[천재교육] python 로지스틱 회귀
📕 들어가며
오늘은 간단한 프로젝트를 통해
분류 알고리즘 중 하나인
로지스틱 회귀의 알고리즘의 개념과
관련 라이브러리 사용법에 대하여
정리해보겠습니다.
📕 실습준비
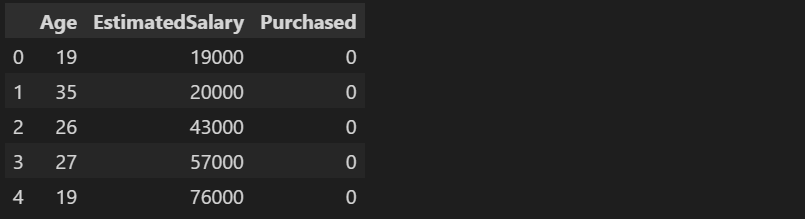
1. 데이터 준비
Social_Network_Ads 데이터 다운로드 받아 주세요 ^^
<컬럼 설명>
1.Age: 나이
2.EstimatedSalary: 추정 연봉
3.Purchased: 상품 구매 여부
우리의 목표는 Age와 EstimatedSalary 를 가지고
이 사람이 상품을 살지 안살지 분류해 내는 모델을 만드는 것입니다.
2. 데이터 분석
# 데이터 읽어오기
import pandas as pd
# 데이터 "Social_Network_Ads.csv" 로드
df = pd.read_csv("./data/Social_Network_Ads.csv")
df.head()<실행결과>:
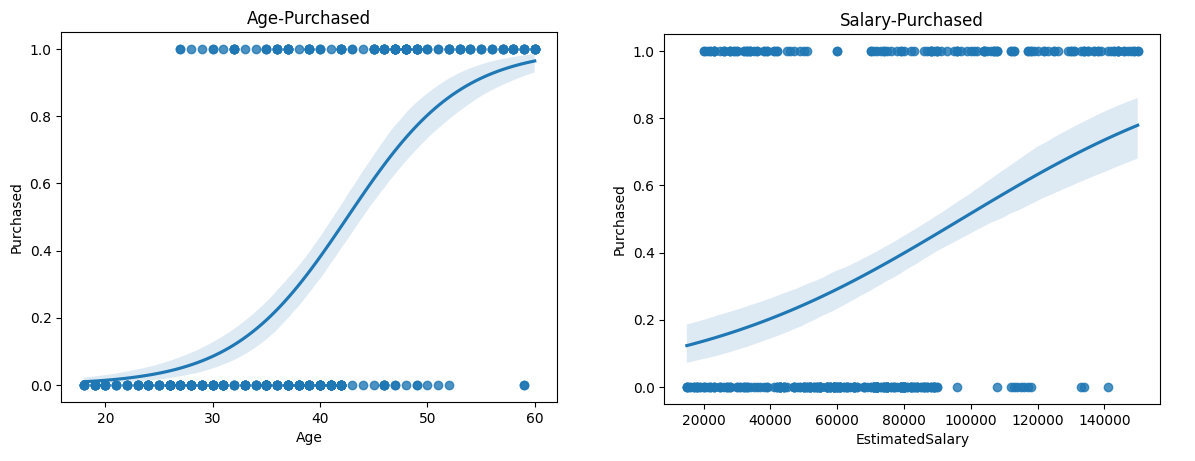
# sns.regplot 그리기
# regplot: scatterplot와 lineplot을 합쳐놓은 그래프
import seaborn as sns
import matplotlib.pyplot as plt
# Age, Purchased
sns.regplot(x = df['Age'], y = df['Purchased'], logistic=True)
plt.title("Age-Purchased")
plt.show()
# EstimatedSalary, Purchased
sns.regplot(x = df['EstimatedSalary'], y = df['Purchased'], logistic=True)
plt.title("Salary-Purchased")
plt.show()<실행결과> :
3. 로지스틱 회귀가 뭔데?!
로지스틱 회귀란
독립 변수의 선형 결합을 이용하여
사건의 발생 가능성을 예측하는 데 사용되는 통계 기법이다.
