Optimization in Learning
1.Matrix Computation
Matrix -- The mother of all data structures. The nonmathematical uses of the word matrix reflect its Latin origins in mater, or mother.... The word ha
2.Calculus Backgrounds
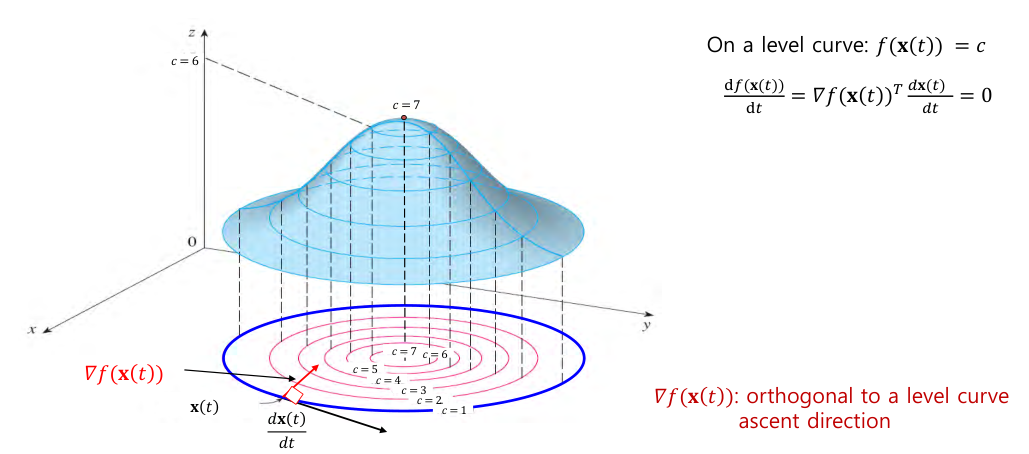
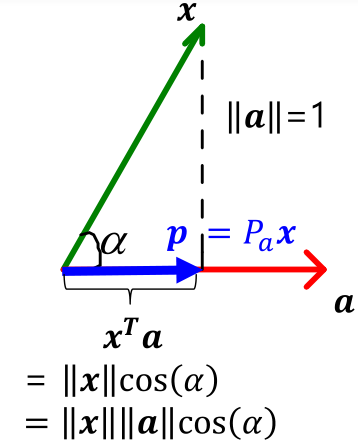
Dimension을 주의할 것!$\\nabla f(x)$ = the gradient of $f$The transpose of the first derivatives of $f$$$\\nabla f(x) := \\begin{bmatrix} \\frac{\\partial
3.Convex Optimization
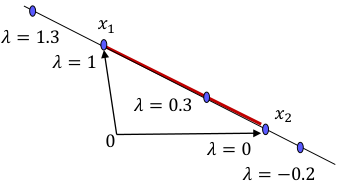
두 points의 convex combination 은 line segment between them.$$\\lambda x_1 + (1-\\lambda) x_2, \\quad \\lambda \\in 0,1 $$A set $C \\in \\mathbb{R}^n$에 대
4.Unconstrained Optimization
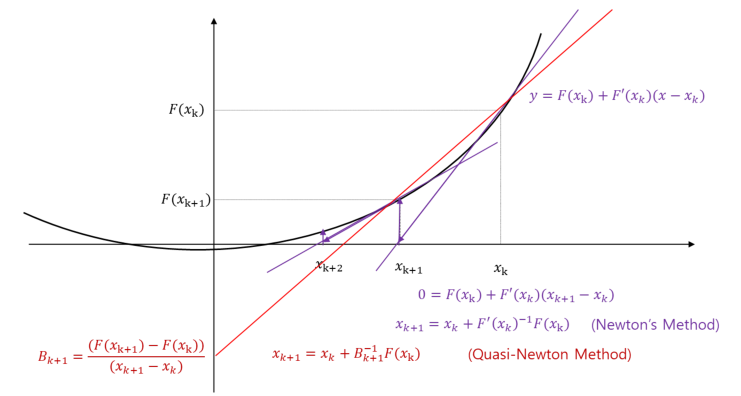
Lemma:Suppose that $f: \\mathbb{R}^n \\rightarrow \\mathbb{R}$ is differentiable at $\\bar{x}$. If there is a vector $d \\in \\mathbb{R}$ such that $\
