Code

1. Abstract
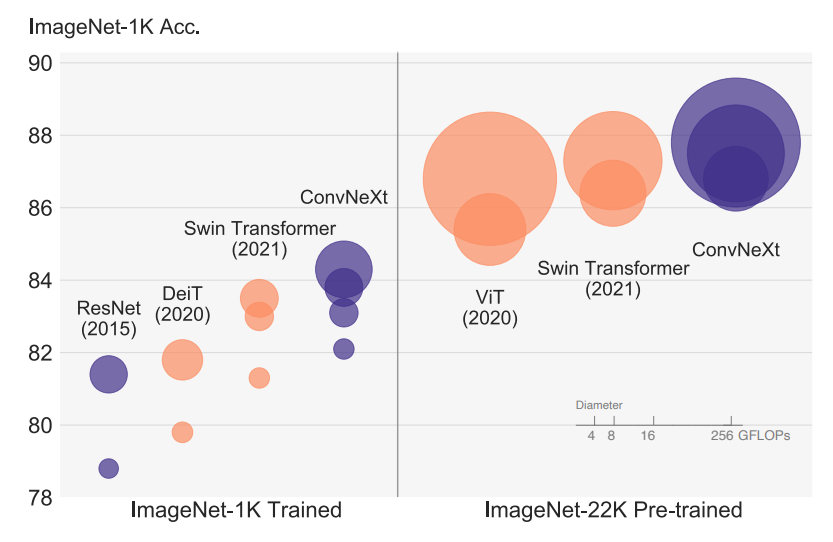
vanilla ViT는 일반적인 컴퓨터비전에서 성능이 좋지 않지만Hierarchical Transformers인Swin Transformers는 좋은 성능을 보여준다- 이 논문에서는 기존
Conv layer구조의 모델을ConvNext구조로 변경만 했다.ConvNet의 단순함과 효율성을 유지하면서 아래 세 가지의 task에서Swin Transformers보다 더 좋은 성능(scalability,accuracy)을 기록했다.
ImageNet(classification)COCO(object detection)ADE20K(segmentation)
2.Introduction
ViT는 높은 성능을 보여주지만input image크기의 제곱의 계산량이 필요해 고해상도에 이미지에서는 다루기 힘들다.ConvNet의sliding windows구조가 가지고 있는 inductive bias(참고링크)인 translation equivariance로 인해object detection등의task에서 더 좋은 성능을 보인다
- translation equivariance: 어떠한 사물의 이미지에서 사물의 위치가 바뀌면 CNN과 같은 연산의
activation feature의 위치 또한 바뀌게 되는 것
- 이 문제를 해결하기 위해
Hierarchical Transformers들이 등장했다.
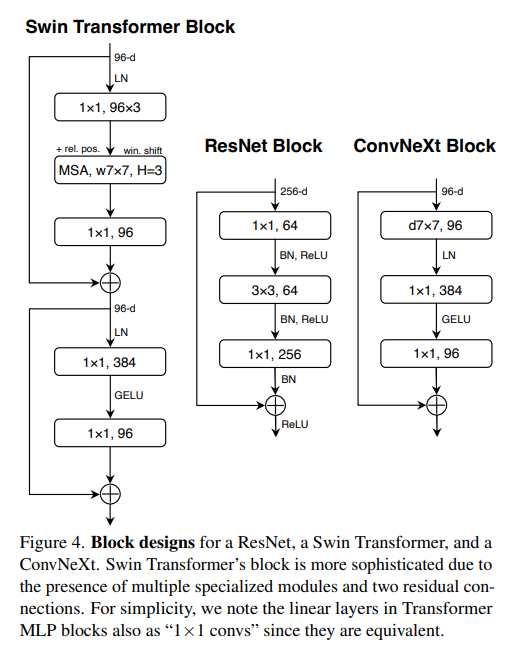
Hierarchical Transformers:ConvNet과 일부 유사한 구조를 가지고sliding windows를 채택한 모델. ex)Swin TransformersSwin Transformer는classification task이외에도 좋은 성능을 가지고 여러 분야에서backbone역할을 수행하는 첫번째Transformers모델이 되었다.- 논문 저자는
Swin Transformers의 성공이Convolution연산이 의미가 있음을 나타낸다고 설명하였다.- 이 논문의 목적은
ConvNet과Transformers사이의 구조적 차이를 조사하는 것이라고 한다.pre-ViT와post-ViT시대를 연결 짓는 것이 목적이라고.- 성능 차이의 주요한 요인이 되는
key components들을 찾았고 기존ConvNet구조의 성능향상에 큰 도움이 되었다고 한다.