라고 위키백과에 적혀 있군요
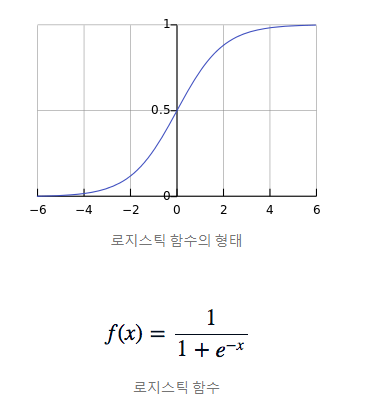
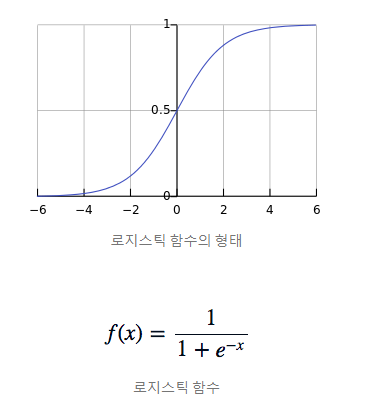
선형회귀처럼 선형함수를 사용하지만
마지막에 로지스틱 함수를 사용해
연속적인 실수 출력값을 1 또는 0으로 변환합니다.참고)
📕 로지스틱 회귀 모델 사용해보기
✏️ 1. 학습 데이터 가져오기
# 데이터 읽어오기
import pandas as pd
# 데이터 "Social_Network_Ads.csv" 로드
df = pd.read_csv("./data/Social_Network_Ads.csv")
df.head()<실행결과> :
✏️ 2. 데이터 분리
# sklearn 을 활용한 선형회귀 모델링을 위해
# 데이터를 train set 과 test set으로 분리한다.
# train set: 머신러닝 모델 학습에 사용되는 데이터
# test set: 머신러닝 모델 평가에 사용되는 데이터
from sklearn.model_selection import train_test_split
X = df.iloc[:, [0,1]].values # Age, EstimatedSalary
y = df.iloc[:, 2].values # Purchased
# 25% 테스트로 사용
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0)
print(len(X_train)) # 300개
print(len(X_test)) # 100개 ✏️ 3. 모델 훈련
# 모델 훈련하기
from sklearn.linear_model import LogisticRegression
classifer = LogisticRegression(random_state=0)
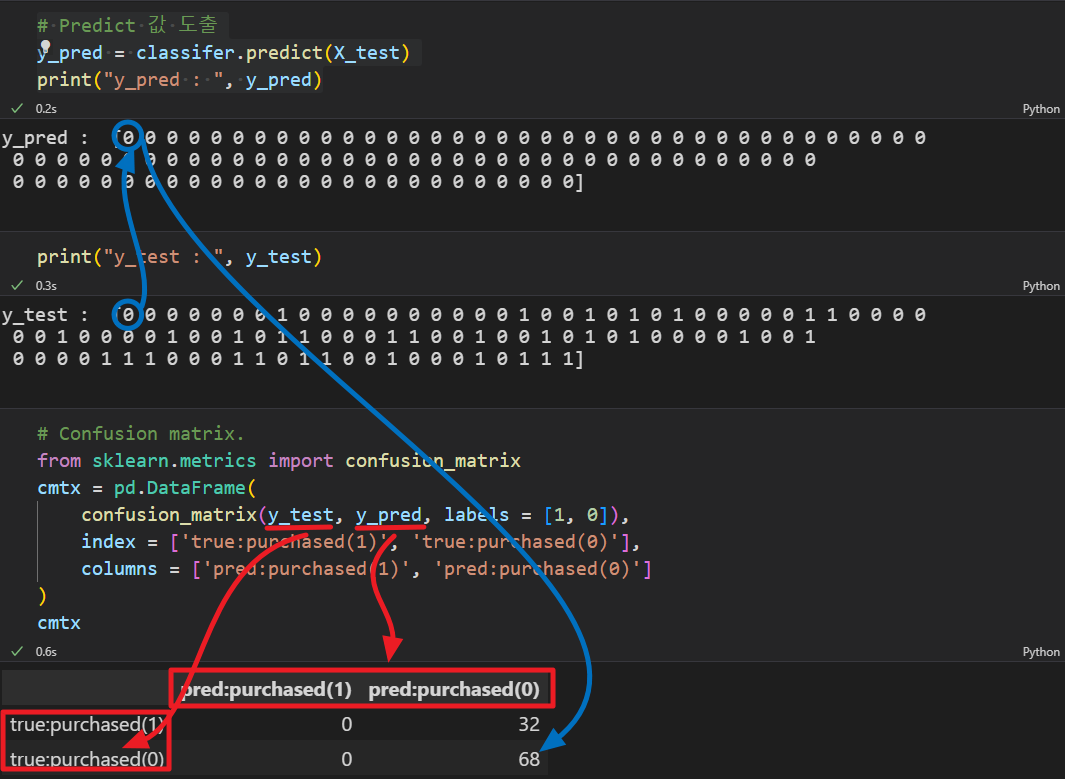