5.Constrained Optimization
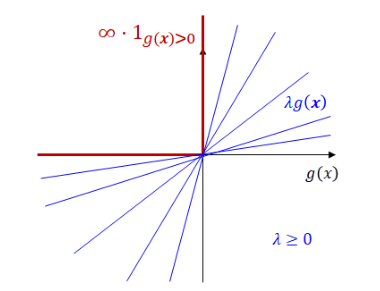
$$\\begin{aligned}& \\text{minimize}& & f(x) \\& \\text{subject to}& & g_i(x) \\le 0, \\quad i=1,\\dots,l\\& & & h_j(x) = 0, \\quad j=1,\\dots,m\\\\en
6.Optimization vs Learning
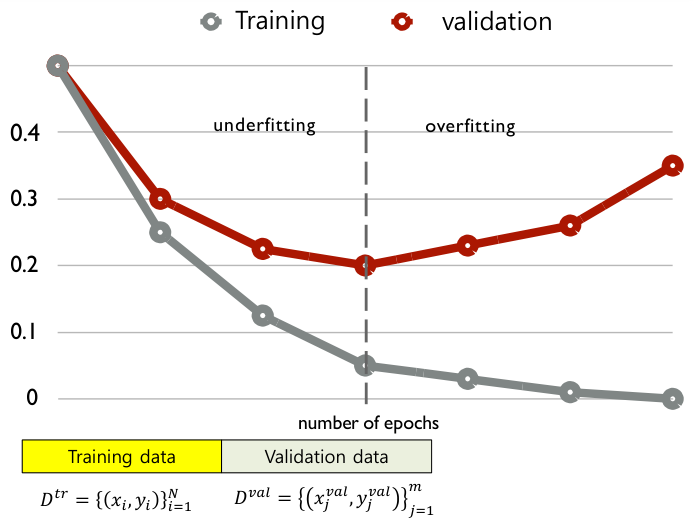
Pure optimization의 목표는 매우 명확하다: optimum을 찾는 것!Step 1. 문제를 mathematical formulation으로 (최대한) 나타낸다.Step 2: (가능한) 최적의 optimum solution을 찾는다.반면에, (machine)
7.Stochastic Gradient Descent
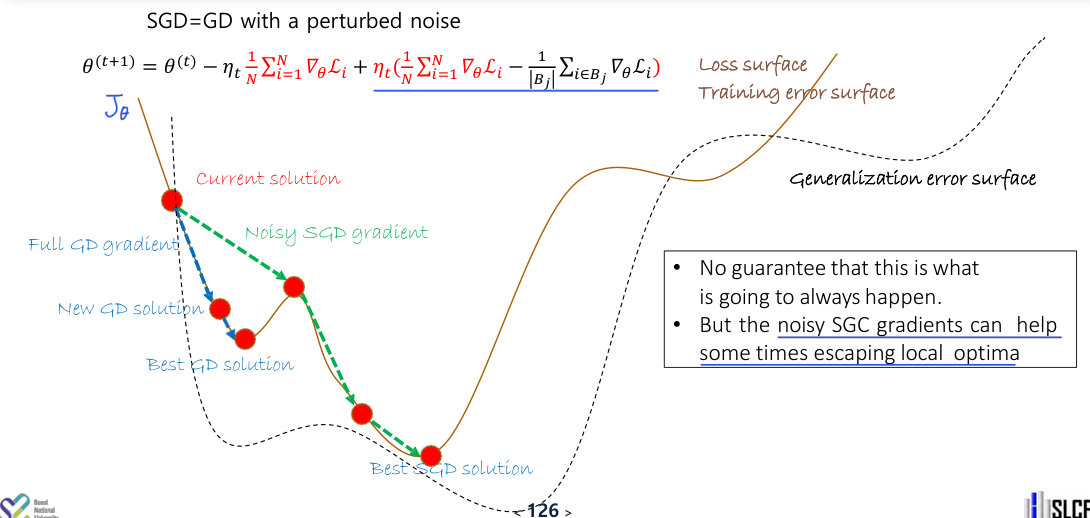
Remind: Calculus Backgrounds일반적인 machine learning 방법론들은 steepest descent 방법 또는 gradient descent(GD) 방법을 통해 loss function을 최소화하는 값을 찾아간다.$$\\theta^{(t+
8.Momentum
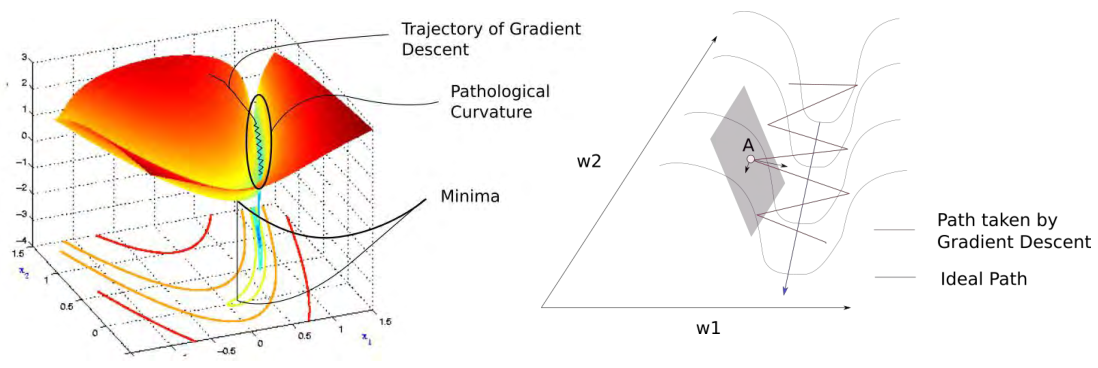
위 그림에서 loss surface의 minimum을 찾아가기 위해서는 필연적으로 아주 가파른 valley를 지나가야 한다. 이 과정에서 점 A에서 gradient를 계산하게 되면, $w_1$ 방향과 $w_2$ 방향 중 $w_1$ 방향으로의 gradient의 크기가 훨