[천재교육] 로지스틱 회귀 모델 성능향상 기법
📕 들어가며
지난 시간에는
로지스틱 회귀 알고리즘으로 분류모델을 만들고
아래 지표들을 사용해서
분류모델의 성능을 측정해 보았습니다.
1. accuracy(정분류율)
2. precision(정확도)
3. recall(민감도)
4. F1 Score
오늘은 여러 가지 기법들을 적용해서
머신러닝 분류모델의 성능 (특히 accuracy)을 향상
시켜보도록 하겠습니다.
📕 지난 시간 결과
1. 데이터 준비
Social_Network_Ads 데이터 다운로드 받아 주세요 ^^
<컬럼 설명>
1.Age: 나이
2.EstimatedSalary: 추정 연봉
3.Purchased: 상품 구매 여부

2. 로지스틱 회귀 알고리즘 사용 및 모델의 정확도 분석
import pandas as pd
# 데이터 "Social_Network_Ads.csv" 로드
df = pd.read_csv("./data/Social_Network_Ads.csv")
# 데이터 분리하기
from sklearn.model_selection import train_test_split
X = df.iloc[:, [0,1]].values
y = df.iloc[:, 2].values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0)
# 모델 훈련하기
from sklearn.linear_model import LogisticRegression
classifer = LogisticRegression(random_state=0)
classifer.fit(X_train, y_train)
# Predict 값 도출
y_pred = classifer.predict(X_test)
# 모델 평가하기1
# Confusion matrix.
from sklearn.metrics import confusion_matrix
cmtx = pd.DataFrame(
confusion_matrix(y_test, y_pred, labels = [1, 0]),
index = ['true:purchased(1)', 'true:purchased(0)'],
columns = ['pred:purchased(1)', 'pred:purchased(0)']
)
print("cmtx : ", cmtx)
print()
# 모델 평가하기2 (다양한 라이브러리 활용하기)
# accuracy 구하기
from sklearn.metrics import accuracy_score
print("accuracy : ", accuracy_score(y_test, y_pred))
# precision, recall, fscore 구하기
from sklearn.metrics import precision_recall_fscore_support
print("(precision, recall, fscore, support) = ", precision_recall_fscore_support(y_test, y_pred, average='binary'))<실행결과>:

3. 결과 분석
accuracy가 68%나 되기는 하지만
precision, recall, fscore 값이 심상치 않죠?!
이번 시간에는 이를 개선해 보도록 하겠습니다.
📕 분류 모델 성능 개선
✏️ 방법 1. 데이터 정규화 (feature scaling)
모델 훈련 전에 다음 작업을 해주면 됩니다.
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
# 데이터에 정규화 적용
# 평균이 0이고 표준편차가 1인 분포를 따르도록 함
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)<실행 결과> :
