PaperReview
1.[Review]ImageNet Classification with Deep Convolutional Neural Networks, 2012
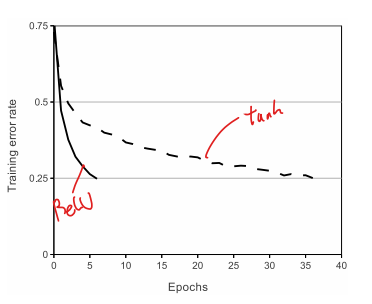
Image Classification competition인 ImageNet LSVRC-2010, ImageNet LSVRC-2012에서 Deep Convolution Neural Networks를 사용하여 1위를 차지한 모델을 소개한다. 이미지 분류를 위해 약 6천만
2.[Review]Network In Network, 2014
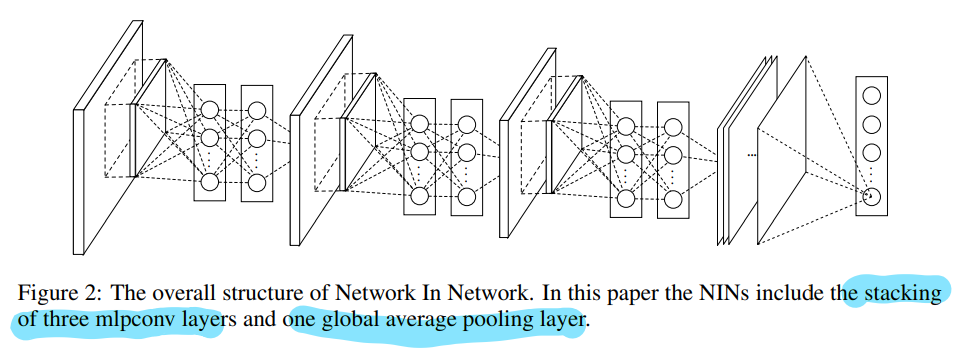
Network In Network Min Lin, Qiang Chen, Shuicheng Yan Introduction Convolutional Neural Networks Network In Network MLP Convolution Layers Global
3.[Review]VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION, 2015
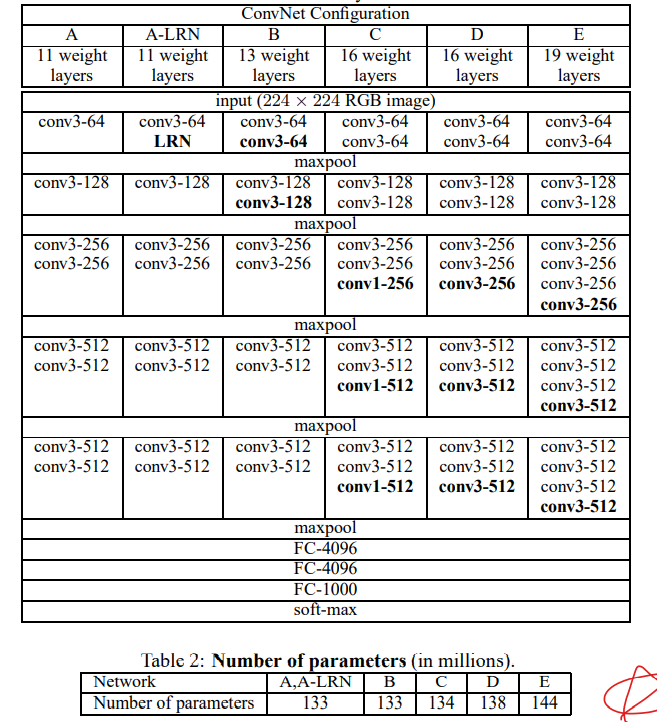
흔히 VGG-Net으로 불리는 convolution model의 논문이다. Imagenet Challenge 2014에서 classfication 부분 2위, localization 부문 1위를 차지하였다.convolutional network의 depth에 따른 정확
4.[Review]Going deeper with convolutions
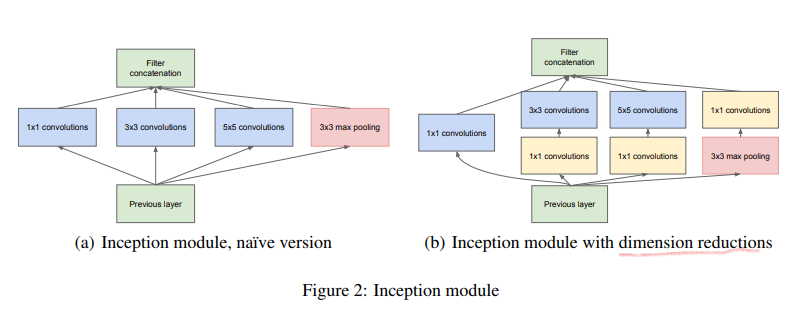
AlexNet보다 12배 적은 파라미터로 더 좋은 성능을 얻어냈다Network in network 논문으로부터 아이디어를 얻은 "Inception" 모듈을 사용하여 network를 더욱 깊게 만들 수 이었다. 현재 CNN pipeline에서 쉽게 사용할 수 있음comp
5.[Review]Squeeze-and-Excitation Networks(SENet)

