1. FCN의 한계점
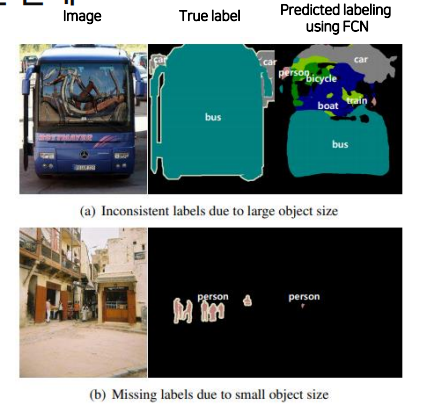
1. 객체의 크기가 크거나 작은경우 예측을 잘하지 못하는 문제
- 큰 object의 경우 지역적인(local) 정보만으로 예측
- 같은 Object여도 다르게 labeling
- 작은 object 무시
2. object의 디테일한 모습이 사라지는 문제
- Deconvolution 절차가 간단해 경계를 학습하기 어려움

2. Decoder를 개선한 모델
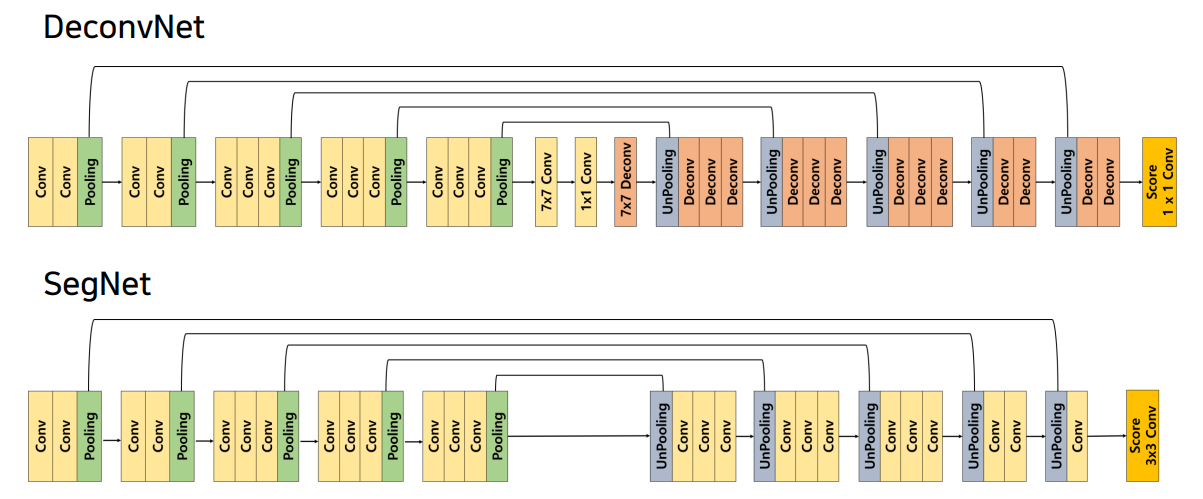
2.1 DeconvNet
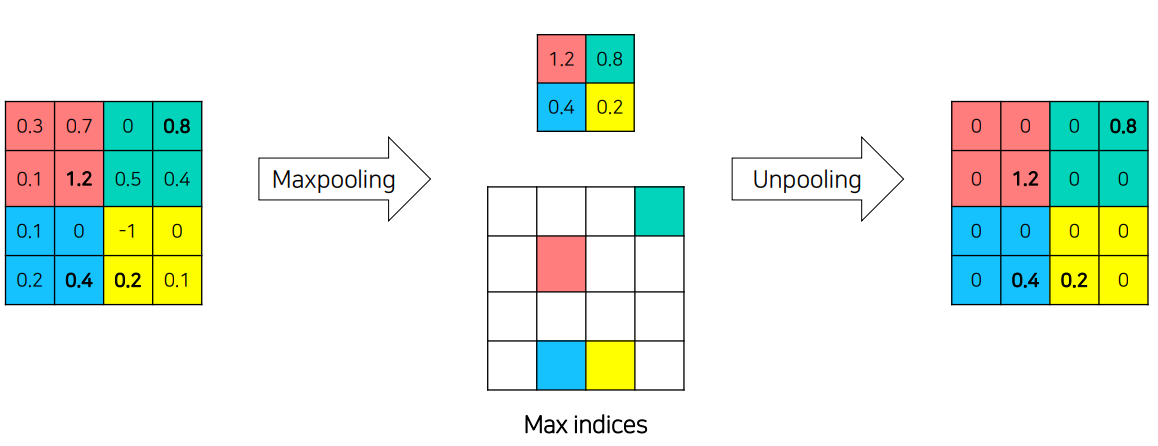
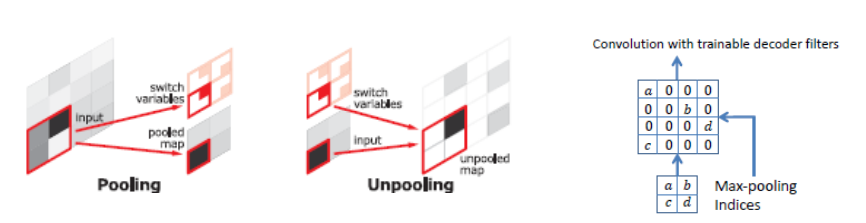
1x1 conv를 기준으로Decoder와Encoder를 대칭으로 구성VGG16을 사용Deconvolution Network는Unpooling,Deconvolution,ReLU로 이루어짐Unpooling은 디테일한 경계를 포착Transposed Convolution은 전반적인 모습을 포착1) Unpooling
