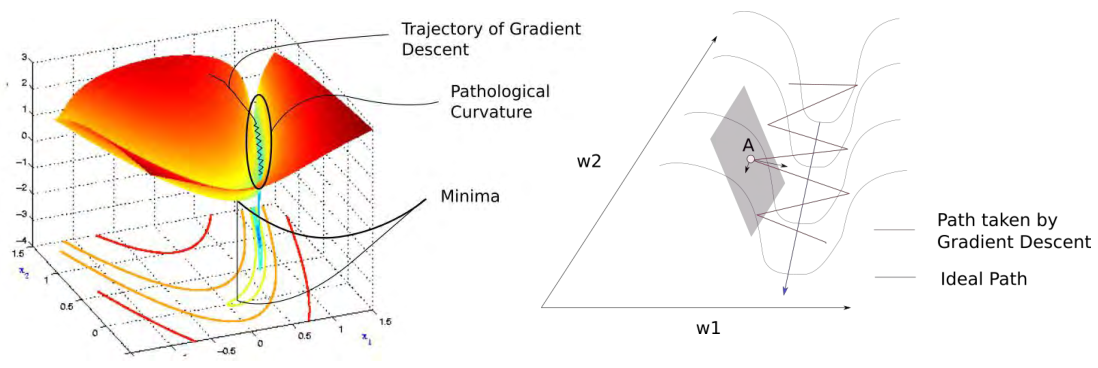
위 그림에서 loss surface의 minimum을 찾아가기 위해서는 필연적으로 아주 가파른 valley를 지나가야 한다. 이 과정에서 점 A에서 gradient를 계산하게 되면, w1 방향과 w2 방향 중 w1 방향으로의 gradient의 크기가 훨씬 크다는 것을 알 수 있다. 즉, 새로운 점은 minimum이 위치한 w2 방향이 아닌 w1 방향으로 이동하게 될 것이다.
이렇게 지그재그 방향으로 gradient가 업데이트되는 것을 graident oscillation이라고 한다.
Momentum
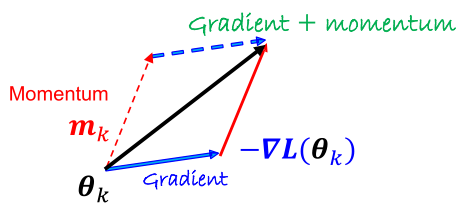
이러한 graident oscillation을 방지하는 technique으로 이전 parameter(일반적으로 직전 epoch의 gradient 값)의 momentum을 유지하는 알고리즘들이 사용된다.
Basic Momentum Algorithm
기본적으로 momentum algorithm이란 직전 epoch의 gradient 값에 대한 momentum을 exponential averaging을 통해 유지하는 방식을 말한다.
mt: t-th iteration에서의 momentum
β: momentum hyperparameter (주로 0.9)
θt: t-th iteration에서의 parameter vector
α: learning rate
mt=βmt−1+(1−β)∣Bj∣1i∈Bj∑∇θLi(θt−1)
θt=θt−1−αmt
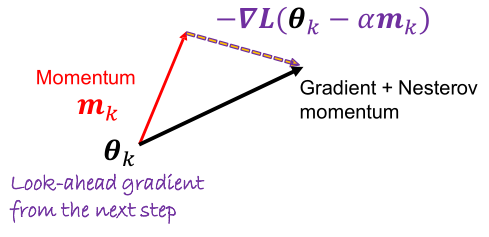
Nesterov Accelerated Gradient (NAG)
NAG는 gradient 계산을 momentum을 이용한 미래의 위치에서 계산한 후에, 이를 현재의 parameter update에 사용한다. 더 빠르고 안정적으로 수렴한다.
GD 알고리즘은 gradient의 크기에 따라 parameter의 조정량이 달라진다. 특히, 앞서 본 예제와 같이 pathological curvatures를 갖는 loss suface에서는 방향에 따른 gradient의 크기가 달라지기에, 양쪽 방향 모두에 대해 안정적인 learning rate를 선택하기가 어렵다.
이러한 이유로, gradient를 normalize하는 기법이 적용하기도 한다.
Normalize된 gradient를 사용하면, 각 방향으로 어느정도 일정한 크기로 이동할 수 있게 된다. 그러나 minimum에 정확히 도착하지 않으면 converge하지 않고, minimum의 근처에서 진동하게 된다.
이후 나올 Adagrad, RMSProp, AdaDelta, Adam은 모두 Normalizing Gradient 기법이 적용되었다.
Adagrad
지금까지 많이 변화한(gradient가 큰) 변수는 optimum에 가까울 것이기에 작은 learning rate로 업데이트하고, 지금까지 많이 변화하지 않은 변수는 learning rate를 증가시켜 빠르게 오차 값을 줄인다.
Sparse dataset에 대해서 잘 작동하지만, learning rate가 빨리 감소하기에 학습이 중간에 멈추게 될 수 있다는 단점이 있다.
gt=∣Bj∣1i∈Bj∑∇θLi(θt)
Gt=Gt−1+gt−1⊙gt−1
θt=θt−1−Gt+ϵαgt−1
Gt: 지난 gradient들의 누적 제곱합
ϵ: 0으로 나누는 것을 방지하기 위한 작은 값
계산 비용을 증가시키지 않기 위해 gradient 계산은 한 번만 진행한다.
RMSProp
Adagrad에서의 learning rate 급감 문제를 해결하기 위해, γ를 통한 exponential averaging을 사용하여 gradient 반영 비율을 조정한다.
gt=∣Bj∣1i∈Bj∑∇θLi(θt)
Gt=γGt−1+(1−γ)gt−1⊙gt−1
θt=θt−1−Gt+ϵαgt−1
AdaDelta
Learning rate에 대한 parameter를 없애고, 대신 parameter vector의 변화값(Δθt)에 관한 parameter st를 사용한다.
gt=∣Bj∣1i∈Bj∑∇θLi(θt)
Gt=γGt−1+(1−γ)gt−1⊙gt−1
Δθt=−Gt+ϵst−1+ϵgt−1
st=γst−1+(1−γ)Δθt⊙Δθt
θt=θt−1+Δθt
Adam
가장 널리 사용되는 방법으로, RMSProp과 momentum 방식을 융합한 알고리즘이다.
Momentum(mt)와 gradient의 second moment 정보(Gt)를 사용하여 parameter update를 진행한다.