classifer.fit(X_train, y_train) # train 데이터로 모델 학습# Predict 값 도출
y_pred = classifer.predict(X_test)
print("y_pred : ", y_pred)<실행결과> :
모두 0으로 예측해 버리네요. ㅜ.ㅜ

# 실제 정답
print("y_test : ", y_test)<실행결과> :

✏️4. 훈련된 모델 평가하기
1) Confusion matrix 활용
# 모델 평가하기1-1
# Confusion matrix 그리기
# Confusion matrix.
from sklearn.metrics import confusion_matrix
cmtx = pd.DataFrame(
confusion_matrix(y_test, y_pred, labels = [1, 0]),
index = ['true:purchased(1)', 'true:purchased(0)'],
columns = ['pred:purchased(1)', 'pred:purchased(0)']
)
cmtx<실행결과> :
참고 : 출처
# 모델 평가하기1-2
# Confusion matrix 활용하여
# acuuracy, precision, recall, fscore 값 구하기
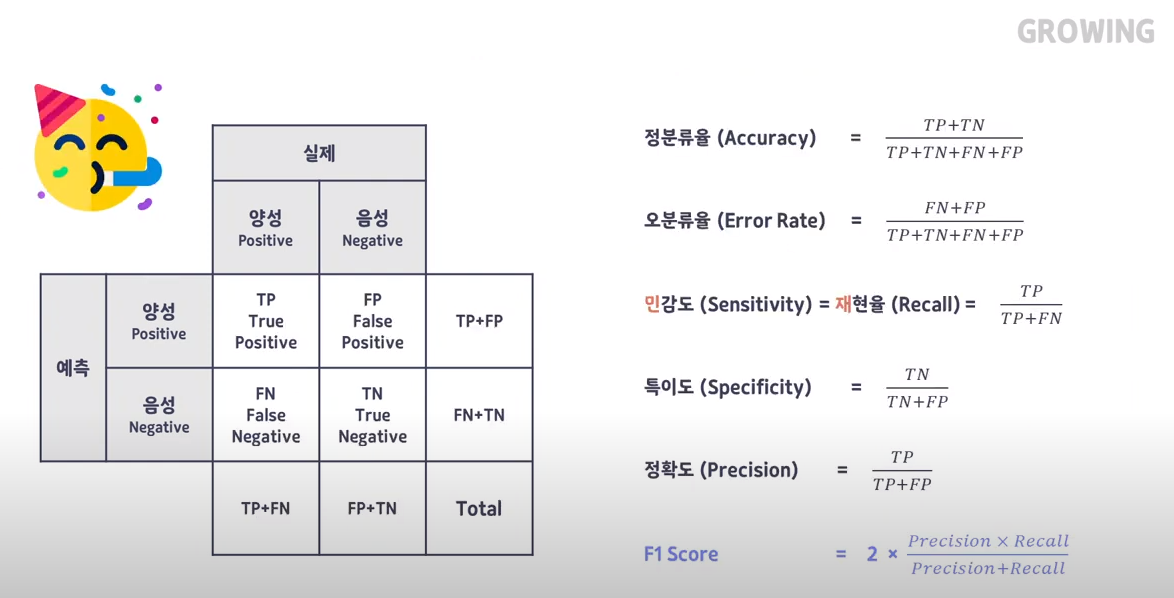
# Accuracy : 정확도
# (TP+TN) / (TP + FP + TN + FN)
accuracy = (cmtx.iloc[0,0]+cmtx.iloc[1,1])/(cmtx.iloc[0,0]+cmtx.iloc[0,1]+cmtx.iloc[1,0]+cmtx.iloc[1,1])
print("acuuracy : ", accuracy)
# Precision : 정밀도
# TP / (TP + FP)
precision = cmtx.iloc[0,0]/(cmtx.iloc[0,0]+cmtx.iloc[1,0])
