
자연어 처리에서, 단어의 표현 방법은 크게 Local Representation과 Distributed Representation으로 구분된다. local representation은 해당 단어 그 자체만을 확인하고 특정 값을 mapping하여 단어를 표현하는 방법이며, distributed representation은 어떤 단어 주위의 단어 분포를 고려하여 단어를 표현하는 방법이다. 단어의 표현 방법은 다음 그림에서 나타나는 것과 같이 구분할 수 있다.
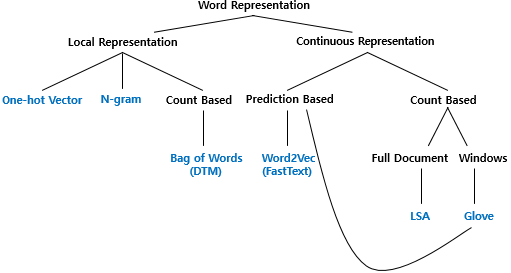
본 포스트에서는 local representaiton 중 카운트 기반의 단어 표현법들을 정리하고, 이를 이용한 가중치인 TF-IDF에 대해 알아본다.
Bag of Words (BoW)
BoW는 단어들의 순서를 고려하지 않고 출현 빈도에만 집중하는 텍스트 데이터의 표현 방법이다. 다음 문서를 보자.
정부가 발표하는 물가상승률과 소비자가 느끼는 물가상승률은 다르다.
BoW를 만들 때에는 다음의 두 과정을 따른다.
1. 각 단어에 고유 정수 인덱스를 부여하여 Bag을 생성한다.
2. 각 인덱스의 위치에 단어 토큰의 등장 횟수를 기록한 벡터를 생성한다.
이 과정을 따라 위 문서를 BoW로 표현하면 다음과 같다.
vocabulary : {'정부': 0, '가': 1, '발표': 2, '하는': 3, '물가상승률': 4, '과': 5, '소비자': 6, '느끼는': 7, '은': 8, '다르다': 9}
BoW vector : [1, 2, 1, 1, 2, 1, 1, 1, 1, 1]Document Term Matrix (DTM)
DTM은 다수의 문서에서 등장하는 각 단어들의 빈도를 행렬로 표현한 것이다. 조금 더 쉽게 표현하면, 여러 문서에 대한 BoW를 행렬의 형태로 나타낸 것이다. 다음 네 개의 문서를 보자.
- 나는 맑은 봄에 꽃을 구경했어요.
- 정원에서 색다른 꽃을 구경했어요.
- 나는 꽃을 좋아하고 정원 가꾸기를 즐겨요.
- 봄에는 아름다운 꽃들이 만발해요.
Lemmatization과 stopword 제거를 거쳐 이 문서들의 모든 단어를 추출하면 다음과 같다.
나, 맑다, 봄, 꽃, 구경하다, 정원, 색다르다, 좋아하다, 가꾸다, 즐기다, 아름답다, 만발하다이 단어들을 각각의 열로 하고, 각 문서를 행으로 하여 표를 구성해 보면 다음과 같다.
| 문서 | 나 | 맑다 | 봄 | 꽃 | 구경하다 | 정원 | 색다르다 | 좋아하다 | 가꾸다 | 즐기다 | 아름답다 | 만발하다 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
| 3 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 1 | 1 | 0 | 0 |
| 4 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
이 표의 내용을 DTM이라고 한다.
TF-IDF
TF-IDF는 DTM 내의 각 단어에 대한 중요도를 계산할 수 있는 가중치이다. 주로 문서의 유사도를 구하는 작업 등에 활용된다.
Term Frequency (TF)
TF는 특정 문서 d에서 단어 t의 등장 횟수를 의미한다. 위 절의 표를 다시 보자. 각 단어들이 가진 값이 TF가 된다.
Document Frequency (DF)
DF는 특정 단어 t가 등장한 문서의 수를 의미한다. 아래의 표와 같이 DTM에서 각 열의 값을 모두 더한 것이 DF이다.
| 구분 | 나 | 맑다 | 봄 | 꽃 | 구경하다 | 정원 | 색다르다 | 좋아하다 | 가꾸다 | 즐기다 | 아름답다 | 만발하다 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
| 3 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 1 | 1 | 0 | 0 |
| 4 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
| DF | 2 | 1 | 1 | 4 | 2 | 2 | 1 | 1 | 1 | 1 | 1 | 1 |
Inverse Document Frequency (IDF)
IDF는 다음과 같은 식을 이용하여 구한다.
이때 은 총 문서의 수이다. IDF의 스케일을 작게 유지하기 위하여 DF의 역수에 를 취하여 IDF를 구한다. 다음과 같이 IDF를 구할 수 있다.
| 단어 | IDF |
|---|---|
| 나 | 0.28768207245178085 |
| 맑다 | 0.6931471805599453 |
| 봄 | 0.6931471805599453 |
| 꽃 | -0.2231435513142097 |
| 구경하다 | 0.28768207245178085 |
| 정원 | 0.28768207245178085 |
| 색다르다 | 0.6931471805599453 |
| 좋아하다 | 0.6931471805599453 |
| 가꾸다 | 0.6931471805599453 |
| 즐기다 | 0.6931471805599453 |
| 아름답다 | 0.6931471805599453 |
| 만발하다 | 0.6931471805599453 |
TF-IDF
TF-IDF는 TF와 IDF를 곱한 값이다. 이는 각 문서의 각 단어에 대해 계산된다.TF-IDF값을 통하여 각 문서에서 어떤 단어가 중요한지 알 수 있다. DTM절의 표에서 각 단어에 해당하는 IDF값을 곱하기만 하면 되므로 여기서는 계산은 생략한다.
참고자료
[1] 유원준 & 안상준, "Chapter 3: 언어 모델" in 딥 러닝을 이용한 자연어 처리 입문. Wikidocs.

아주 유용한 정보네요!