K-최근접 이웃 방법은 가지고 있는 데이터들과 예측하기 위한 데이터들의 거리를 바탕으로 레이블을 예측하는 방법이다. 예측을 위한 데이터에서 가장 가까운 K개의 데이터 레이블을 가져오고 가장 많이 나타나는 레이블을 새로운 데이터의 레이블로 결정한다.
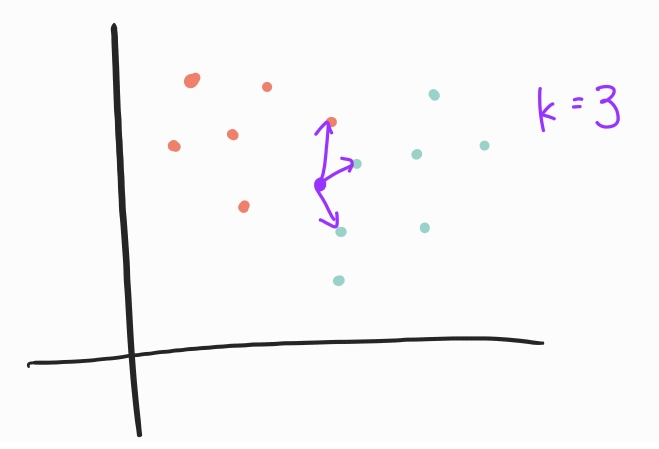
위 그림처럼 k=3으로 둔다면 보라색 점 주위에 가장 가까운 세 개의 점의 레이블을 확인하고 가장 많이 나타난 파란색 점을 보라색 점의 레이블로 결정한다.
이 과정을 구현하기 위해서 먼저 점들 사이의 거리를 계산해주는 함수를 작성한다. (여기서는 유클리디안 거리를 사용한다.)
def euclidean_distance(x1: np.array, x2: np.array) -> int:
return np.sqrt(np.sum(x1 - x2)**2)KNN 클래스에는 훈련데이터를 학습시키기 위한 fit메서드 (KNN은 단순 거리 계산만으로 레이블을 정하므로 학습이 필요하지 않다.), 예측을 위한 predict메서드가 필요하다.
# knn.py
class KNN:
# KNN 클래스를 가져올 때 예측에 필요한 k를 설정
def __init__(self, k=3):
self.k = k
# 학습이 필요하지 않아 주어진 특성들과 레이블을 그대로 넘겨준다
def fit(self, X, y):
self.X_train = X
self.y_train = y
# 모든 레이블 예측
def predict(self, X):
predicted_labels = [self._predict(x) for x in X]
return np.array(predicted_labels)
# 하나의 데이터에 대에 레이블 예측
def _predict(self, x):
# 예측하려는 데이터 하나와 모든 훈련 데이터 사이의 거리 계산
distances = [euclidean_distance(x, x_train) for x_train in self.X_train]
# 거리가 가장 가까운 k개의 인덱스를 가져온다.
k_indices = np.argsort(distances)[:self.k]
# k 개의 인덱스에 해당하는 레이블 저장
k_nearest_labels = [self.y_train[i] for i in k_indices]
# k 개의 레이블 중에서 가장 많이 나타난 레이블 반환
most_common = Counter(k_nearest_labels).most_common(1)
return most_common[0][0]잘 작동하는지 예제를 만들어 예측해보면
# 데이터 생성
from sklearn.datasets import make_blobs
from sklearn.model_selection import train_test_split
X, y = make_blobs(n_samples=100,
n_features=2,
centers=3,
cluster_std=2.0,
random_state=1111)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=1111)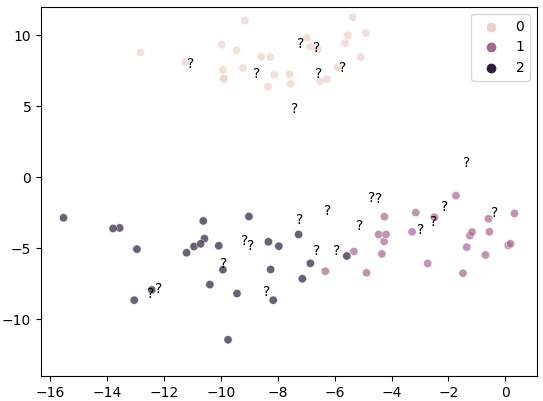
만든 KNN 클래스로 ? 인 값들 예측
from knn import KNN
knn = KNN(k=3)
knn.fit(X_train, y_train)
y_pred = knn.predict(X_test)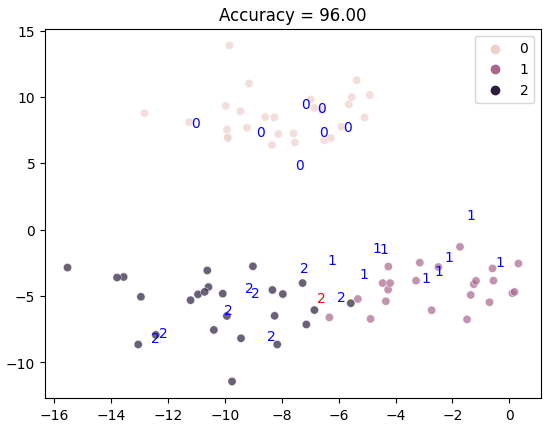
가운데 하나 틀린 값은 가장 가까운 세 값을 가져왔을 때 레이블이 2인 데이터가 2개여서 예측에 실패했다.
하지만 KNN은 거리를 기반으로 예측하는 모델이기 때문에 거리 스케일이 다를 경우 잘못된 예측을 할 가능성이 높다. 때문에 항상 데이터 분포를 정규화 시켜주는 작업이 필요하다.
from sklearn.preprocessing import StandardScaler, MinMaxScaler
scaler = StandardScaler()
# scaler = MinMaxScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)sklearn을 사용한다면 위 과정은
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(X_train_scaled, y_train)
y_pred = knn.predict(X_test_scaled)
print(f"Accuracy: {sum(y_pred==y_test)/len(y_test)*100:.2f}")전체 코드: github

공부 저장용