Pooling시에 지워진 경계 정보를 기록했다가 복원- 학습이 필요없기 때문에 속도가 빠름
sparse한activation map을Transposed Convolution으로 보완
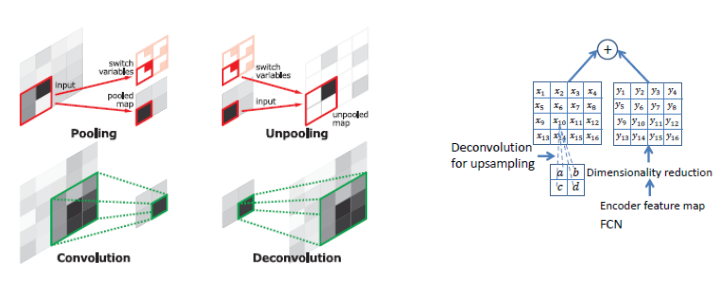
2) Deconvolution
Deconvolution layer를 통해서input object의 모양 복원- 얕은 층에서는 전반적인 모습
- 깊은 층에서는 구체적인 모습을 잡아냄
Unpooling에서는 자세한 구조(example-specifit)를 잡아내고Transposed Conv에서는class-specific한 구조를 잡아냄Unpooling을 통해 나온 기존의 위치 포인트에Transposed Conv가 빈부분을 채우는 형태- 기존의
FCN-8s보다 더 뚜렷한 형태를 잡아냈다고 함.
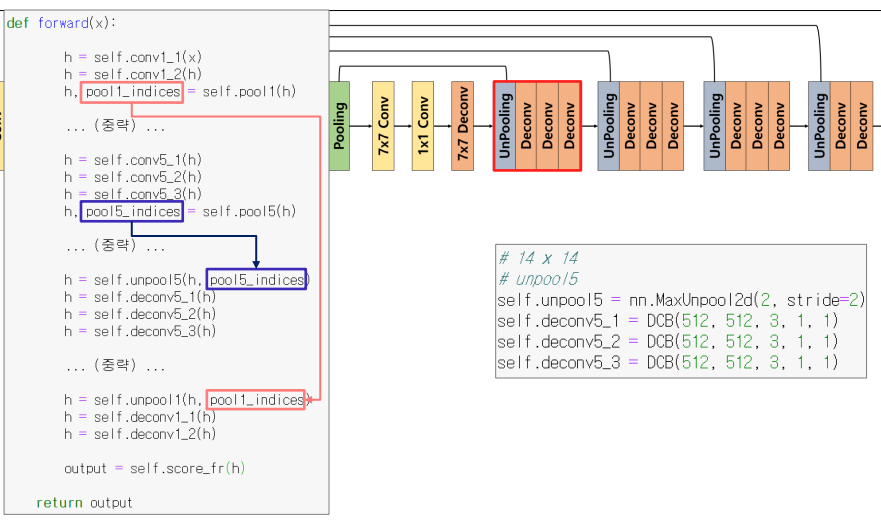
3) Network
pooling시return_indices=True로 주어 max값의 위치를 기억하도록함
- return받은 indice를 대응되는 위치의
unpooling에 이전output과 같이 넣어줌- Deconv 연산시
