 CLIP과 같은 사전 훈련된 비전-언어 모델의 강점이 활용됩니다.
- 각 마스크로 크롭된 이미지 영역과 다양한 클래스 텍스트 프롬프트 간의 유사도를 계산합니다.
- 가장 높은 유사도를 가진 클래스를 해당 마스크의 레이블로 할당합니다.
4. 구체적인 구현 사례:
- 논문은 이러한 투 스테이지 접근법의 여러 구현 사례를 분석합니다:
- MaskCLIP: 논문에서 제안하는 방법으로, 마스크 적응형 CLIP 구조를 활용합니다.
- LSeg+OVSeg: 영역 제안 네트워크와 CLIP 기반 분류기를 결합한 방식입니다.
- ZSSeg: 자기 지도 학습 기반 마스크 생성과 제로샷 분류를 결합한 접근법입니다.
5. 주요 장점:
- 모듈성(Modularity): 두 단계가 분리되어 있어 각 단계를 독립적으로 개선할 수 있습니다.
- 효율성(Efficiency): 마스크 생성이 클래스에 구애받지 않기 때문에, 제한된 데이터로도 효과적인 분할이 가능합니다.
- 확장성(Scalability): 새로운 클래스를 추가할 때 전체 모델을 재훈련할 필요 없이, 텍스트 프롬프트만 추가하면 됩니다.
6. 한계점:
- 두 단계 간의 불일치: 마스크 생성이 의미적 내용을 완전히 이해하지 못하면 잘못된 분할이 발생할 수 있습니다.
- 계산 복잡성: 두 개의 별도 네트워크를 실행해야 하므로 계산 비용이 증가할 수 있습니다.
- 오류 전파: 첫 번째 단계의 오류가 두 번째 단계로 전파될 수 있습니다.
7. 성능 비교 및 분석:
- 논문은 다양한 투 스테이지 모델의 성능을 비교 분석합니다.
- 특히 보이는 클래스(seen classes)와 보이지 않는 클래스(unseen classes)에 대한 성능 차이를 중점적으로 평가합니다.
- MaskCLIP과 같은 접근법이 기존 방법들보다 특히 보이지 않는 클래스에서 우수한 성능을 보임을 강조합니다.
보이는 클래스(Seen Classes)
정의: 모델을 훈련시킬 때 사용된 데이터셋에 포함되어 있어, 모델이 명시적으로 학습한 객체 카테고리들입니다.
예시: 만약 모델이 PASCAL VOC 데이터셋으로 훈련되었다면, 'person', 'car', 'dog' 등과 같이 이 데이터셋에 주석이 달린 20개 클래스가 '보이는 클래스'입니다.
특징: 모델은 이러한 클래스에 대해 직접적인 학습 경험이 있으므로, 일반적으로 이들을 잘 인식하고 분할할 수 있습니다.
보이지 않는 클래스(Unseen Classes)
정의: 모델 훈련 과정에서 명시적으로 노출되지 않은, 즉 훈련 데이터셋에 주석으로 포함되지 않았던 객체 카테고리들입니다.
예시: PASCAL VOC로 훈련된 모델에 대해, 'zebra', 'giraffe', 'laptop'과 같이 이 데이터셋에 없는 클래스들이 '보이지 않는 클래스'입니다.
특징: 전통적인 분할 모델은 이러한 클래스를 인식하지 못하지만, 개방형 어휘 모델은 사전 훈련된 비전-언어 모델(CLIP 등)의 일반화 능력을 활용하여 이러한 클래스도 인식하고 분할하는 것을 목표로 합니다.
이 논문에서는 MaskCLIP과 같은 개방형 어휘 분할 모델의 성능을 평가할 때, 보이는 클래스와 보이지 않는 클래스를 구분하여 분석합니다:
보이는 클래스에 대한 성능: 기존 분할 모델도 어느 정도 좋은 성능을 보이는 영역으로, 개방형 어휘 모델이 기존 모델과 비교해 경쟁력 있는 성능을 유지하는지 확인합니다.