3. Modernizing a ConvNet: a Roadmap
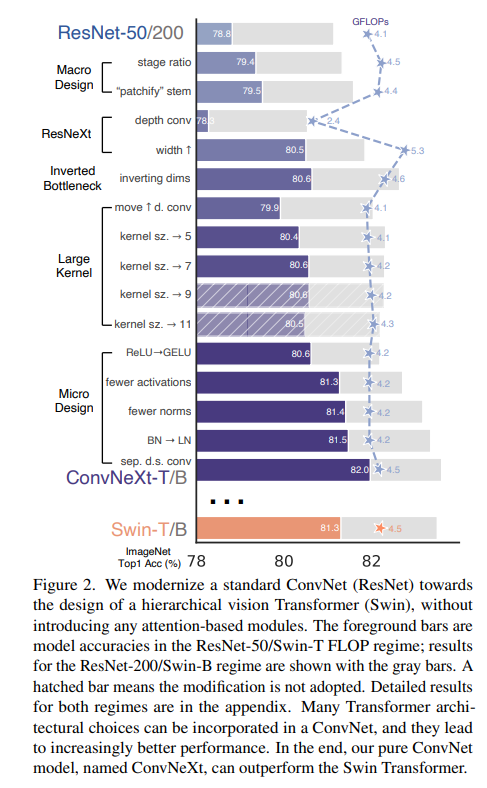
ResNet-50모델을baseline으로 하여 다음과 같은 실험을 진행했다.
1)macro design
2)ResNeXt
3)inverted bottleneck
4)large kernel size
5)various layer-wise micro designs
3.1 Training Technic
- 저자는 학습방법이 모델 성능에 중요한 요소가 된다고 하였다
- 다음의 학습 방법을 사용하여
basemodel인ResNet-50의 성능을 기존보다 2% 끌어올렸다.
1)epoch 90 -> 300
2)AdamW
3)Mixup,Cutmix,RandAugment,RandomErasing,
4)regulization scheme for StochasticDepth
5)Label Smoothing- 저자는 전통적인
ConvNets과Transformers의 성능차이는 학습방법이 상당한 비율을 차지한다고 생각했다
3.2 Macro Design
- Changing stage compute ratio
ResNet은4개의 stage중 마지막인4번째 stage에서 가장 많은 연산량을 가진다. 하지만Swin-T의 경우1:1:3:1또는1:1:9:1의 비율로 세번째stage에서 가장 많은 연산량을 가진다Swin-T를 모방해3번째 stage에서 모델의 연산량이 많아지도록 조정했다.
:(3, 4, 6, 3)->(3, 3, 9, 3)- 이 과정에서
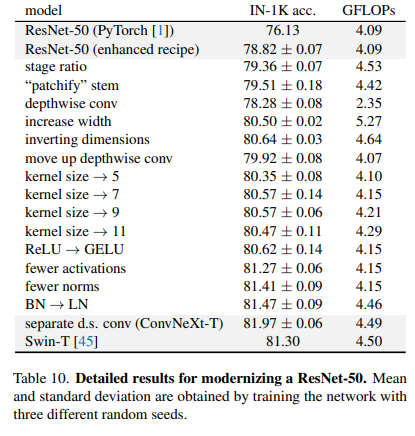
78.8%에서79.4%로 성능향상이 이뤄졌다고한다.
- Changing stem to "Patchify"
- 기존
ResNet의7x7 conv, stride=2의 구조를 갖는stem block을ViT모델들의 갖는patchfiy layer의 형태인4x4 conv, stride=4로 바꾸어 주었다.79.4%->79.5%
- ResNeXt-ify
ResNeXt모델의grouped convolution의 일종인depthwise convolution구조를 추가했다.depthwise convolution은MobileNet,Xception등에서 주로 쓰이는 구조라고 한다.depthwise convolution이 채널별 공간 정보를 이용transformer의self-attention에서의weighted sum operation과 유사하다고 하였다.depthwise conv와1x1 conv의 조합을 사용함으로써vision Transformers처럼 공간정보와 채널정보를 각각 학습시킬 수 있었다(?)
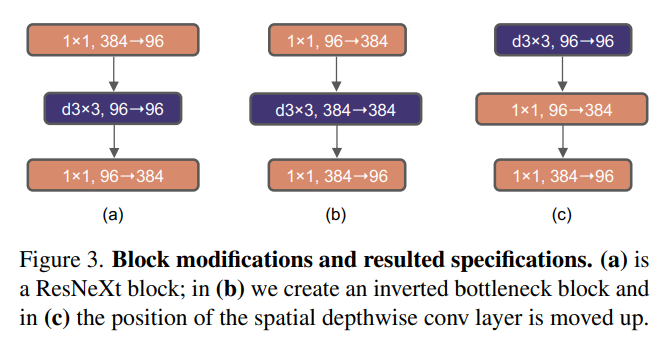
- Inverted Bottleneck
- 모든
Transformer block에서 중요한 것 중 하나는inverted block이라고 한다.
inverted block은input dimension보다 더 큰hidden dimension을 갖는 것을 말한다.network의 깊이가 깊어졌음에도 불구하고 모델의FLOP은 감소했으며 성능은 약간 상승했다고 한다
- Large Kernel Sizes
- 논문의 저자들은
vision transformer에서global receoptive field를 갖게해주는non-local self-attention에 주목했다VGG이후로conv layer의kernel size는3x3이 이용되어 왔지만,Swin Transformers에서self-attention block에 대한7x7 이상의 local window가 다시 조명 받았다.large kernel을 탐색하기 위해depthwise conv layer를 위로 올렸다고 한다 (Figure 3. (b) -> (c))- 이것은
Transformers에서MSA block(≒large kernel conv)이MLP layers앞에 놓이는 것을 참고하였다고 한다.3, 5, 7, 9, 11의kernel size를 실험했고7x7 conv layer를 사용했을 때 가장 좋은 성능을 보였다고 한다.
