Matrix -- The mother of all data structures. The nonmathematical uses of the word matrix reflect its Latin origins in mater, or mother.... The word has two meanings -- a representation of a linear mapping and the basis for all our existence.
Linear Systems
Linear algebra는 Ax=b 형태의 the system of linear equations에 대한 성질을 탐구한다.
이 Ax=b는 row picture로는 n개의 plane에 대한 intersection이며, column picture로는 A의 column vectors들의 조합으로 볼 수 있다. 일반적으로는 column picture로써 문제를 주로 바라본다.
모르는 사람이 없을 공식인데, 기본적으로 A의 row vector를 원소로 가지는 vector와 B의 column vector를 원소로 가지는 vector에 대해서, 원소 간 곱을 inner product라고 했을 때의 outer product로 계산된다.
또한, 다음과 같이 표현할 수도 있다.
C=AB=k=1∑pA(:,k)B(k,:)
즉, A의 column vector를 원소로 가지는 vector와 B의 row vector를 원소로 가지는 vector에 대해서, 원소 간 곱을 outer product라고 했을 때의 inner product로 계산된다.
Matrix Multiplication을 효율적이고 빠르게 하는 것이 학습 속도를 결정하기 때문에 이 부분을 열심히 파보는 것도 좋을 것 같다.
Determinant and Positive Definite
Determinant of a Matrix
A의 determinant는 A의 row vector들로 표현된 n-dimensional space 상의 parallelepiped P의 부피와 같다.
아마 Matrix를 하나의 값으로 표현한다면 가장 흔하게 사용될 값이 바로 determinant 이다. (Determinant 값이 음수라면 공간의 방향(orientation)이 뒤집힌다는 의미이다.)
Determinant와 관련된 공식은 많지만, 아래 정도만 기억해도 고차원 수학을 다룰 예정이 아니라면 별 문제는 없었던 것 같다.
A matrix A has an inverse matrix A−1 if and only if det(A)=0
If A is triangular, then det(A)=a11a22...ann. In Particular, det(In)=1.
det(AB)=det(A)det(B)
tr(AB)=tr(BA)
간혹 invese matrix를 프로그램이나 알고리즘 내에서 직접 explicit하게 계산하도록 코드를 구현하는 사람들이 있는데, 높은 확률로 뻗어버릴테니 꼭 피하길 바란다.
Symmetric Positive Definite (SPD) Matrix
Symmetric Positive Definite(SPD)는 이후 다룰 Optimization 내용에서 중요하게 사용되는 성질이다.
SPD의 정의는 다음과 같다.
Symmetric: A=AT
Positive Definite (or positive semi-definite): if xTAx>0 (or xTAx≥0) for all nonzero x∈Rn, denoted by A≻0 (or A⪰0).
만약 C∈Rn×n가 full rank를 가지고 A=CTC이면, A는 SPD이다.
xTAx=xTCTCx=∥Cx∥2>0
참고로 Covariance Matrix는 SPD이다.
C=N−11XTX=N−11j=1∑NxjxjT
where xi=[xi1...xip]T.
The Cholesky Factorization
The Cholesky Factorization는 SPD matrix가 갖는 중요한 성질로, 모든 SPD는 positive diagonal entry를 갖는 upper-triangular matrix로 unique하게 분해된다.
Theorem: Cholesky factorization
Every SPD matrix A=(aij)∈Rn×n has a uniqe Cholesky factorization
A=RTR,rii>0
where R=(rij) is an n×n upper-triangular matrix with positive diagonal entries.
위 R을 A21로 표현하기도 한다.
Tests for Positive Definiteness
어떤 Matrix가 Positive Definite인지 판별하는 방법은 다음과 같 은 것들이 있다.
All the eigenvalues of A satisfy λi>0.
All the upper left submatrices Ak have positive determinants.
2×2-matrix [abbc] is positive definite when a>0 and ac−b2>0.
