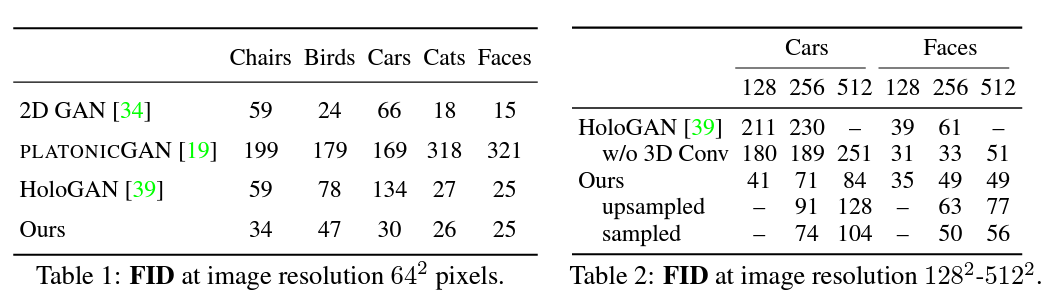
summary
3D-aware image synthesis task를 수행하기 위해서 PatchGan과 NeRF를 결합하여 3d gan을 제안한다.
3D-aware image synthesis: 3차원 공간에서 객체 정보를 고려하여 새로운 이미지를 합성
- 일반적인 2D 이미지 합성은 주어진 이미지에서 원하는 객체 또는 배경을 선택하거나 조합하여 새로운 이미지를 생성하지만, 3D-aware이미지 합성은 3d 객체의 형상 ,텍스쳐, 조명, 카메라 위치 등의 3차원 정보를 활용하여 합성을 수행. (3D modeling의 범위 안에 3d-aware-image synthesis가 포함된다.)
 이미지 출처
이미지 출처
key point
- NeRF를 활용하여 3D 객체 generation을 진행.
- NeRF를 사용하여 color 와 volume density 를 생성
- Generator는 , 를 사용하여 3d -aware image를 합성
- PatchGan 개념을 사용하여 Descriminator를 진행하였음
Problem
기존 Gan(Generative Adversarial Networks)은 2d domain에서 high-resolution image generation이 가능하지만, 3d World에서는 어려움이 있었다. 즉, 기존의 GAN만을 사용해서는 3d 를 표현하는데 필요한 shape, view point등을 고려할 수 없었다. 이에 논문에서는
이에 unposed 2d image를 학습했슴에도 불구하고 3d-aware image synthesis를 진행하기 위한 pipeline을 설계했다.
- unposed image : 이미지가 posed되어있지 않은 상태를 의미하며, 카메라의 위치나 방향에 제약없이 찰영된 이미지를 말한다.
Architecture 흐름
- Generator 가 camera matrix , , 2d sampling pattern 와 그리고 , 를 input으로 받아서 image patch 를 생성한다.
- discriminator 는 Generator output patch 와 real image extracted patch 를 비교
notation 정리
-> : generator
: output of ,predicts an image patch
: shape variable standard Normal distribution sampling
: appearance variable standard Normal distribution sampling
: camera pose () uniform distribution
center of patch , where : width , : height
: camera matrix (local length, principal point, skew)
: sampling pattern
: sacling factor where
(ray sampling) where k : principle point num
--
: discriminator , predicte 와 를 비교
: pixe sampling function : bilinear sampling operation
where : real data distribution
: sampling pattern
model architecture
GRAF의 전체적인 흐름은 다음 그림으로 설명가능하다
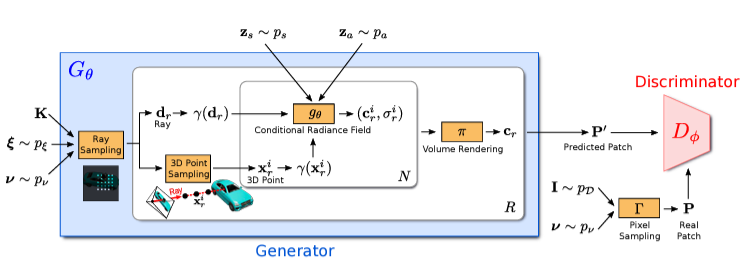
ray sampling
ray sampling은 다음 수식을 따라서 진행한다.