sparse한feature map을dense하게 하는 역할만하고 에 변화는 없음

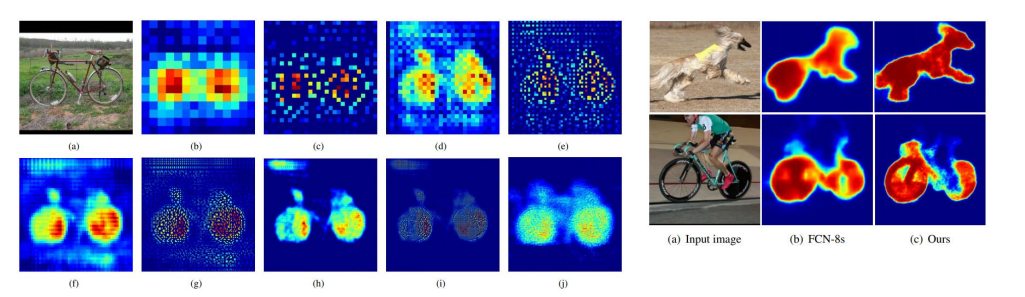

2.2 SegNet
- 성능보다는 속도 측면에서
real-time segmentation을 가능하게한 모델DeconvNet과 유사한 구조를 가지지만Decoder에서Transposed Conv대신Conv를 사용함DeconvNet중간의1x1 Conv를 제거하면서 속도 향상
3. Skip Connection 적용모델
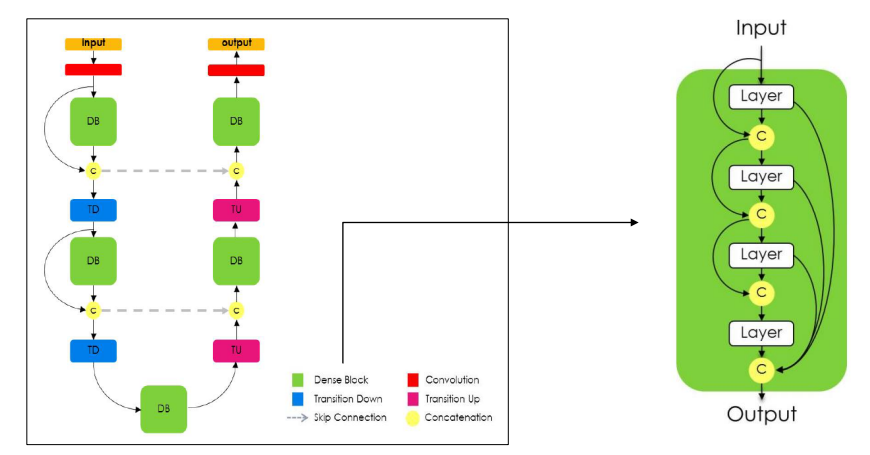
3.1 FC DenseNet
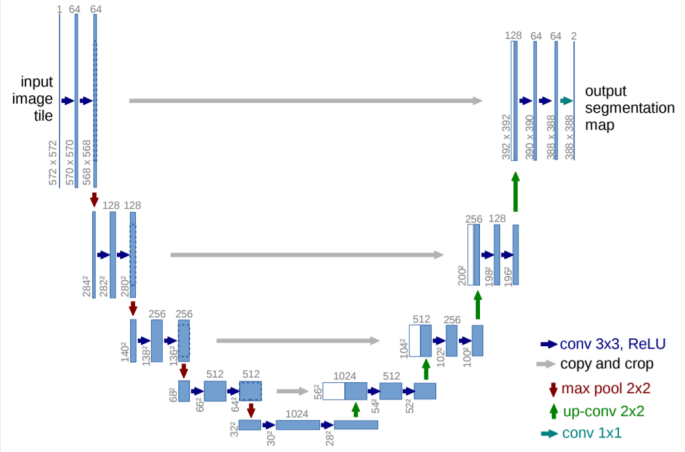
DenseNet과 유사한 구조3.2 Unet
4. Receptive Field를 확장시킨 모델
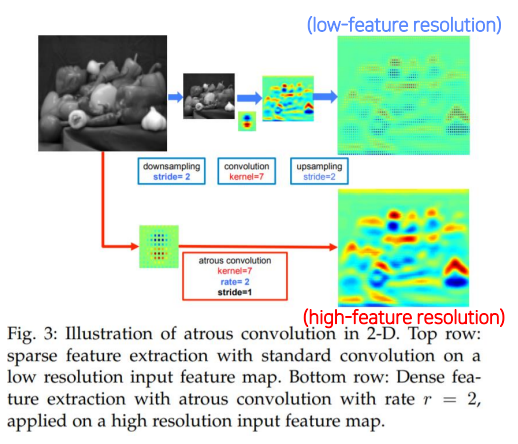
4.0 Dilated Conv
conv - conv를 적용한 것보다conv - pool - conv를 적용했을 때 효율적으로 더 넓은Receptive field를 가짐.- 하지만 너무 작은