보이지 않는 클래스에 대한 성능: 개방형 어휘 모델의 진정한 강점이 드러나는 영역으로, 모델이 훈련 데이터에 없던 객체 카테고리를 얼마나 잘 인식하고 분할하는지 평가합니다.
Collecting diverse mask-category pairs from captions
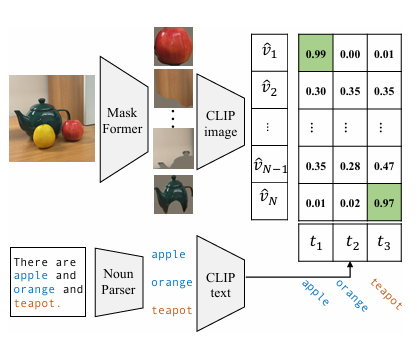
Mask-adapted CLIP을 위한 방법론
이 논문에서는 마스크된 이미지를 더 잘 처리하기 위해 CLIP을 미세 조정(finetune)하는 방법을 제안하고 있습니다. 이를 위한 접근법은 다음과 같습니다:
1. 첫 번째 시도: 수동 주석 데이터셋 활용
- COCO-Stuff와 같은 수동으로 주석이 달린 세분화(segmentation) 레이블을 활용
- 이 방법으로 171개 클래스에 걸쳐 965K 마스크-카테고리 쌍을 수집
- CLIP의 이미지 인코더만 미세 조정하고 텍스트 인코더는 고정(freeze)
2. 문제점 발견
- 이 단순한 접근법은 CLIP의 일반화 능력을 제한하는 것으로 관찰됨
- 보지 못한 클래스(unseen classes)가 많을수록 성능이 저하됨
- 연구자들은 제한된 텍스트 어휘로 인해 미세 조정된 CLIP이 171개 클래스에 과적합(overfit)되어 새로운 카테고리로의 일반화 능력을 상실한다고 가설을 세움
3. 대안적 접근법: 이미지 캡션 활용
- 세분화 레이블과 비교하여, 이미지 캡션은 이미지에 대한 더 풍부한 정보를 포함하고 훨씬 더 큰 어휘를 사용
- 예를 들어, 그림 3에서 "There are apple and orange and teapot."라는 캡션이 있음
- "apple"과 "orange"는 COCO-Stuff의 유효한 클래스이지만, 다른 개념(teapot 등)은 유효한 클래스가 아니라서 무시됨
자가 라벨링 전략(Self-labeling Strategy)
앞서 발견한 한계점을 바탕으로, 저자들은 다음과 같은 방법으로 마스크-카테고리 쌍을 추출하는 자가 라벨링 전략을 설계했습니다:
1. 프로세스 개요
- 이미지가 주어지면, 사전 훈련된 MaskFormer를 사용하여 마스크된 제안(masked proposals)을 추출
- 동시에, 해당 이미지 캡션에서 오프더쉘프(off-the-shelf) 언어 파서를 사용하여 모든 명사를 추출하고 이를 잠재적 클래스로 취급
- CLIP을 사용하여 각 클래스에 가장 일치하는 마스크 제안을 페어링
2. 데이터셋 구축
- COCO-Captions에서 다음 두 가지 방식으로 데이터셋 구축:
1. 이미지당 5개의 캡션을 사용하여 27K 고유 명사를 포함한 130만 개의 마스크-카테고리 쌍 수집
2. 이미지당 1개의 캡션을 사용하여 12K 명사를 포함한 44만 개의 쌍 수집
3. 효과
실험 결과, 이렇게 구축한 노이즈가 있지만 다양한(noisy but diverse) 마스크-카테고리 데이터셋이 수동 세분화 레이블보다 크게 향상된 성능을 보임
Mask prompt tuning
