
1. Introduction
- 기존
RNN이나 일부만attention을 사용하던 구조에서 전체적으로attention만을 사용한 구조로 등장하여 기존 모델 대비 높은 성능을 보여주었다.- 연산량을 줄이기 위해 고안된
convolution기반의ConvS2S나ByteNet의 연산량은input과output에 선형적으로 증가하거나(O(N)), 로그에 비례했지만(O(logN))Transformer구조는 연산량을 상수 단위(O(k))로 줄였다고 한다.
2. Model architecture
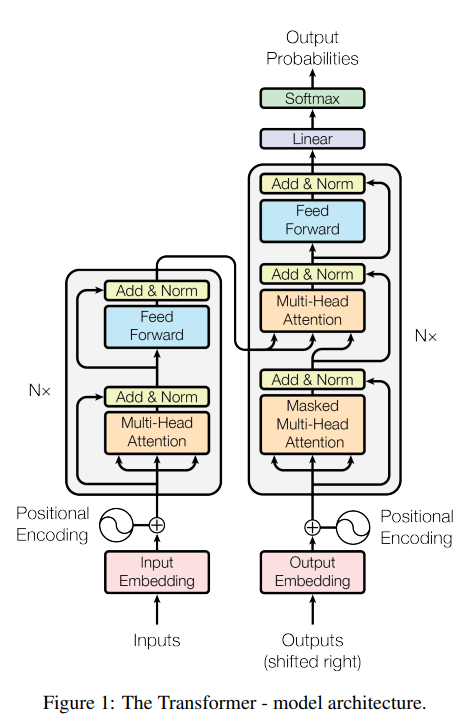
1) Encoder
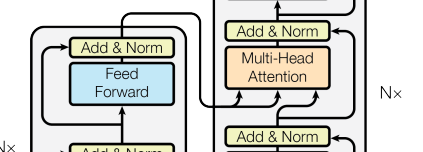
multi-head self-attention과position-wise feed-forward로sub-layer를 이루며 동일한 구조로 N(=6)번 반복된다.- 각
sub-layer를 통과한 후에는residual구조와LayerNorm을 적용해준다.
:residual connection을 위해 모든sub-layer와embedding layer는 크기의output dimension을 가진다.
2) Decoder
- Encoder와 같이 N(=6)번 반복되는 구조
- Encoder의
output을 입력으로 받아multi-head attention을 수행하는sub-layer가 추가됨- Encoder에서와 마찬가지로
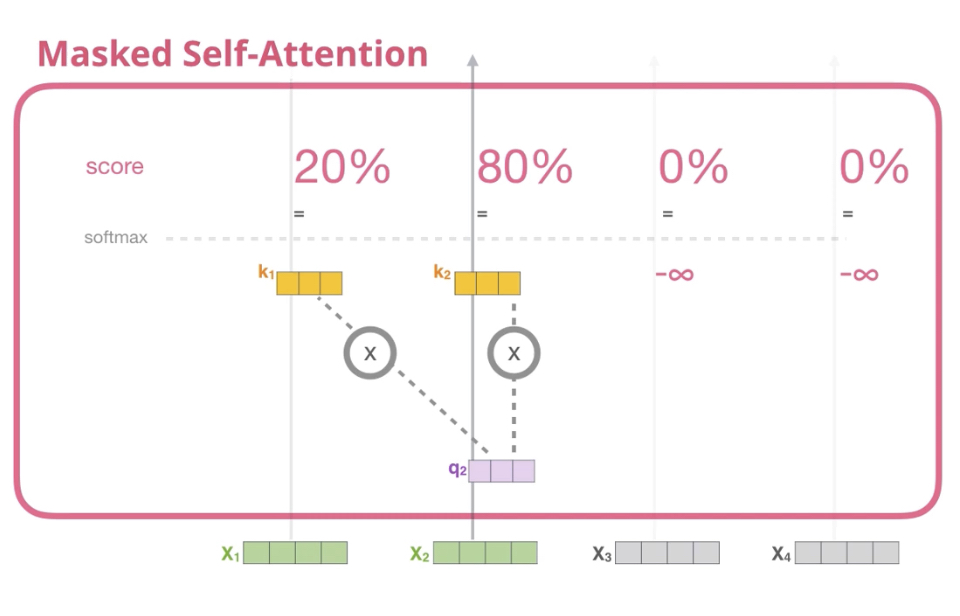
residual connection과LayerNorm이 적용됨- 이후의 position에 주의(attention)를 주는 것을 막기 위해
masked multi-head attention구조를 사용
- 번째 예측을 위해서는 번째 이전 position들만 사용
- 이후의 position들에는
-inf값을 주어softmax계산시 0이 되도록 함
참고블로그: https://acdongpgm.tistory.com/221
3) Attention
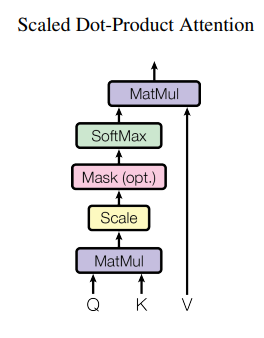
query와 한쌍의key-value를 mapping하여attention output을 얻는 구조query와key를 점곱하여weight를 얻고,weight와value를 곱해(=weighted sum)attention output을 구함
Scaled Dot-Product Attention
query와key는 ,value는 의 차원을 가짐- 구한
weighted value에 로 나누어줌으로써Scaling을 함
-feed-forward network를 사용하는additive attention도 있지만 속도와 공간 효율면에서dot-product attention을 사용하였다고함.scaling과정이 없을 경우,softmax사용시 너무 작은gradient를 만들어 낼 우려가 있어 추가하였다고 함.