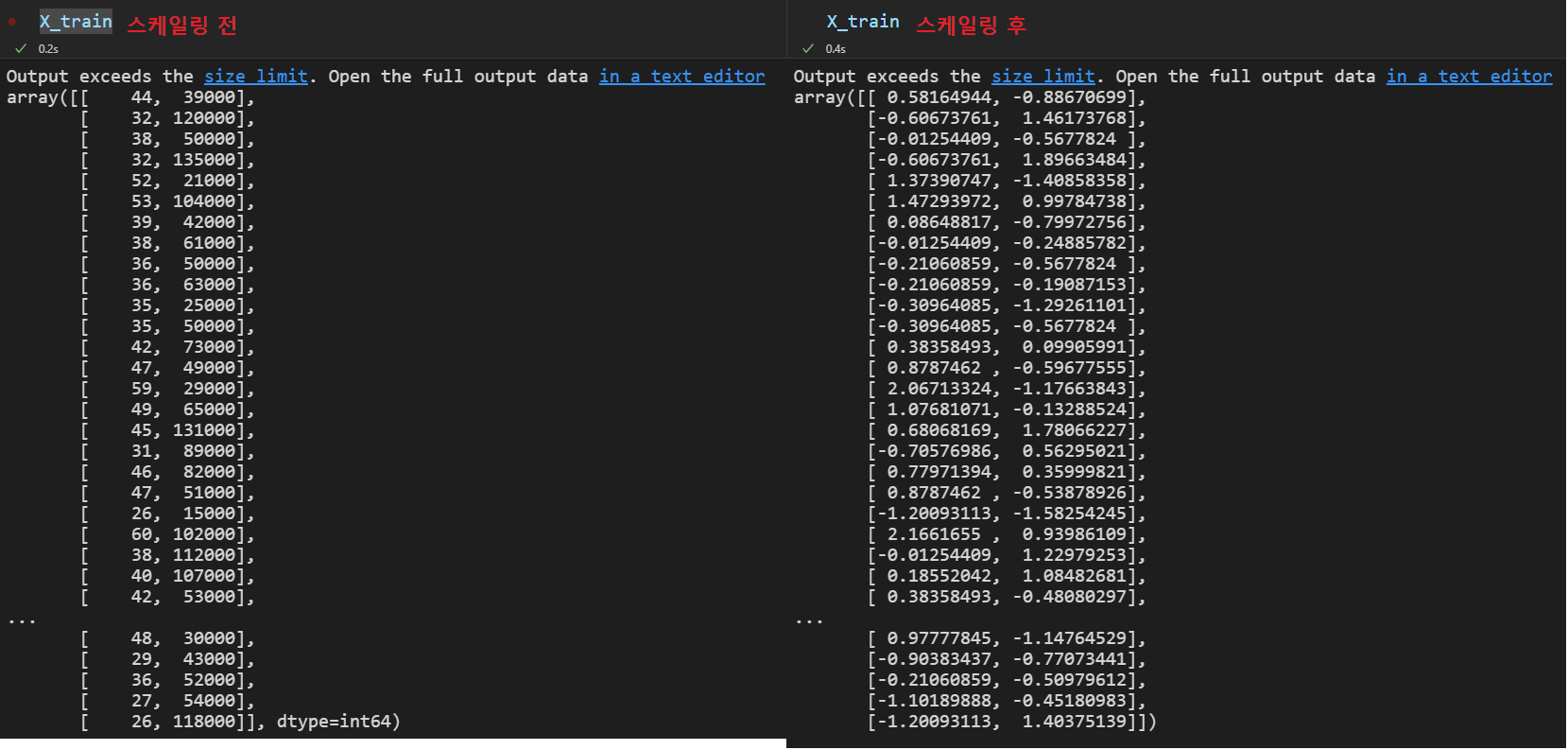
데이터 정규화 이후 모델 훈련 및 평가작업 진행
# <데이터 정규화>
import pandas as pd
# 데이터 "Social_Network_Ads.csv" 로드
df = pd.read_csv("./data/Social_Network_Ads.csv")
# 데이터 분리하기
from sklearn.model_selection import train_test_split
X = df.iloc[:, [0,1]].values
y = df.iloc[:, 2].values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0)
# --------------------------------여기 추가-------------------------------------------------
# 데이터 정규화 작업
from sklearn.preprocessing import StandardScaler
# X_train, X_test
sc = StandardScaler()
# 데이터에 정규화 적용
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
# --------------------------------여기 까지-------------------------------------------------
# 모델 훈련하기
from sklearn.linear_model import LogisticRegression
classifer = LogisticRegression(random_state=0)
classifer.fit(X_train, y_train)
# Predict 값 도출
y_pred = classifer.predict(X_test)
# 모델 평가하기1
# Confusion matrix.
from sklearn.metrics import confusion_matrix
cmtx = pd.DataFrame(
confusion_matrix(y_test, y_pred, labels = [1, 0]),
index = ['true:purchased(1)', 'true:purchased(0)'],
columns = ['pred:purchased(1)', 'pred:purchased(0)']
)
print("cmtx : ", cmtx)
print()
# 모델 평가하기2 (다양한 라이브러리 활용하기)
# accuracy 구하기
from sklearn.metrics import accuracy_score
print("accuracy : ", accuracy_score(y_test, y_pred))
# precision, recall, fscore 구하기
from sklearn.metrics import precision_recall_fscore_support
print("(precision, recall, fscore, support) = ", precision_recall_fscore_support(y_test, y_pred, average='binary'))<실행 결과> :

정규화만 했을 뿐인데 accuracy가 89% 까지 올라갔습니다.
궁금해서 정규화를 하는 이유를 살펴보니
<데이터 정규화를 하는 이유>
1. 각 특성들의 단위를 무시하고 값으로 단순 비교하기 위함.
2. scale이 너무 크면 노이즈 데이터가 생성되거나 overfitting이 될 가능성이 높기 때문.
라고 잘 정리해주셨더라고요
[ML]정규화(normalization)와 표준화(standardization)는 왜 하는걸까?
✏️ 방법 2. cutoff 라인 변경
1) cutoff가 뭔데?!..
