🧩 학습률(Learning rate), 가중치 초기화(Weight Initialization) & Regularization
1. 학습률
학습률
매 가중치에 대해 구해진 기울기 값을 '얼마나' 경사 하강법에 적용할지를 결정하는 하이퍼 파라미터

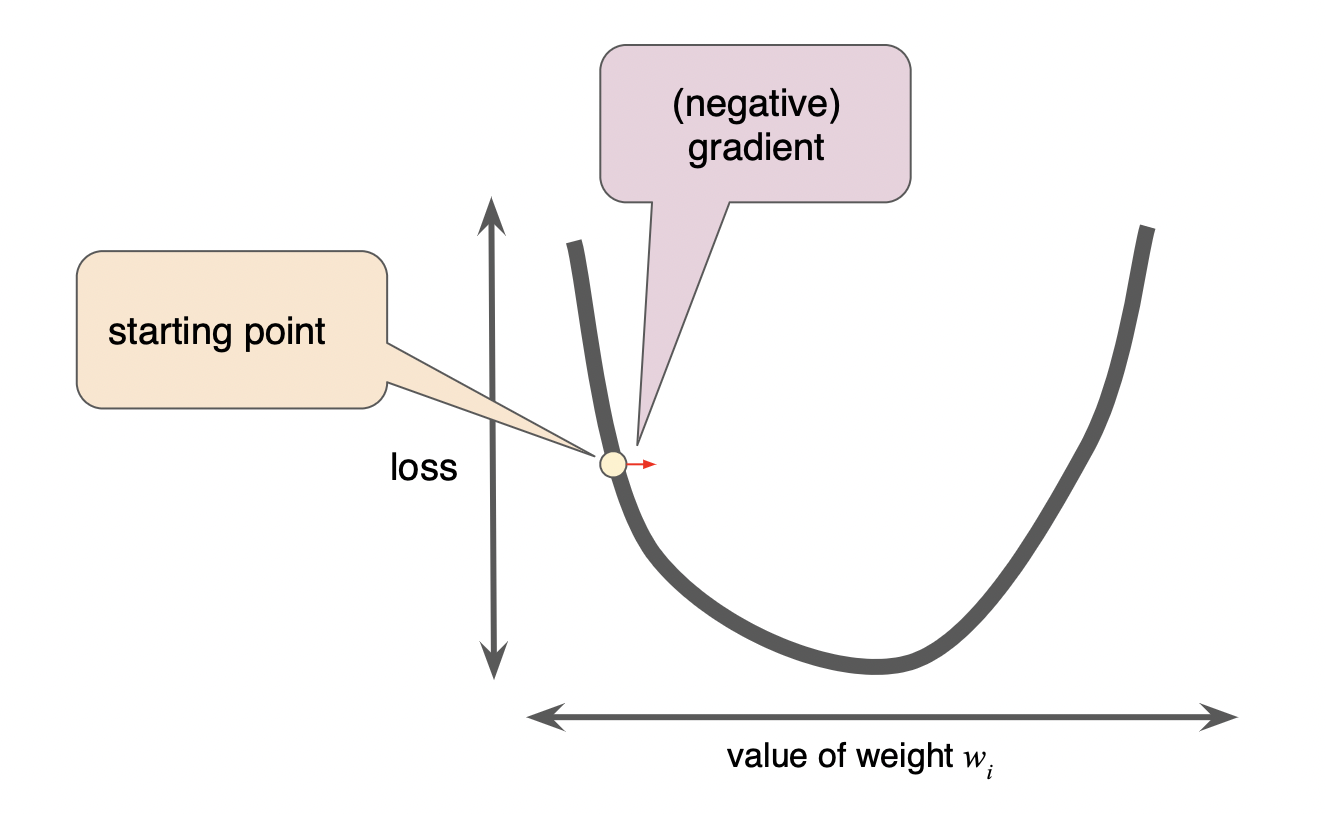
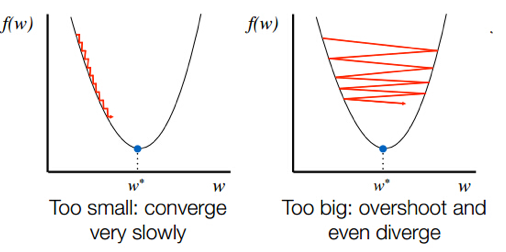
학습률을 보폭이라고 생각하면 이해하기 쉽다.