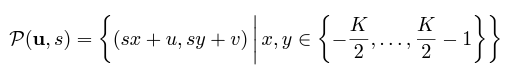
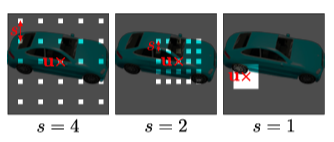
우선 ray sampling이란 3D공간에서 ray를 sampling하는 과정을 의미한다. 이를 통해 각 레이에 따른 3D공간의 정보를 추출하고, 해당 레이에 대한 색상과 밀도를 예측할 수 있다.
GRAF의 supplement paper를 살펴보면 밑의 수식을 확인할 수 있는데, 이는 이전 posting인 NeRF에서의 hierarchical volume sampling의 수식과 같은 sampling이라는 것을 확인할 수 있다.

이러한 ray sampling을 하는 이유는 고해상도의 이미지를 생성하는 데 필요한 세부 정보를 효과적으로 포착할 수 있도록 도와 준다고 한다.
Conditional Radiance Field
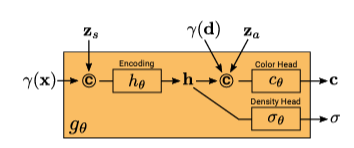
conditional radiance field(이하 CRF)는 positional encoding된 값을 input으로 받아 color 와 volume density 를 output으로 나타낸다. CRF는 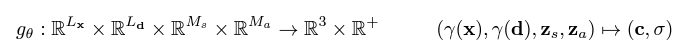 의 수식으로 나타낼 수 있는데, 각각을 살펴보면
의 수식으로 나타낼 수 있는데, 각각을 살펴보면
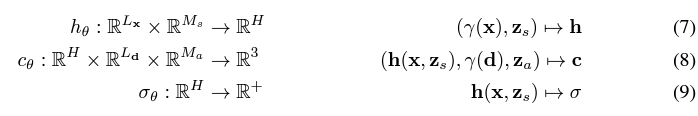
(7),(8),(9) 식으로 표현하고 있다. 여기서 (7),(8),(9)식은 NeRF의 식의 확장이다.
즉, 정리하면 CRF는 NeRF를 사용하여 color 와 density 를 예측하는데, 기존 NeRF에서 추가로 와 라는 shape, apperance variable을 추가로 넣어준다.
이때 와 는 각각
Shape Code (): Shape code는 물체의 형태를 조절하는 데 사용. 이 코드는 학습된 모델에게 특정한 형태의 물체를 생성하도록 지시하는 역활을 진행. 예를 들어, 동일한 위치와 시점 방향에 대해 다른 shape code를 입력하면, 모델은 서로 다른 형태의 물체를 생성 가능. 이를 통해 사용자는 원하는 형태의 물체를 생성하거나 조절할 수 있다.
Appearance Code (): Appearance code는 물체의 외관을 조절하는 데 사용. 이 코드는 학습된 모델에게 특정한 외관 특징을 가진 물체를 생성하도록 지시하는 역할을 진행. 예를 들어, 동일한 위치와 시점 방향에 대해 다른 appearance code를 입력하면, 모델은 외관이 서로 다른 물체를 생성. 이를 통해 사용자는 물체의 색상, 질감, 재질 등을 조절할 수 있게 된다.
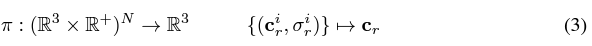
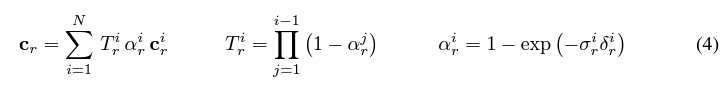
이렇게 나온 를 사용하여 volume rendering을 진행하여 Generator에서 를 생성한다.
Discriminator
Gan의 판별자인 discriminator는 PatchGAN과 유사하게 사용하였다고 한다.(PatchGAN을 공부해야겠다)
result
dataset으로 PhotoShape: Photorealistic Materials for Large-Scale Shape Collections를 사용하여 render하였고,