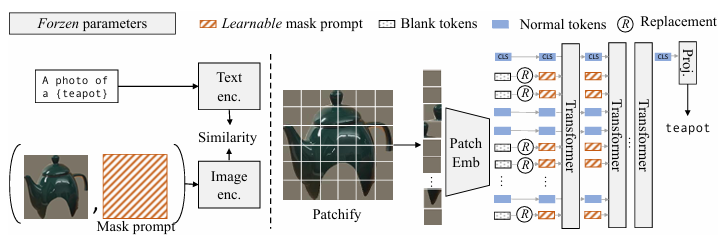
1. 기존 방식의 한계:
- 기존 방식은 마스크된 영역을 직접 크롭하여 CLIP에 입력하는데, 이 과정에서 해상도가 낮아지고 객체 주변의 중요한 컨텍스트 정보가 손실됨
- 특히 작은 객체나 복잡한 장면에서 성능 저하 발생
2. 제안된 해결책 - Mask Prompt Tuning:
- 마스크 정보를 전체 이미지와 함께 CLIP에 제공하는 새로운 방식 도입
- 핵심 아이디어: 시각적 프롬프트(visual prompt)를 사용하여 마스크 정보를 인코딩
3. 구현 방법:
- 원본 이미지에 마스크 정보를 추가하여 표현
- 두 가지 주요 구성 요소:
- 마스크 프롬프트(Mask Prompt): 학습 가능한 프롬프트 토큰으로, 마스크 정보를 인코딩
- 배경 감쇠(Background Attenuation): 마스크 외부 영역의 시각적 특징을 약화시켜 마스크 내부에 집중할 수 있도록 함
4. 구체적인 기술적 구현:
- 마스크 M이 주어지면, 원본 이미지 I와 함께 마스크 프롬프트 P를 적용
- 새로운 이미지 표현: I' = I + α·M·P (여기서 α는 프롬프트 강도를 제어하는 파라미터)
- 배경 감쇠는 마스크 외부 영역의 강도를 β 비율로 감소: I'bg = β·Ibg (β < 1)
5. 장점:
- 전체 이미지 컨텍스트 유지하면서도 마스크 영역에 집중 가능
- 학습 가능한 파라미터 수가 적어 효율적인 학습 가능
- 다양한 객체 크기와 장면 복잡성에 더 강건한 성능 제공
6. 학습 방법:
- 3.2 섹션에서 설명한 자가 라벨링으로 생성된 마스크-카테고리 쌍을 사용하여 학습
- 마스크 프롬프트와 관련 파라미터만 학습하며, CLIP의 기본 모델 가중치는 고정
실험 결과
1. 기존 분할 데이터셋에서의 성능:
PASCAL VOC, PASCAL Context, COCO 등의 데이터셋에서 평가
특히 훈련에 사용되지 않은 클래스에 대해 우수한 성능
2. 제로샷 전이 성능:
훈련 시 보지 못한 데이터셋과 카테고리에 대한 일반화 능력 입증
ADE20K와 같은 복잡한 데이터셋에서도 경쟁력 있는 결과
3. 비교 분석:
기존 의미 분할 모델과의 포괄적인 비교
특히 개방형 어휘 설정에서 상당한 우위
주요 함의
분할과 시각적 인식의 통합: 픽셀 수준 분할과 개념 수준 인식 사이의 격차 해소
데이터 효율성: 한정된 주석 데이터만으로도 다양한 카테고리 인식 가능
실용적 응용: 로봇 공학, 자율 주행, 증강 현실 등 다양한 분야에 응용 가능성
한계점 및 향후 연구 방향
계산 효율성 개선 필요
미세한 객체 및 경계 분할의 정확도 향상
다양한 도메인 및 작업으로의 확장성 연구
이 논문은 개방형 어휘 의미 분할이라는 도전적인 문제에 대해 CLIP의 강력한 표현 학습 능력을 활용하는 혁신적인 접근 방식을 제시했으며, 컴퓨터 비전 분야에서 제한된 주석 데이터로도 유연하고 확장 가능한 시스템을 구축할 수 있는 가능성을 보여주었습니다.
