VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION, 2015
Karen Simonyan∗ & Andrew Zisserman
Visual Geometry Group, Department of Engineering Science, University of Oxford
Introduction
- 흔히 VGG-Net으로 불리는 convolution model의 논문이다. Imagenet Challenge 2014에서 classfication 부분 2위, localization 부문 1위를 차지하였다.
- convolutional network의 depth에 따른 정확성에 대해 여러 실험을 하여 좋은 결과를 얻어낸 논문이다.
- depth가 model 성능에 미치는 영향을 알기 위해서 모형의 다른 파라미터들은 고정시킨 후 network의 depth를 증가시키며 성능을 비교한다(최대 19 layers)
- depth를 최대한으로 늘리기 때문에 convolutional filter의 크기는 최소인 3x3으로 사용한다.
ConvNet Configurations
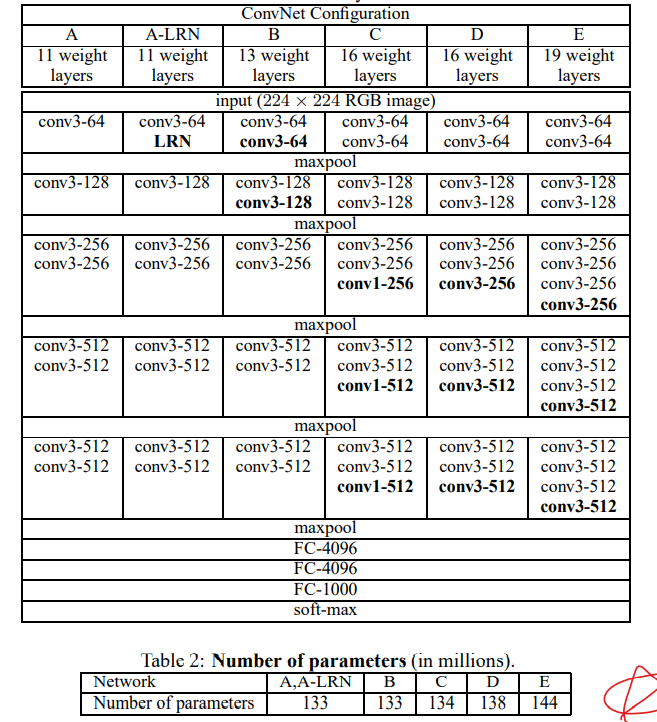
-
RGB pixel의 평균 값을 구해 각각의 pixel에서 빼주는 normalization이 유일한 전처리 과정이라고 한다.
-
convolutional filter(recptive field)는 상하좌우, 가운데를 파악할 수 있는 가장 작은 단위인 3x3를 사용한다.
-
stride는 1을 적용하였고, convolution 연산 전, 후의 input, output의 map 크기를 같게하는 padding을 추가하였다. (ex. filter가 3x3일경우 padding=1)
-
pooling 연산은 convolution 연산 후에 max-pooling에 의해 수행되며, 2x2 window, stride=2를 따른다.
-
conv. layers 후에 FC layer를 사용하여 classification을 진행한다.
-
모든 활성화함수는 ReLU를 사용하였다.
-
AlexNet에서 등장하였던 Local Response Normalisation(LRN)은 성능향상에 도움이 안되었다.
-
conv.layer의 channel(width)는 max-pooling 연산 후에 2배로 증가하였으며 64로 시작하여 최대 512까지 증가한다.
-
매우 깊은 depth의 network에도 불구하고, VGG의 가중치의 수는 큰 conv를 가진 얕은 모델에 비해 많이 크지 않았다. (표의 AlexNet(A)와 비교했을때 큰 차이를 보이지 않는다.)
-
depth 16인 모델에서 3x3대신 1x1의 filter을 사용하여 reception field에는 영향을 주지않는 모델을 설계하였었지만 모두 3x3 filter를 사용하는 모델보다는 성능이 하락하였다고 한다.
깊은 신경망의 특징
-
2층의 3x3 conv.layer는 하나의 5x5 receptive field와 같은 효과를 갖고, 3층의 3x3 conv.layer는 7x7 receptive field와 같은 효과를 갖는다고한다.
--> 즉, 3층의 3x3 conv.layers와 1층의 7x7 conv.layer가 보는 맵의 영역이 같다는 뜻이 된다. -
한 층 대신 여러 층을 겹쳐 사용함으로써 더 많은 비선형적인 특성을 뽑아 낼 수 있다.