# predict_proba: X_test의 각 값을 0으로 예측할 확률과 1로 예측할 확률을 보여줌
prob = classifer.predict_proba(X_test) # [ [0이 나올 확률, 1이 나올확률],... ]
print(prob)<실행 결과> :
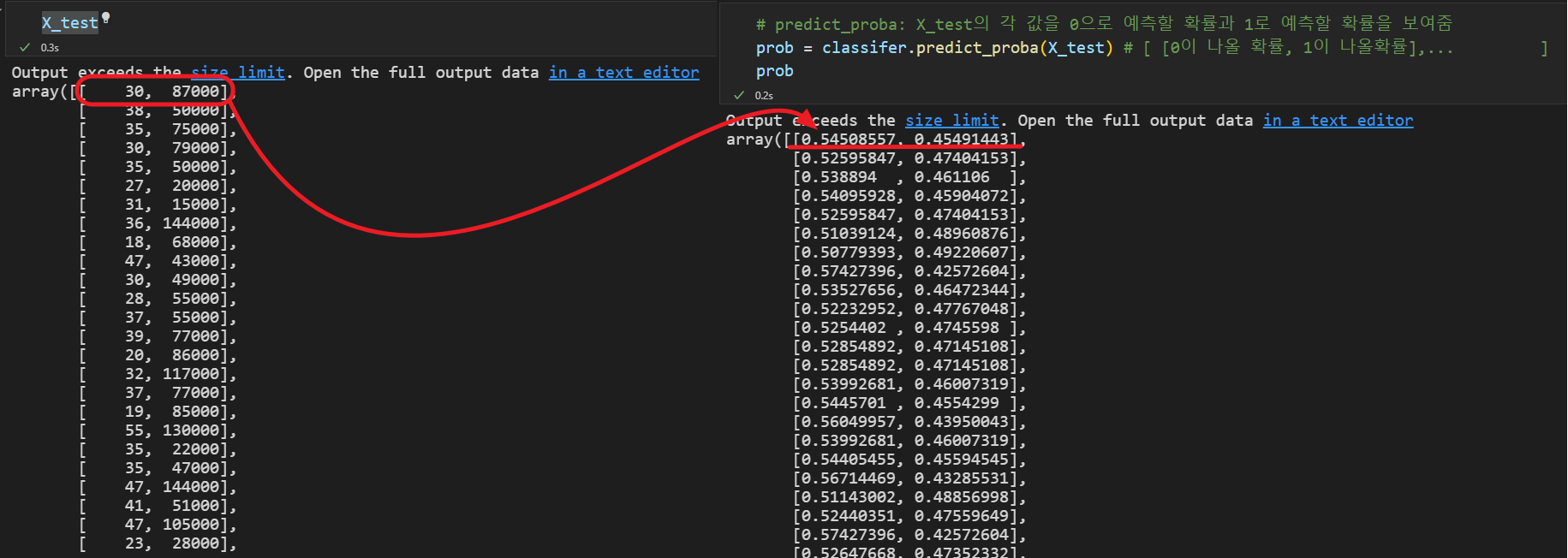
여기서 [ 30, 87000 ]이라는 데이터를
0으로 판단할 확률이 0.54508557이고
1로 판단할 확률이 0.45491443 이다.
그런데 로지스틱 회귀 모델에서 기본 cutoff(1로 판단할 확률)는
기본값으로 0.5로 지정되어 있습니다.즉, 어떤 값을 1로 판단할 기준인 cutoff 0.5를 넘기면 1로 판단
반대로 어떤 값을 1로 판단할 기준인 cutoff 0.5를 넘기지 못하면 0으로 판단함.
따라서 이 값은 1로 판단할 확률이 0.45491443이기 때문에 0으로 판단하게 된다.
2) cutoff 라인 변경해보기
cutoff를 최적의 결과가 나올 때까지
한땀한땀 계속 바꿔보았습니다. ㅜ.ㅜ
# predict_proba: X_test의 각 값을 0으로 예측할 확률과 1로 예측할 확률을 보여줌
# 그 중 각 값을 1로 예측할 확률들만 가져옴
prob1 = classifer.predict_proba(X_test)[:,1] # [ 0.45491443, 0.47404153, ... ]
# cutoff 0.48로 수정
cutoff = 0.48
# Y_pred_new_cutof: 새로운 cutoff를 적용한 예측치
y_pred_new_cutoff = [1 if i > cutoff else 0 for i in prob1]