SENet >* 기존 방법론들과 다르게 channel relationship에 주목한 논문 Squeeze-and-Excitation(SE) block을 사용 SE block을 사용하여 기존의 SOTA모델들도 개선할 수 있음을 보여줌 channel간 non-linear dependency를 제공함으로써 network의 representational powe...
6.[Review] ConvNeXt - A ConvNet for the 2020s
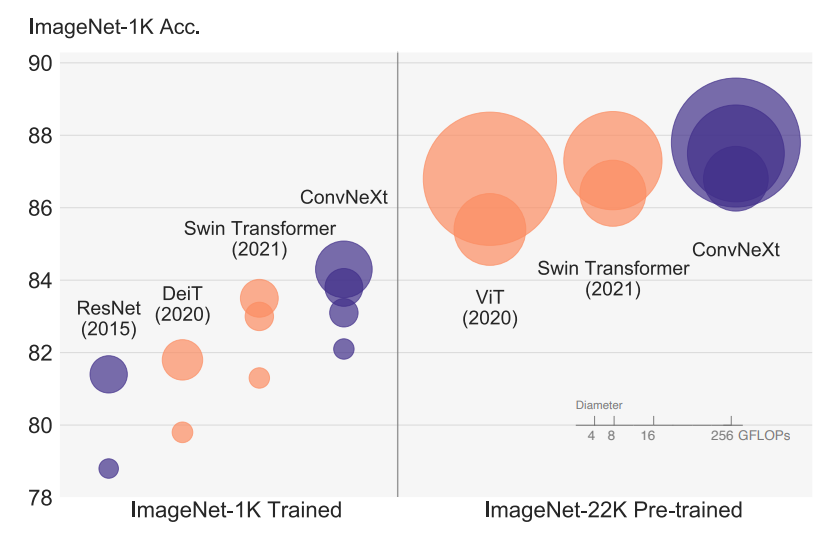
Code vanilla ViT는 일반적인 컴퓨터비전에서 성능이 좋지 않지만 Hierarchical Transformers인 Swin Transformers는 좋은 성능을 보여준다이 논문에서는 기존 Conv layer구조의 모델을 ConvNext 구조로 변경만 했다.C
7.[Review] Transformer: Attention Is All You Need

github기존 RNN이나 일부만 attention을 사용하던 구조에서 전체적으로 attention만을 사용한 구조로 등장하여 기존 모델 대비 높은 성능을 보여주었다.연산량을 줄이기 위해 고안된 convolution기반의ConvS2S나 ByteNet의 연산량은 inpu
8.[Review] AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE (ViT)

ViT이전에 computer vision에서 attention 구조는 실용적으로 좋은 성능을 내지 못했음Transformer구조에 영감을받아 1) image를 patch로 쪼개고2) patch들의 sequence를 모델의 input으로 사용하는 구조를 고안했다고함.여기
9.[Review]Learning Statistical Texture for Semantic Segmentation

CVPR 2021에서 발표된 논문 github 1. Introduction > 기존의 semantic segmentation 모델들은 contextual information in high-level feature에 집중했다. :high-level layer만을