resolution을 원본 크기로 다시 키웠을 때, 해상도가 낮아지는 문제가 발생함
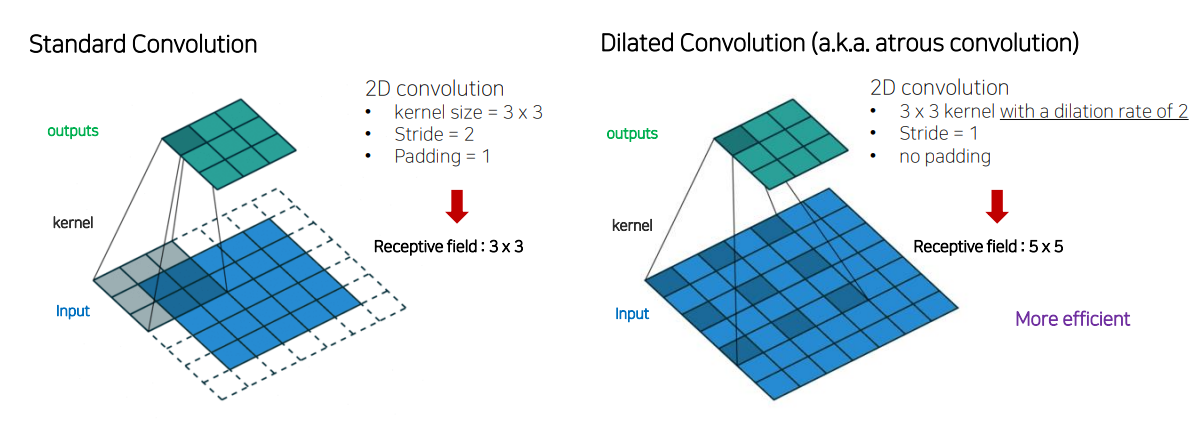
Receptive field는 넓히면서 이미지의 크기는 유지하는 방법? -->dilated conv(atrous conv)
- 파라미터의 수는 동일하면서
Receptive field의 크기는 넓히고high resolution을 유지함
Conv와 동일한 파라미터 수를 가지면서 더 넓은Receptive field를 바라보고 있음
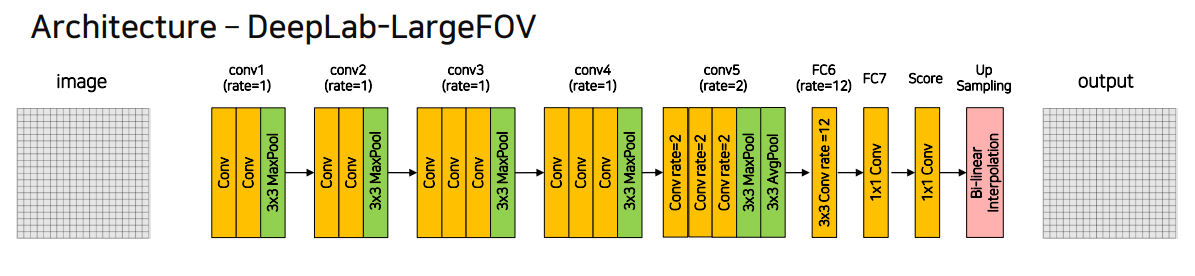
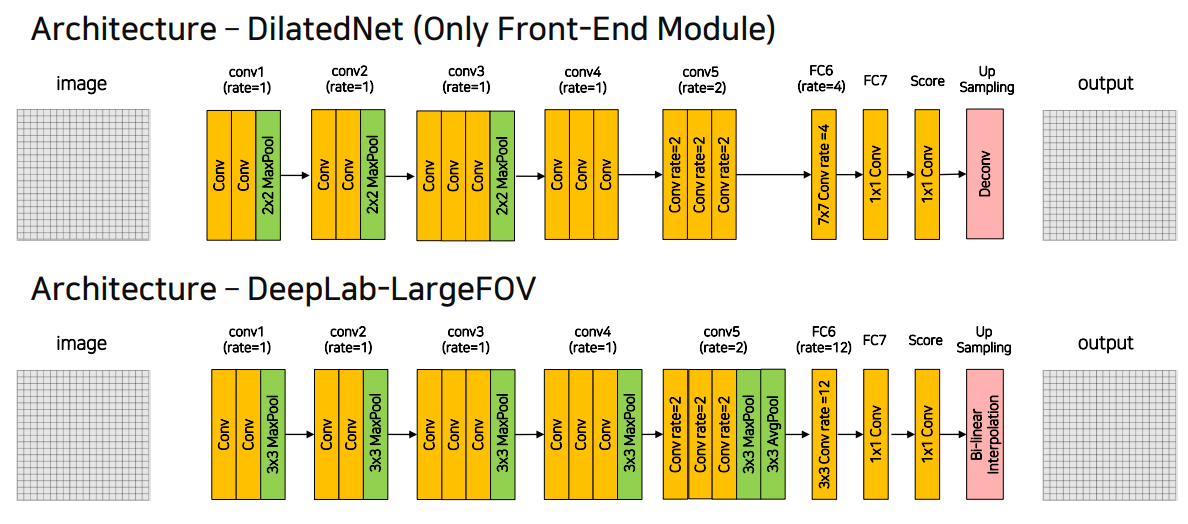
4.1 DeepLab v1
Pooling
2x2 pooling대신3x3 pooling(stride=2, padding=1)을 사용
--> 이미지의 크기가 로 줄어드는 것은 같지만 더 넓은Receptive field를 보게함4, 5번째 block에서는3x3 pooling(stride=1, padding=1)을 사용하여 똑같은 사이즈를 유지함Dilated Conv