Linear Algebra
Linear Dependency and Basis
The vectors v1,v2,...,vk에 대해 c1v1+...+ckvk=0을 만족하는 조건이 오직 c1=...=ck=0이면, 이는 linearly independent 이다. (반대는 linearly dependent)
만약 vi들이 linearly dependent하면, vi들 중 하나(vk)를 나머지 vector들 (v1,…,vk−1,vk+1,…,vn)의 linear combination으로 표현할 수 있다.
어떤 vector space V에 대해, V 내 모든 vector v를 vi들의 linear combination들로 표현할 수 있는 경우, vi들이 V를 생성(span)한다고 말한다.
만약 다음 조건들이 만족되는 경우 {vi}를 V의 basis 라고 한다.
vi's are linearly independent.
{vi} spans the space V.
Vector space V의 basis를 구성하는 vector의 수를 V의 dimension 이라고 한다.
Norms
Let S be a vector space with elements x.
이 때, 다음 조건들을 만족하는 real-valued function ∥x∥을 norm 이라고 한다:
∥x∥≥0 for any x∈S
∥x∥=0 if and only if x=0
∥αx∥=∣α∣∥x∥, where α is an arbitrary scalar
∥x+y∥≤∥x∥+∥y∥(triangular inequality)
새로운 Norm을 만들 때, triangular inequality를 만족하는지 꼭 체크해야한다.
Vector Norms
Vector p-norm: ∥x∥p=(∑i=1n∣xi∣p)1/p
Manhattan: ∥x∥1=∑1≤i≤n∣xi∣$
Euclidian: ∥x∥2=xTx
Chebyshev: ∥x∥∞=max1≤i≤n∣xi∣
Matrix Norms
Matrix p-norm
∥A∥p=x=0sup∥x∥p∥Ax∥p
Frobenius norm
∥A∥F=(i=1∑mj=1∑n∣aij∣2)1/2=tr(ATA)
Matrix Operation on Vectors
Linear Transformations
만약 특정 공간의 basis들에 대한 linear transformation (Axi) 를 안다면, 우리는 그 공간 전체에 대한 linear transformation을 알 수 있다.
Linearity: If x=c1x1+...+cnxn, then Ax=c1(Ax1)+...+cn(Axn).
자주 사용되는 linear transformation으로는 Scaling, Rotation, Identity, Projection, Reflection 등이 있다.
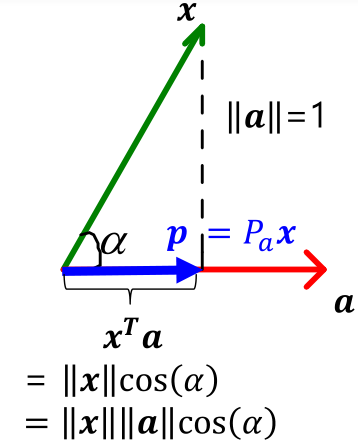
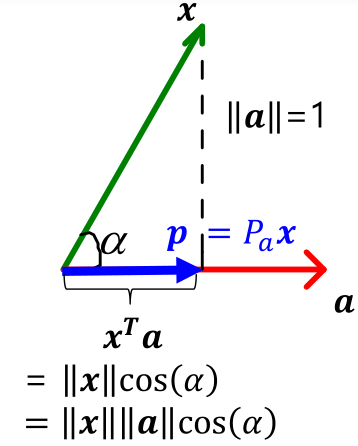
Projection Using Inner Products
WANT: project x to a.
p=(xTa)a=(aTx)a=a(aTx)=(aaT)x=Pax
Pa=aaT if ∥a∥=aTa=1
Pa=aTaaaT in general
이 때, Pa를 projection matrix 라고 한다.