print("precision : ", precision)
# Recall (Sensitivity) : 재현율
# TP / (TP + FN)
recall = cmtx.iloc[0,0]/(cmtx.iloc[0,0]+cmtx.iloc[0,1])
print("recall : ", recall)
# F1 Score : F1 score
# 2 * (Prescion*Recall)/(Presicion+Recall)
f1 = 2*(precision*recall)/(precision+recall)
print("f1 score : ", f1)<실행결과> :

2) skleran 라이브러리 활용
# 모델 평가하기2 (다양한 라이브러리 활용하기)
# accuracy 구하기
from sklearn.metrics import accuracy_score
print("accuracy : ", accuracy_score(y_test, y_pred))
# precision, recall, fscore
from sklearn.metrics import precision_recall_fscore_support
print("(precision, recall, fscore, support) = ", precision_recall_fscore_support(y_test, y_pred, average='binary'))<실행결과> :

✏️5. Coefficients
# 최종 모델의 (계수, Coefficients) 를 확인하고 싶으면 아래와 같이 .coef_ 의 값을 확인한다.
# age, salary -> 구매력 예측
# 계수 : 높으면 높을수록 영향을 많이 주는 변수
classifer.coef_ # [age_coeff, salary_coeff]<실행결과> :
age와 salary 모두 구매여부와 음의 상관관계를 가지고 있군요..^^