- 낮은 학습률(left)
- 최적점까지 너무 오래 걸림
- iteration을 다 사용해도 최적점까지 도달하지 못할 수 있음
- 높은 학습률(right)
- 모델의 최적값을 찾기 어려움
따라서 최적의 학습률을 찾는 것이 목표!
1) 학습률 감소법
Optimizer Hyper parameter 변경하여 적용
model.compile(optimizer=tf.keras.optimizers.Adam(lr=0.001, beta_1 = 0.89) , loss='sparse_categorical_crossentropy' , metrics=['accuracy'])
2) 학습률 계획법
Cosine Decay, Step Decay
first_decay_steps = 1000 initial_learning_rate = 0.01 lr_decayed_fn = ( tf.keras.experimental.CosineDecayRestarts( initial_learning_rate, first_decay_steps)) model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=lr_decayed_fn) , loss='sparse_categorical_crossentropy' , metrics=['accuracy'])
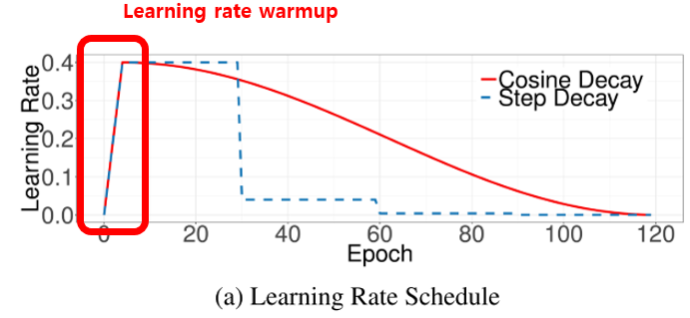
- Warm up
초반 lr을 0까지 낮게 만들었다가 올려서 학습 안정성을 높임
👉🏻가중치들이 아래 그림의 파란 선처럼 이상한 방향으로 튀지 않게
최저점으로 먼저 관성을 옮기겠다는 것

- 최적의 학습률을 알려주는 골디락스....
2. 가중치 초기화(Weight Initialization)
0~1 사이의 값으로 만들어줌!
균등분포
y = w1x1 + w2x2 + w3x3 + w4x4 + ...
x1은 5만큼 중요해 x2는 3만큼 중요해 x3은 4만큼 중요해
이것이 가중치인데
가중치가 다 같게 되면 다 똑같이 학습하므로 학습하나마나…!
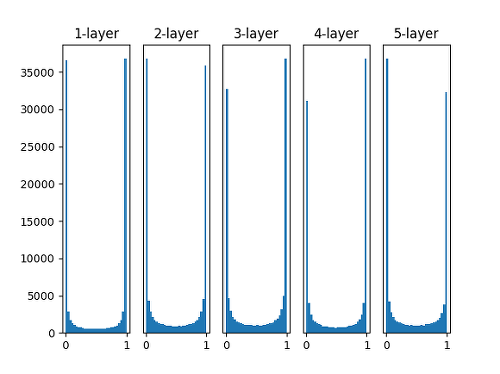
정규분포 1) Xavier 초기화
- Sigmoid에서 동작 (ReLU에선 문제가 보임)
(Sigmoid Gradient Vanishing 때문에 만든 방법)
이전 층의 노드가 n개이고 현재 층의 노드가 m개일 때, 현재 층의 가중치를 표준편차가 1/n**0.5인 정규분포로 초기화- Keras로 구현할 때는 2/(n+m)**0.5