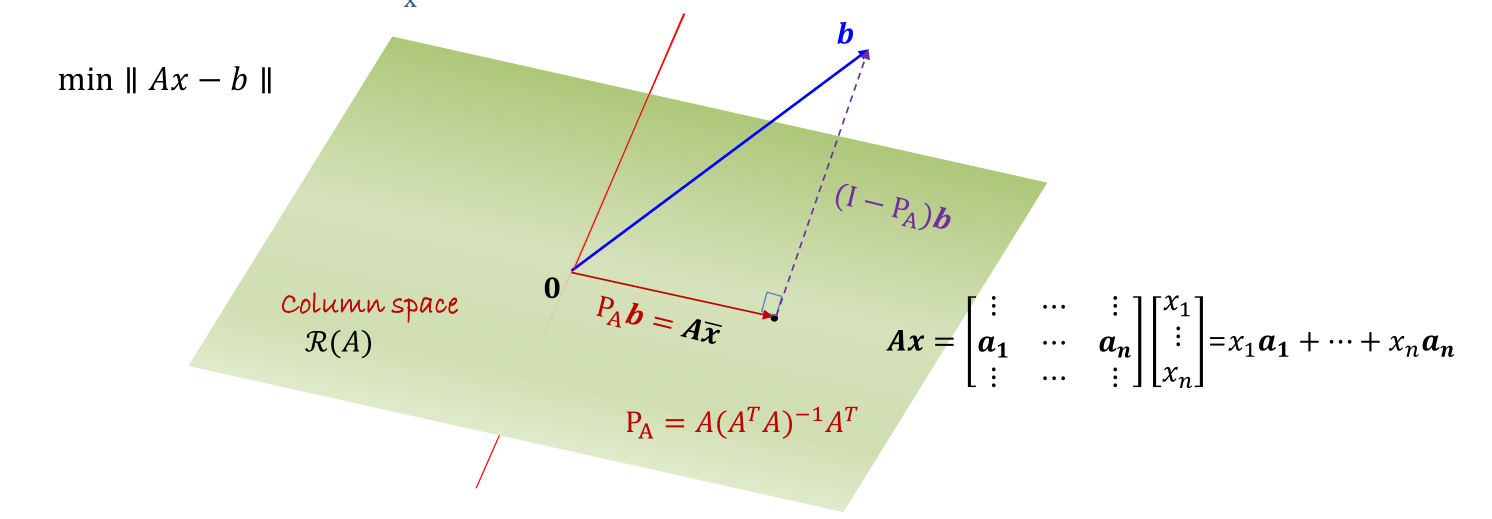
Least Squares
Least Squares Solution
Theorem: Least Squares Solution
The least squares solution to :
min∥Ax−b∥A∈Rm×n,m>n
satisfies the following normal equation : ATAxˉ=ATb
Least square 문제는 아래 figure에서 볼 수 있듯이 Ax 위로의 b의 projection 문제와 동일하다.
이는 앞으로 나올 수많은 dimension reduction 기법의 가장 기초가 된다.
If ATA is invertible, then xˉ=(ATA)−1ATb
If p is the projection of b onto the column space of A, then p=Axˉ=Pb=A(ATA)−1ATb, whereP is an orthogonal projection matrix given by A(ATA)−1AT
P∈Rn×n is said to be a projection if P2=P.
P∈Rn×n is an orthogonal projection if P2=P and P=PT.
Orthogonal Matrix
Matrix Q의 column과 row vector들이 orthogonal unit vectors (orthonormal vectors)이면, i.e.QTQ=QQT=I, 이 때의 Q를 orthogonal matrix라고 한다.
Orthogonal matrix는 다음과 같은 좋은 성질을 가진다.
QT=Q−1
∥Qx∥=∥x∥
(Qx)T(Qy)=xTy
Orthogonal matrix를 이용한 transformation은 lengths와 inner products를 보존한다.