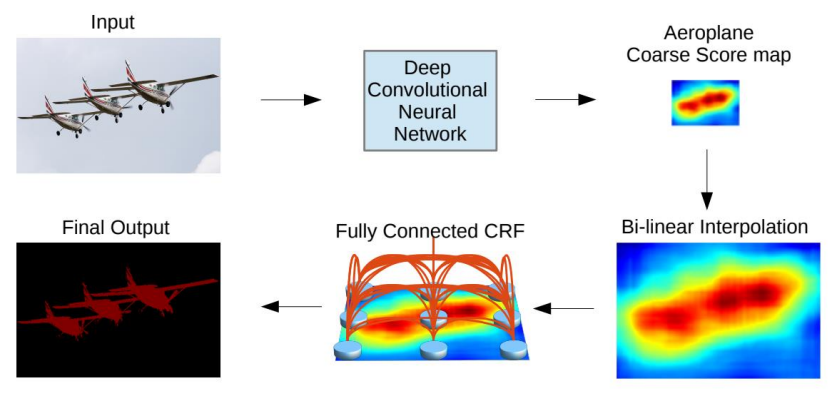
padding의 크기를dilaton의 크기와 동일하게 해줌으로써input과output의 크기가 동일하도록 함. (kernel size가 3이기 때문에 가능)5, 6번째 block에서dilated conv를 사용6번째 block에서는큰 dialation rate(12)를 사용함Up sampling
Bi-linear interpolation을 사용해 보간F.interploate(x, size, mode='bilinear')- 내분개념으로 채움
Dense CRF
Bilinear interpolation만으로는 부족한 정교한segmentation을 위해 적용- 색상이 유사한 픽셀이 가까이 위치하면 같은 범주로 구분하는 원리


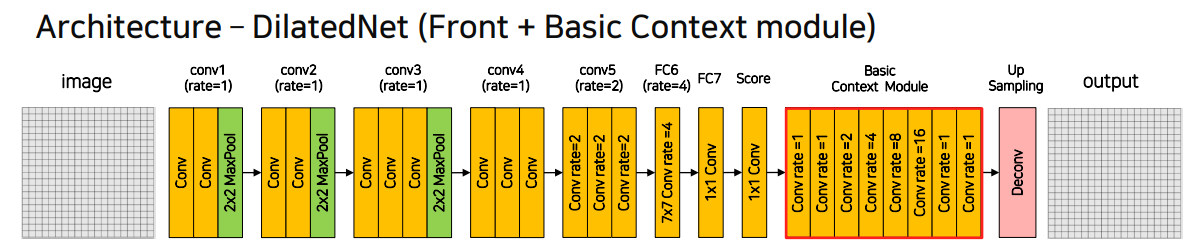
4.2 DilatedNet
DeepLab과 유사한 구조를 가지지만 조금 더 효율적
Basic context module을 추가하여 다양한dilation rate를 줌으로써 다양한 크기의 object를 검출할 수 있도록 함


인공지능 꿈나무