# TensorFlow tf.keras.initializers.GlorotNormal() # PyTorch torch.nn.init.xavier_normal_()초기화 전
초기화 후
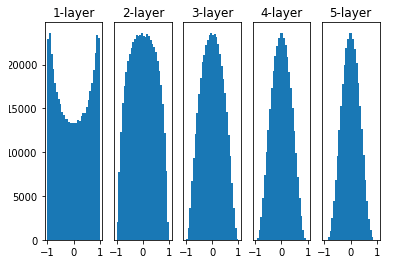
정규분포 2) He 초기화
이전 층의 노드가 n개일 때, 현재 층의 가중치를 표준편차가 2/n**0.5인 정규분포로 초기화
(ReLU는 음수를 모두 0으로 만들어서 노드가 부족해진다! 해서 만든 방법)# TensorFlow tf.keras.initializers.HeNormal()
PyTorch
torch.nn.init.kaimingnormal(`
초기화 전

초기화 후
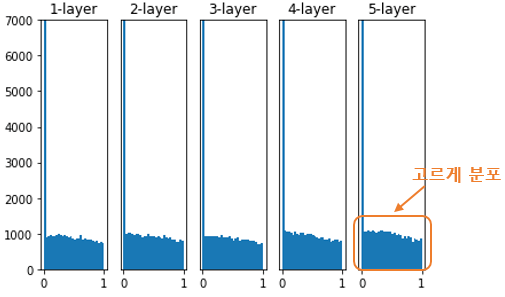
> **Activation function에 따른 초기값 추천**
Sigmoid ⇒ Xavier 초기화를 사용하는 것이 유리
ReLU ⇒ He 초기화 사용하는 것이 유리
## 3. 과적합 Overfitting 방지하기
>과적합: 가중치의 값이 클 때 주로 발생
ex) 한 노드의 가중치가 커 학습의 주가 될 수 있음
### 1) Weight Decay(딥러닝에서 선호하지 않음)
> 가중치 감소를 통하여 가중치의 값이 너무 커지지 않도록, 손실함수에 가중치와 관련된 항목을 추가
>실제 모델 성능 하락시킬 위험도 존재(가중치의 크기 직접적으로 줄이기 때문에)

>
L1 Regularization = LASSO
L2 Regularization = Ridge
### 2) Dropout
> Iteration 마다 레이어 노드 중 랜덤으로 일부를 사용하지 않으면서 학습을 진행
👉🏻 매번 다른 노드가 학습되고, 전체 가중치가 과적합 되는 것 방지
- 복잡한 하나의 모델로 예측하지 않고 간단한 여러가지 모델로 예측하여 그 결과를 합쳐서 사용
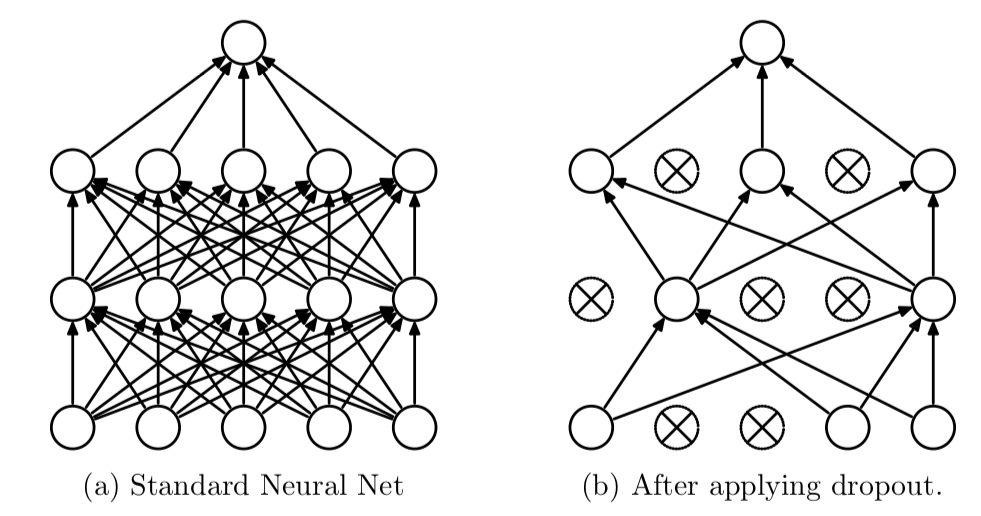
```python Dense(64,
kernel_regularizer=regularizers.l2(0.01),
activity_regularizer=regularizers.l1(0.01))
Dropout(0.5)
- resizing
y = w1x1 + w2x2 + w3x3 + w4x4 + ...