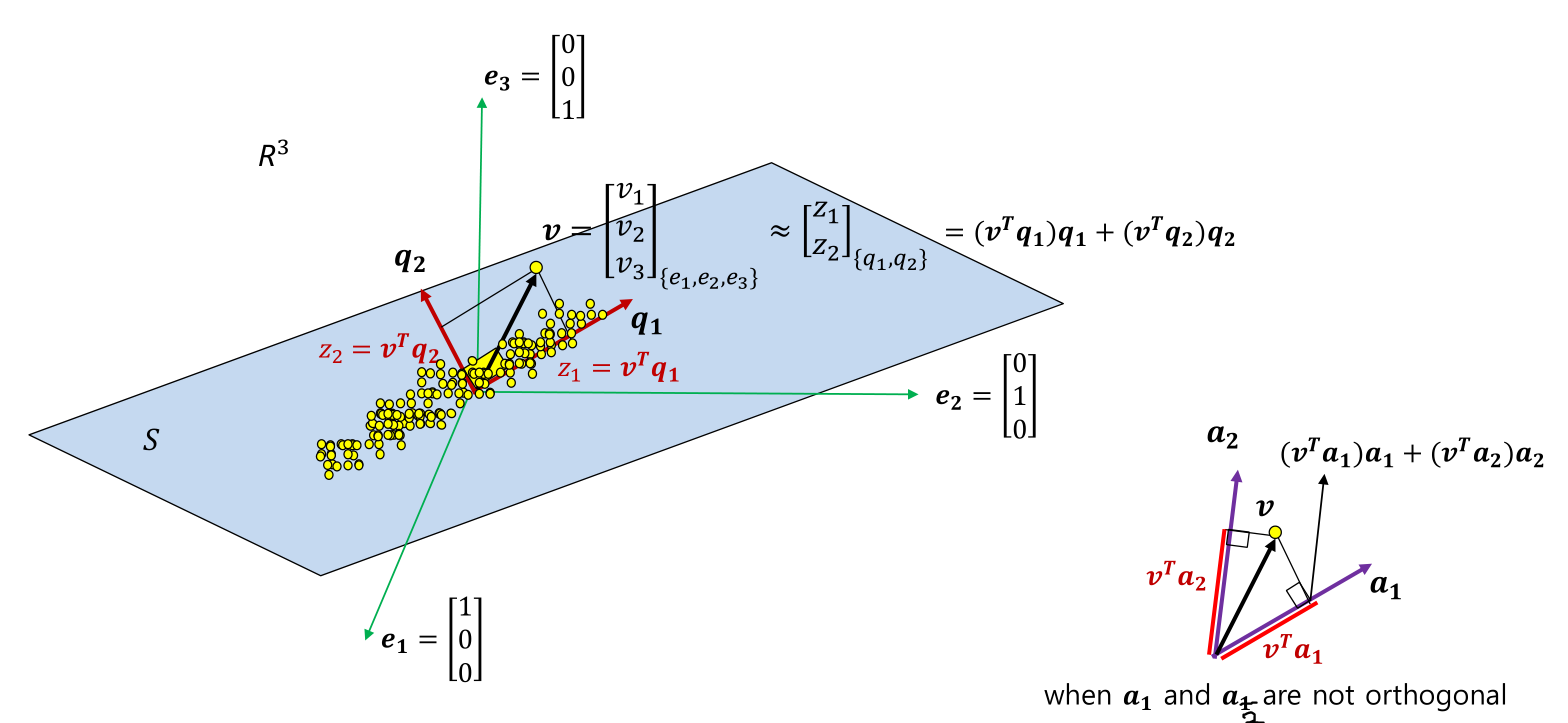
Theorem: Orthogonal Matrix
If the columns of Qr=[q1,...,qr]∈Rn×r are an orthonormal basis for a subspace S, then the least squares problem min∥Qrx−b∥ becomes easy
QrTQrxˉ=QrTb⇒xˉ=QrTb.
The projection of b and the unique orthogonal projection matrix onto the column space S=span{q1,...,qr} is
p=Psb=Qrxˉ=QrQrTb,Ps=QrQrT=i=1∑rqiqiT
만약 Q=[q1,...,qn]∈Rn×n의 column들이 orthonormal basis이면, b는 다음과 같이 쓸 수 있다.
b=x1q1+...+xnqn=Qx,x=QTb
⇒b=QQTb=(q1Tb)q1+...(qnTb)qn
어떤 vector를 다른 basis로 표현하는 기법으로, 이 역시 dimension reduction을 포함한 feature transformation 기법의 기초가 된다.