
Data
연구 진행 중 데이터가 필요하여 Selenium 기반의 간단한 크롤러를 만들어볼까 한다.
개발 툴로는 Spyder 4.1.2 버전을 사용할 계획이며, 크롤러에 필요한 패키지는 selenium, urllib, pandas 총 3개의 패키지를 사용할 계획이다. 패키지와는 별개로 chromedriver 까지 필요로 한다.
install package
selenium : Selenium은 웹 테스트 프레임워크이며, 브라우저를 제어할 수 있기 때문에 로그인이 필요한 웹 사이트나 자바스크립트(JavaScript)로 동적으로 생성되는 웹 사이트의 데이터를 크롤링할 때 매우 유용하게 사용되는 스크래핑 도구
urllib : 한글 텍스트를 퍼센트 인코딩으로 변환하기 위한 quote_plus를 호출하기 위해 urllib을 설치
pandas : DataFrame을 만들고 csv 형태의 파일로 저장하는데 유용
Chromedriver
크롤링에 사용되는 기본적인 툴에는 chromedriver와 phantomjs가 있는데 이번 크롤러에는 chromedriver를 사용해볼까 한다.
chromedriver Download URL : https://sites.google.com/a/chromium.org/chromedriver/
 83.0.4103.39 버전이 존재하지만 신원미상의 오류가 발생할 가능성이 있기 때문에 stable 버전인 81.0.4004.138 버전을 사용할 것이다.
83.0.4103.39 버전이 존재하지만 신원미상의 오류가 발생할 가능성이 있기 때문에 stable 버전인 81.0.4004.138 버전을 사용할 것이다.
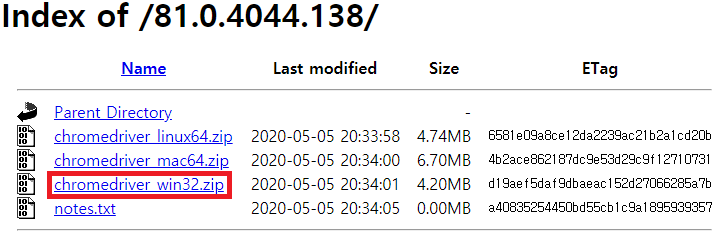 Windows 환경에서 테스트 후 우분투 CPU 서버로 이전할 예정이기 때문에 win32기반의 chormedriver를 다운로드 받는다.
Windows 환경에서 테스트 후 우분투 CPU 서버로 이전할 예정이기 때문에 win32기반의 chormedriver를 다운로드 받는다.
Test
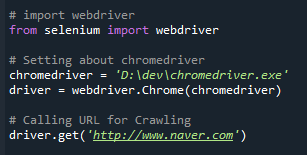 chromedriver의 path를 지정해주고, 정상적으로 동작하는지 간단한 확인을 진행하기 위해 네이버 메인페이지를 호출해보자.
chromedriver의 path를 지정해주고, 정상적으로 동작하는지 간단한 확인을 진행하기 위해 네이버 메인페이지를 호출해보자.

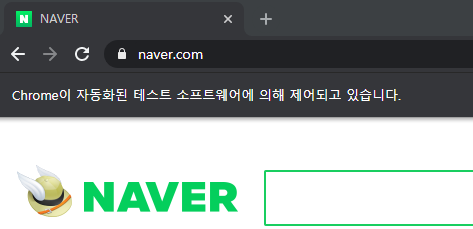 아무런 오류 없이 초록창이 떴다.
아무런 오류 없이 초록창이 떴다.
Function
driver.find
find_element_by_class_name() : class name이 최초로 일치하는 1개만 가져옴
find_elements_by_class_name() : class name이 일치하는 모든 값을 가져옴
find_element_by_xpath().click() : 해당 xpath 메소드를 클릭
time
time.sleep() : n초간 대기
기타 여러가지 Function을 이용하여 크롤링을 통해 원하는 데이터셋을 구축할 수 있다.