에서 랜덤으로 노드 몇 개를 지우면, (예를 들어 w2x2와 w3x3을 지운다고 가정)
y = w1x1 + w4x4 + ...
y값이 전보다 작아지므로 나머지 노드 값의 비율을 올려주는 방법이 있음
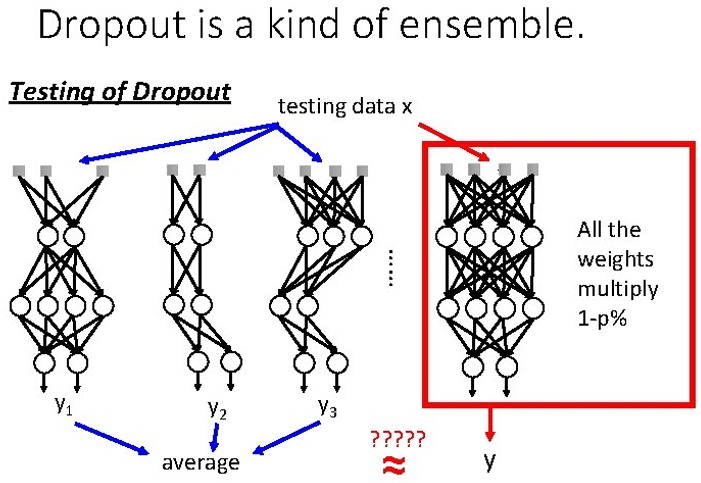
- Dropout의 단점
Dropout을 얼마나, 어느 층에 쓸지 정하는 것이 또 paramete 튜닝이 된다..
모든 노드를 사용하지 않으니 학습에 필요한 epoch가 늘어날 수 있다.
👉🏻 한번에 튜닝을 해주는 WanDB가 있음!
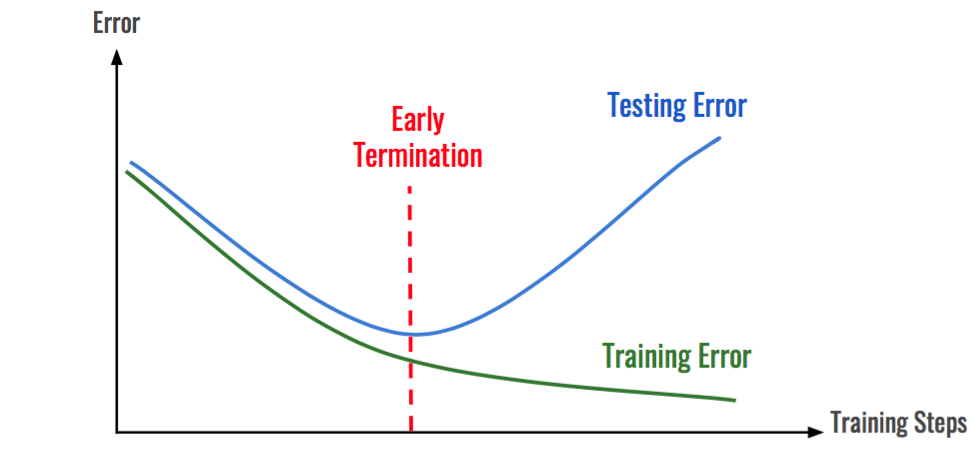
3) Early Stopping
학습 데이터에 대한 손실을 계속 줄어들지만 검증 데이터셋에 대한 손실이 증가한다면 학습을 종료하는 방법
early_stop = keras.callbacks.EarlyStopping(monitor='val_loss', min_delta=0, patience=10, verbose=1) In [11]: save_best = tf.keras.callbacks.ModelCheckpoint( filepath=checkpoint_filepath, monitor='val_loss', verbose=1, save_best_only=True, save_weights_only=True, mode='auto', save_freq='epoch', options=None)
- monitor = 'val_loss' (val_loss값으로 Early stopping 결정)
- patience = 10 (이전 값보다 높은 값이 나오면 10개까지 지켜보다가 더 높은 값이 나오면 그 전 epoch에서 종료)
- Early Stopping Parameters
monitor="val_loss", min_delta=0, patience=0, verbose=0, mode="auto", baseline=None, restore_best_weights=False, )
- patience=2로 지정하면 2번 연속 검증 점수가 향상되지 않으면 훈련을 중지함
- restore_best_weights 매개변수를 True로 지정하면 가장 낮은 검증 손실을 낸 모델 파라미터로 되돌림


Engineer