데이터 마이닝의 단계와 단계별로 고려해야하는 점들을 잘 알아야한다.
Generic Steps
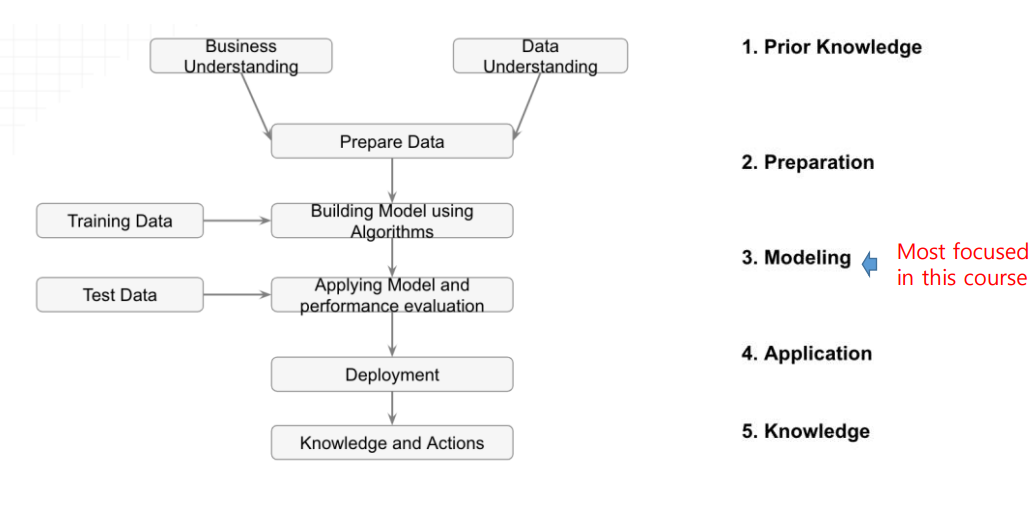
- Prior Knowledge - 현재 문제, 분야에 대한 사전 지식과 생성되는 데이터에 대한 이해. 이를 통해 어떤 데이터를 사용할 지를 결정할 수 있다.
- Preparation - Prior Knowledge에서 결정된 데이터를 Mining할 때 더 효율적이고 원하는 포맷으로 전처리한다.
- Modeling - 데이터가 준비되면 학습할 데이터에 대해 적용할 모델, 알고리즘을 설계하고 학습시킨다. 학습된 모델에 대해 Test를 통해 성능을 측정하고 개선시키는 과정이 반복될 수 있다.
Step 1. Understanding Business/Data
- Prior knowledge in the objective of business
- 해결해야하는 문제가 무엇인지 (Classification, Regression, etc.)
- Prior knowledge in the subject area
- 문제와 관련된 일, 과정이 어떻게 이루어 지는지
- Prior knowledge in the data
- 데이터가 저장되고 변환되고 사용되는 방식
- 문제와 관련된 데이터,특성이 어떤 것이 있는지
- 데이터들 중 문제 해결을 위해 어떤 데이터가 필요한지
- Terminology
- Data Set - Structured Data의 집합, 모음
- Data Point(Instance,Sample) - Data Set에서 each row
Step 2. Data Preparation
- 가장 시간이 많이 들고 중요한 과정
- Data Mining Algorithms에서 필요한 만큼 잘 만들어진 데이터는 거의 없다. - 구조화되지 않거나 틀리거나 빠진 데이터들이 존재한다.
- Data Preparation에서 할 일
- Data exploration
- Handling data quality and missing values
- Data types and conversion, transformation,
- Outliers, feature selection, data sampling
Data Exploration
데이터를 어떻게 처리할 지 결정하기 위해 데이터를 조사, 탐색. 문제 해결 방향에 대한 방향을 잡아가는 과정
Handling Data Quality
- Data Clening을 통해 데이터의 품질을 높인다
- 중복된 데이터 제거. 중복에 대해 편향되어 성능을 낮출 수 있다.
- 이상치(outlier) 데이터 제거. 예측하고자 트렌드, 경향에 대해 이상치를 반영하면 모델의 성능을 낮출 수 있다.
- 빠진 데이터(missing value)에 대한 처리
- 데이터 값에 대한 표준화
Handling Missing Value
- 데이터 셋에서 특성 값이 빠진 이유를 이해하고 이에 대해 처리해야한다.
- 방법1. missing value에 데이터 셋의 해당 특성에서 도출될 수 있는 값을 넣는다. ex) mean, min, max, median 중 어떤 것을 사용할 지는 상황에 따라 선택
- 방법2. missing value가 포함되는 record(instance)를 제거한다. 이 때 데이터 셋의 사이즈가 적어져 데이터가 많지 않을 때는 좋지 않을 수 있다.
Data Types and Conversion
- 목적에 따라 특성 값의 타입을 변환해야 하는 경우가 있다.
- Categorical, Numeric Value, Integer Numeric, etc..
- Regression 문제에서는 Categorical 값을 numeric value로 변환해야 성능이 개선된다.
Transformation
- 어떤 특성이 다른 특성들과의 값의 범위보다 많이 클 경우에 결과에 Dominate 할 수 있다. 이 경우 normalize를 통해 값의 범위를 동일하게 만들어야 한다.
- [0,1]의 범위로 정규화
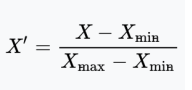
- 표준 점수로 변환
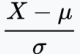
Outlier
이상치(Outlier)가 예측하거나 해결하려는 경향에 안좋은 영향을 줄 수 있다.
Feature Selection
주어진 데이터 셋에서 어떤 Feature를 학습을 위해 사용할 지 선택하는 과정.
- Curse of Dimensionality - Feature의 수가 커질수록 모델이 Complex해지고 성능이 하락할 수 있다. Dimensionality가 높을수록 Data는 Sparse 해진다.
- 모든 Feature가 문제 해결에 중요하지 않을 수 있고, 상관관계가 있는 데이터도 존재한다. 이러한 Feature를 줄이는 것이 성능이 더 향상된다.
Data Sampling
데이터 셋에서 sample(instance)을 고르는 과정.
- 데이터가 많은 경우 학습에 시간이 많이 소요되므로 가지고 있는 데이터 셋의 특성을 파악하기 위해 사용
- 학습 데이터와 테스트 데이터를 나누기 위해 사용
Step 3. Modeling
주어진 데이터 셋 사이의 관계를 잘 표현하는 모델을 설계하고 학습시키는 단계. 풀려고 하는 문제에 따라 모델의 구조가 달라진다.
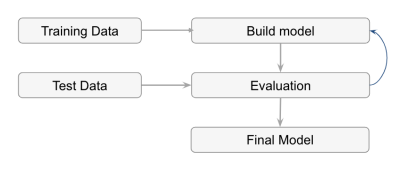
- 학습 데이터 셋과 테스트 데이터 셋의 크기 비율은 상황에 따라 적절하게 구성해야한다.