3.3 Micro Design
- GELU
: 성능향상은 없었지만 최근GELU가ReLU보다 상위 호환이라는 것이 밝혀졌다고 한다. 그래서 성능향상은 없었지만GELU를 사용했다고 한다.
- Fewer activation funtions
Transformers구조에는 적은activation만 사용된다는 점에 착안해서ConvNeXt에서는1x1 conv layer를 제외한 모든 layer에서activation function을 빼버렸다고 한다. 그 결과로Swin-T와 일치하는 성능인81.3%의 성능을 얻었다고 한다.
- Fewer normalization layers
activation과 마찬가지로Transformers에서는 적은normalization layer를 사용한다고 한다. 그래서 저자들은 2개의BN을 하나만 남겨1x1 conv layer전에만 사용했다고 한다.- 이 결과로
Transformers block에서 사용되는 것보다 더 적은normalization을 사용하게 되었고,81.4%의 성능을 얻어Swin-T의 성능을 뛰어넘었다고 한다.- 또한
Blcok의 처음에BN layer를 추가하는 것은 성능을 향상시키지 못한다고 하였다
- Substituting BN with LN
Transformers에서 사용된Layer Normalization이 기존ResNet에서는 성능이 좋지 않았지만,ConvNeXt에서는 약간의 성능향상이 있었다고한다.
- Separate dwonsampling layers
- 기존
ResNet은 각stage의 첫 부분에서spatial downsampling이 이루어졌다. 하지만Swin Transformers에서는stage사이에down sampling layer가 추가되었다고한다.Swin-T와 유사한 구조로 만들기 위해2x2 conv, stride=2를 사용하여down sampling을 하였다고 한다. 하지만 이것은 학습이 수렴하지 못하게 했다고 한다.- 추가 연구 끝에
spatial resolution이 변할 때normalization layer를 추가하는 것이 학습을 안정화시킨다는 것을 발견했다고 한다.- 최종적으로 성능을
82%로 향상시킬 수 있었다고 한다.
3.4 evaluation

4. Empirical Evaluation on Downstream Tasks
object detection and segmentation on COCO
Swin Transformer를 따라multi-scale training,AdamW optimizer,3x scheduler를 사용하였다고, 전반적으로Swin-T보다 더 좋은 성능을 보여주었다고 한다.
Semantic Segmentation on ADE20K
UperNet을 사용하였고 좋은 점수를 얻을 수 있었다고 한다.
model efficiency- 기존
ConvNet들 보다 많은 메모리를 사용하고 느려졌지만, 학습 시Swin-T보다는 적은 메모리를 요구하며 성능은 향상되었다고 한다.

5.Others
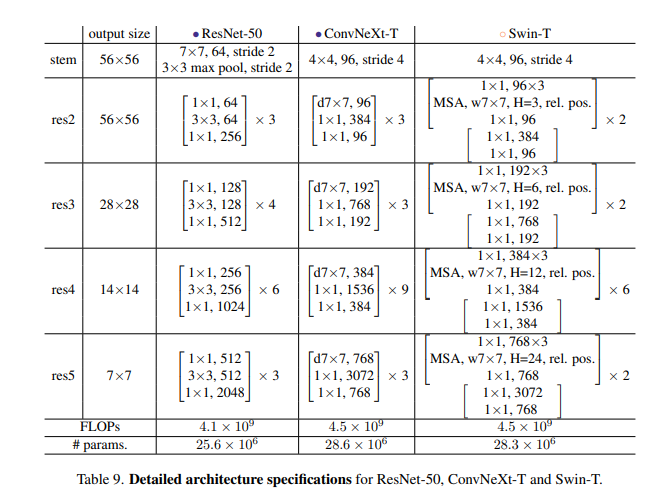
5.1 model architecture
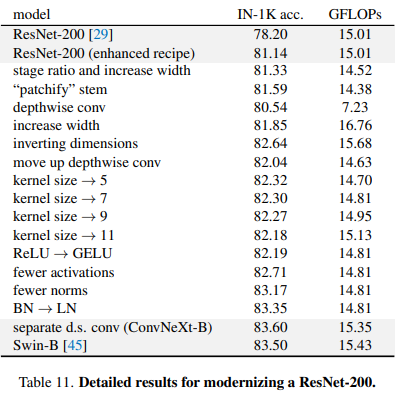
5.2 Detailed result

인공지능 꿈나무