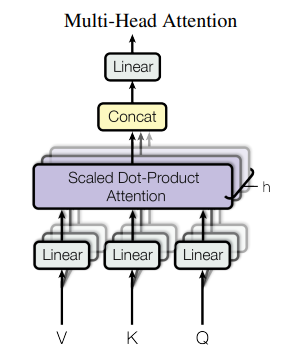
Multi-Head Attention
attention head를 하나만 두는 것 보다, 여러개 둘 수록 성능이 더 좋다고 한다.- 병렬적으로
weighted value를 구하고concat-projection과정을 통해 최종output을 얻어낸다고 한다.Multi-head attention은 다양한representation subspace정보의attention을 얻는데 도움이 된다고 한다.
Encoder-decoder attention
encoder(key, value)decoder(query)encoder에서 가져온key,value와 결합한 덕분에decoder는input sequence의 position에attention을 줄 수 있다.
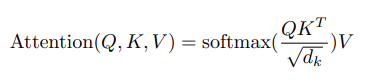
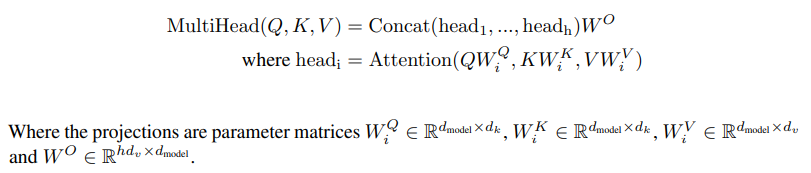
4) ETC
Position-wise Feed-Forward Network
Embedding and Softmax
input/output token을 차원으로 바꾸기 위해learned embedding을 사용decoder의ouput에서 다음 토큰의 확률을 예측하기 위해서도learned linear transform을 사용- 위 두 부분에서 같은 가중치를 공유한다고 한다. 대신
embedding layer에서는 을 가중치로 곱해준다고 한다.
Positional Encoding
recurrence나convolution구조가 없기 때문에sequence정보를 모델에 추기 위해 토큰의 상대적/절대적 위치정보를 추가하였다고 한다.
cos대신 학습데이터보다 더 긴sequence길이를 외삽할 수 있는sin정현파를 사용하였다고한다.
Regularization
Residual Dropout:sub-layer에서residual connection전에,positional embedding을 더한 후 적용했다고 한다. =0.1Label Smoothing:perplexity와 모델은 불안정해졌지만BLEU score는 올랐다고 한다.
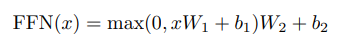
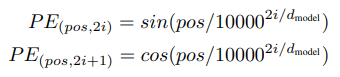
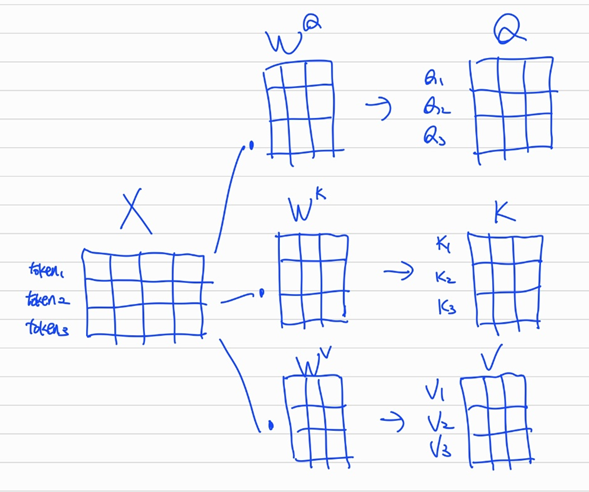
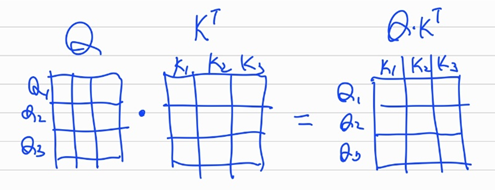
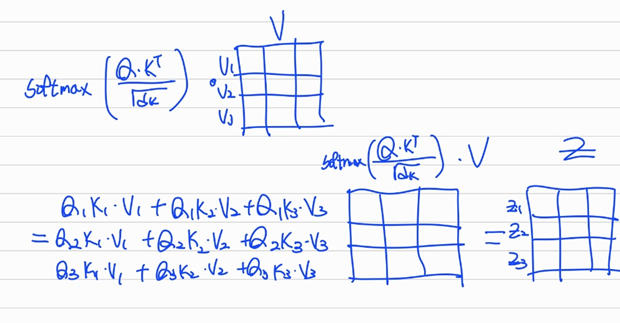
조금 더 이해하기
1)
input()에 를 행렬곱해 를 얻어낸다.
2) 얻어낸 와 를 행렬곱하여weight를 만든다.
3)weight에 로 나누어 값이 너무 커지지 않도록 막고,softmax를 취해 합이 1이되는weight를 만든다. 그 후 와 행렬곱을 통해 가중합을 구한다.
4) 이렇게 만들어진 는 다음block으로 전달된다.

인공지능 꿈나무