-
더 적은 파라미터를 사용한다.
--> 3x3 filter에서는 (3 layer) x (3x3xCxC)(=27C^2) 의 파라미터를 사용하고, 7x7 filter에서는 (1 layer) x (7x7xCxC)(=49C^2)의 파라미터를 사용한다.
Classification Experiments
S: train image size
Q: test image size
single Scale Evaluation
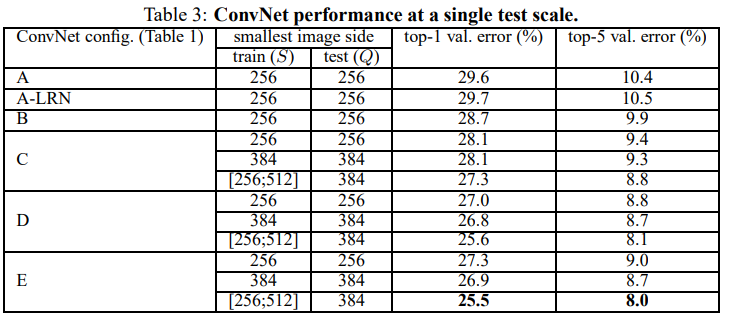
-
fixed S일 때, Q=S를 사용하였고, unfixed(jittered) S일 때는 Q = S의 중앙값을 사용하였다.
-
LRN을 사용한 모델(A-LRN)이 기존 A모델에 비해 성능이 하락한 것을 확인할 수 있다.
-
1x1 conv.layer를 사용한 모델(C)이 사용하지 않은 모델(D)보다 낮은 성능인 것을 확인할 수 있다.
-
S가 unfixed(jittered)된 모델이 성능이 가장 좋았다
Multi-Scale Evaluation
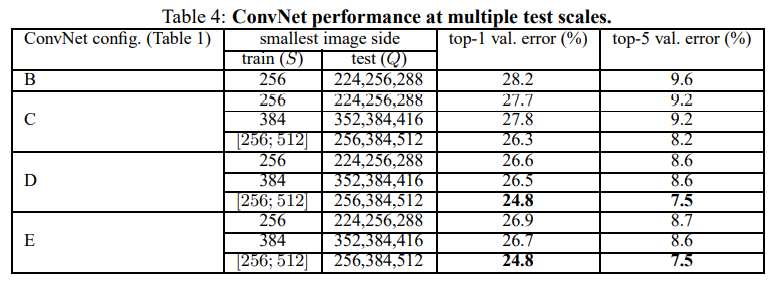
- 앞의 single Scale Evaluation 방법과는 달리 test시에 여러 image size들을 이용하여 prediction하는 방법이다. 이 경우 Q의 값은 S최솟값, S중앙값, S최댓값 이렇게 3가지가 된다.
- 3가지 Q를 통해 얻은 결과값을 평균내어 최종 예측에 사용한다
- 앞의 single-scale evalutation의 경우보다 성능이 향상되었다.
- single scale evaluation과 마찬가지로 S가 unfixed(jittered)된 모델이 성능이 가장 좋았다
Multi-Crop Evaluation
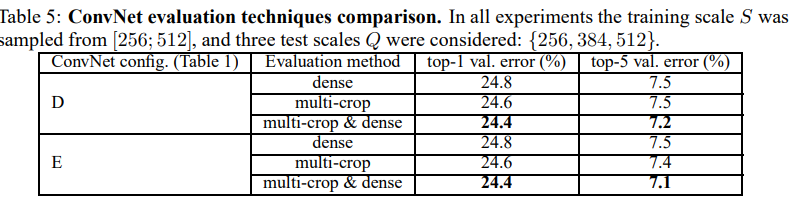
- multi-crop과 dense 방법을 결합하여 성능을 향상시켰다.
ConvNet Fusion

- 여러 모델을 앙상블(ensemble)하여 최종적으로 23.7/6.8/6.8의 점수를 얻을 수 있었다.
결론
- 최종적으로 VGGNet을 통해 깊은 신경망을 사용함으로써 classification accuracy 향상에 좋은 영향이 미치는 것을 확인하였다.
- 기존 AlexNet에서 사용하였던 LRN과 Network In Network 논문에서 사용하였던 1x1 conv가 VGG에서는 큰 의미가 없는 것을 알 수 있었다.
- Appendix를 통해 ImageNet dataset을 통해 사전학습된 VGG모델을 활용해 다른 dataset의 예측성능을 증가시킬 수 있음을 확인하였다.