✏️6. Logit model 만들기
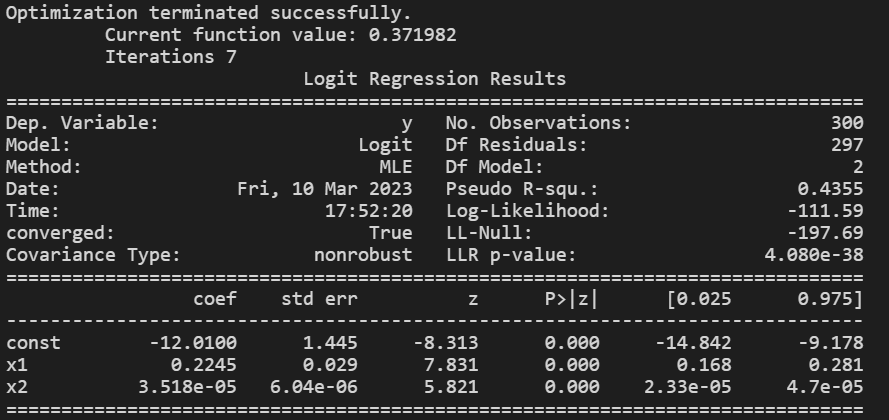
# 조금 더 깊은 통계 분석을 위해 statsmodels 을 사용하여 Logit model을 다시 만들어 본다.
# 바로 위에서 모델에 사용한 데이터를 유지해서 사용한다: X_train, X_test, y_train, y_test
import statsmodels.api as sm
train_endog = y_train
train_exog = sm.add_constant(X_train)
logit_mod = sm.Logit(train_endog,train_exog)
logit_res = logit_mod.fit()
print(logit_res.summary())<실행결과> :
Logit model.. 해석하는 방법에 대해서는 나중에 알게되면 정리하겠습니다. ㅜ.ㅜ
📕 전체 코드
import pandas as pd
# 데이터 "Social_Network_Ads.csv" 로드
df = pd.read_csv("./data/Social_Network_Ads.csv")
print(df.head())
# sns.regplot 그리기
# regplot: scatterplot와 lineplot을 합쳐놓은 그래프
import seaborn as sns # Age,EstimatedSalary,Purchased
import matplotlib.pyplot as plt
sns.regplot(x = df['Age'], y = df['Purchased'], logistic=True)
plt.title("Age-Purchased")
plt.show()
sns.regplot(x = df['EstimatedSalary'], y = df['Purchased'], logistic=True)
plt.title("Salary-Purchased")
plt.show()
# 데이터 분리하기
from sklearn.model_selection import train_test_split
X = df.iloc[:, [0,1]].values
y = df.iloc[:, 2].values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0)
# 모델 훈련하기
from sklearn.linear_model import LogisticRegression
classifer = LogisticRegression(random_state=0)
classifer.fit(X_train, y_train)
# Predict 값 도출
y_pred = classifer.predict(X_test)
print()
print("y_pred : ", y_pred)
print("y_test : ", y_test)
print()
# 모델 평가하기1
# Confusion matrix.
from sklearn.metrics import confusion_matrix
cmtx = pd.DataFrame(
confusion_matrix(y_test, y_pred, labels = [1, 0]),
index = ['true:purchased(1)', 'true:purchased(0)'],
columns = ['pred:purchased(1)', 'pred:purchased(0)']
)
print("cmtx : ", cmtx)
print()
# Confusion matrix 활용하여
# acuuracy, precision, recall, fscore 값 구하기
# Accuracy : 정확도
# TP / (TP + FP + TN + FN)
accuracy = (cmtx.iloc[0,0]+cmtx.iloc[1,1])/(cmtx.iloc[0,0]+cmtx.iloc[0,1]+cmtx.iloc[1,0]+cmtx.iloc[1,1])
print("acuuracy : ", accuracy)
# Precision : 정밀도
# TP / (TP + FP)
precision = cmtx.iloc[0,0]/(cmtx.iloc[0,0]+cmtx.iloc[1,0])
print("precision : ", precision)
# Recall (Sensitivity) : 재현율
# TP / (TP + FN)
recall = cmtx.iloc[0,0]/(cmtx.iloc[0,0]+cmtx.iloc[0,1])
print("recall : ", recall)
# F1 Score : F1 score
# 2 * (Prescion*Recall)/(Presicion+Recall)
f1 = 2*(precision*recall)/(precision+recall)
print("f1 score : ", f1)
print()
# 모델 평가하기2 (다양한 라이브러리 활용하기)
# accuracy 구하기
from sklearn.metrics import accuracy_score
print("accuracy : ", accuracy_score(y_test, y_pred))
# precision, recall, fscore
from sklearn.metrics import precision_recall_fscore_support
print("(precision, recall, fscore, support) = ", precision_recall_fscore_support(y_test, y_pred, average='binary'))
print()
# 최종 모델의 (계수, Coefficients) 를 확인하고 싶으면 아래와 같이 .coef_ 의 값을 확인한다.
# age, salary -> 구매력 예측
# 계수 : 높으면 높을수록 영향을 많이 주는 변수
print("Coefficients(age,salary) : ", classifer.coef_)
# [age_coeff, salary_coeff]
# age가 더 영향을 많이 줌
# 조금 더 깊은 통계 분석을 위해 statsmodels 을 사용하여 Logit model을 다시 만들어 본다.
# 바로 위에서 모델에 사용한 데이터를 유지해서 사용한다: X_train, X_test, Y_train, Y_test
import statsmodels.api as sm
train_endog = y_train
train_exog = sm.add_constant(X_train)
logit_mod = sm.Logit(train_endog,train_exog)
logit_res = logit_mod.fit()
print(logit_res.summary())
1.01^365
꼼꼼하고 섬세한 포스팅 잘 봤습니다~! 2월의 마지막까지 화이팅입니다!! 곧 다가오는 3월도 화이팅!!! ^.^