y_pred_new_cutoff
# 모델 평가하기
# Confusion matrix.
from sklearn.metrics import confusion_matrix
cmtx = pd.DataFrame(
confusion_matrix(y_test, y_pred_new_cutoff, labels = [1, 0]),
index = ['true:purchased(1)', 'true:purchased(0)'],
columns = ['pred:purchased(1)', 'pred:purchased(0)']
)
print("cmtx : ", cmtx)
print()
print("acuuracy:", accuracy_score(y_test, y_pred_new_cutoff))
print("precision_recall_fscore_support:", precision_recall_fscore_support(y_test, y_pred_new_cutoff, average="binary"))<실행 결과> :
전부다 0으로 예측하는 사태는 피하였지만
오히려.. accuracy가 떨어졌군요..ㅜ

※ 방법2 전체 코드
# <cutoff 조정>
import pandas as pd
# 데이터 "Social_Network_Ads.csv" 로드
df = pd.read_csv("./data/Social_Network_Ads.csv")
# 데이터 분리하기
from sklearn.model_selection import train_test_split
X = df.iloc[:, [0,1]].values
y = df.iloc[:, 2].values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0)
# 모델 훈련하기
from sklearn.linear_model import LogisticRegression
classifer = LogisticRegression(random_state=0)
classifer.fit(X_train, y_train)
# predict_proba: X_test의 각 값을 0으로 예측할 확률과 1로 예측할 확률을 보여줌
# 그 중 각 값을 1로 예측할 확률들만 가져옴
prob1 = classifer.predict_proba(X_test)[:,1] # [ 0.45491443, 0.47404153, ... ]
# cutoff 0.48로 수정
cutoff = 0.48
# Y_pred_new_cutof: 새로운 cutoff를 적용한 예측치
y_pred_new_cutoff = [1 if i > cutoff else 0 for i in prob1]
y_pred_new_cutoff
# 모델 평가하기1
# Confusion matrix.
from sklearn.metrics import confusion_matrix
cmtx = pd.DataFrame(
confusion_matrix(y_test, y_pred_new_cutoff, labels = [1, 0]),
index = ['true:purchased(1)', 'true:purchased(0)'],
columns = ['pred:purchased(1)', 'pred:purchased(0)']
)
print("cmtx : ", cmtx)
print()
# 모델 평가하기2 (다양한 라이브러리 활용하기)
# accuracy 구하기
from sklearn.metrics import accuracy_score
print("accuracy : ", accuracy_score(y_test, y_pred_new_cutoff))
# precision, recall, fscore 구하기
from sklearn.metrics import precision_recall_fscore_support
print("(precision, recall, fscore, support) = ", precision_recall_fscore_support(y_test, y_pred_new_cutoff, average='binary'))✏️ 방법 3. 정규화 + cutoff 라인 변경
전체 코드
# <정규화와 cutoff 조정 둘 다 같이 적용>
import pandas as pd
# 데이터 "Social_Network_Ads.csv" 로드
df = pd.read_csv("./data/Social_Network_Ads.csv")
# 데이터 분리하기
from sklearn.model_selection import train_test_split
X = df.iloc[:, [0,1]].values
y = df.iloc[:, 2].values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0)
# 데이터 정규화 작업
from sklearn.preprocessing import StandardScaler
# X_train, X_test
sc = StandardScaler()
# 데이터에 정규화 적용
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
# 모델 훈련하기
from sklearn.linear_model import LogisticRegression
classifer = LogisticRegression(random_state=0)
classifer.fit(X_train, y_train)
# predict_proba: X_test의 각 값을 0으로 예측할 확률과 1로 예측할 확률을 보여줌
# 그 중 각 값을 1로 예측할 확률들만 가져옴
prob1 = classifer.predict_proba(X_test)[:,1] # [ 0.45491443, 0.47404153, ... ]
# cutoff 0.48로 수정
cutoff = 0.48
# Y_pred_new_cutof: 새로운 cutoff를 적용한 예측치
y_pred_new_cutoff = [1 if i > cutoff else 0 for i in prob1]
y_pred_new_cutoff
# 모델 평가하기1
# Confusion matrix.
from sklearn.metrics import confusion_matrix
cmtx = pd.DataFrame(
confusion_matrix(y_test, y_pred_new_cutoff, labels = [1, 0]),
index = ['true:purchased(1)', 'true:purchased(0)'],
columns = ['pred:purchased(1)', 'pred:purchased(0)']
)
print("cmtx : ", cmtx)
print()
# 모델 평가하기2 (다양한 라이브러리 활용하기)
# accuracy 구하기
from sklearn.metrics import accuracy_score
print("accuracy : ", accuracy_score(y_test, y_pred_new_cutoff))
# precision, recall, fscore 구하기
from sklearn.metrics import precision_recall_fscore_support
print("(precision, recall, fscore, support) = ", precision_recall_fscore_support(y_test, y_pred_new_cutoff, average='binary'))<실행 결과> :
뭐지?!..ㅋㅋ 역시 섞어 쓰니 성능이 좋군요 ^^

다음시간에는 cutoff를 주먹구구식으로 바꾸지 않고
효율적으로 바꿔보는 방법(cutoff 최적화)에 대해 배워 보겠습니다. ^^

이번주 챌린지도 넘넘 수고 많으셨어용!! 꾸준함이 특별함을 만든다는 말처럼 남은 챌린지도 화이팅입니다!! 일목요연하게 정리된 포스팅을 보니 저도 개발공부하고 싶어지는데요(?) JS님 화이팅!!! (@^0^@)/