🧩 Decission Tree(결정트리)
📌 결정트리
결정트리란 뿌리노드(가지가 시작되는 처음 = Root Node)부터 시작해서,
Yes or No로 가지를 마침내 리프노드(가지의 마지막 = Leaf Node)까지 뻗어나가는 의사 결정 과정을 뜻한다.
스무고개처럼 계속해서 질문을 하며 정답을 도출해나가는 과정이다.
많은 질문을 통하여도 정답으로 갈 수 있지만,
어쨌든 알고 싶은 것은 정답이고 정답은 빨리 알아낼 수록 좋은 것!
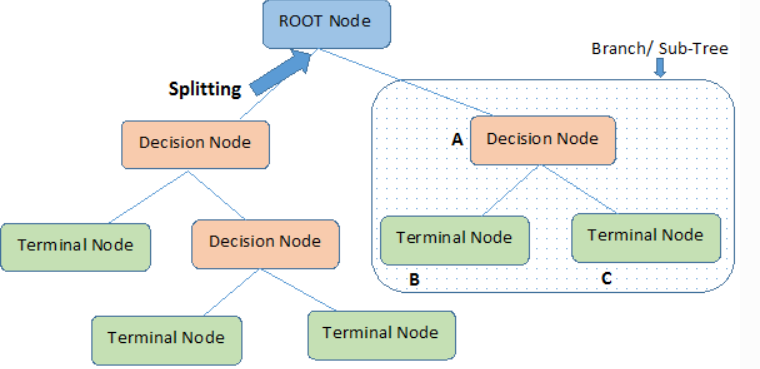 Leaf Node = Terminal Node
Leaf Node = Terminal Node
- 결정트리는 분류와 회귀문제 모두 적용 가능하다.
- 결정트리는 데이터를 분할해 가는 알고리즘이다.
- 분류 과정은 새로운 데이터가 특정 말단 노드에 속한다는 정보를 확인한 뒤 말단노드의 빈도가 가장 높은 범주로 데이터를 분류한다.
스무고개에서 질문을 무엇을 할지 선택하는 것처럼
결정트리를 학습하는 것도 노드를 어떻게 분할할 것인지의 문제이다.
📌 Gini Impurity (지니불순도), Entropy
Impurity(불순도)는 여러 Label이 섞여있는 상태를 말한다.
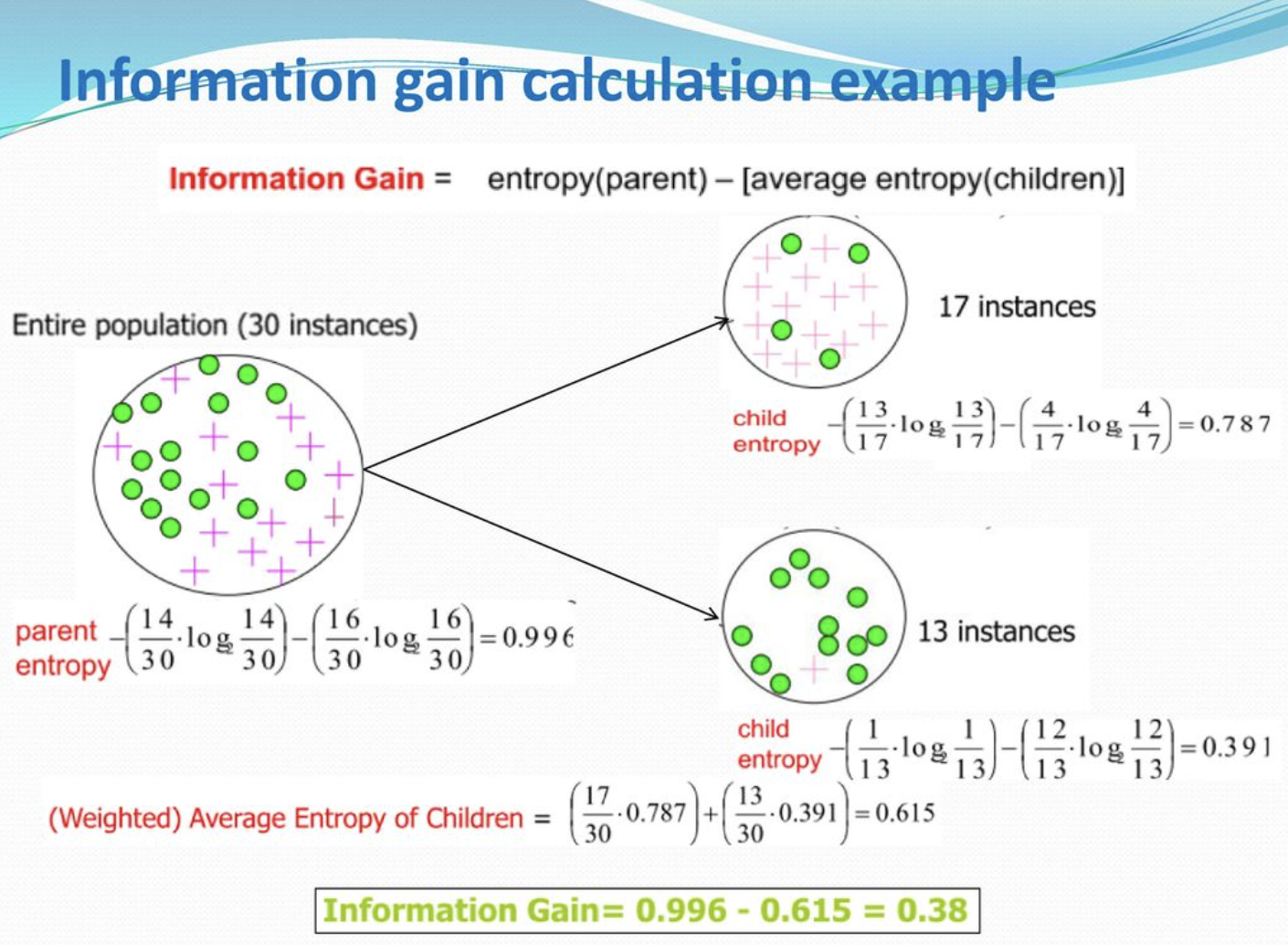
Parent node에는 두 레이블이 16:14로 섞여있는, 불순도가 높은 상태이고
child node로 갈 수록 섞여있는 레이블의 비율이 적어지며 하나의 레이블로 정제되어 있는 것을 볼 수 있다.
한 노드에서 불순도가 최대로 감소하는 지점(분할지점)을 찾는 것이 중요하다.
📌 Information Gain (정보획득)
정보획득은 특정한 특성을 사용해 분할했을 때 엔트로피의 감소량을 뜻한다.
𝐼𝐺(𝑇,𝑎)=H(𝑇)−H(𝑇|𝑎)
= 분할전 노드 불순도 - 분할 후 자식노드 들의 불순도
📌 결정트리 구현
scikit-learn 라이브러리 사용
from sklearn.tree import DecisionTreeClassifier
pipe = make_pipeline(
OneHotEncoder(use_cat_names=True),
SimpleImputer(),
DecisionTreeClassifier(random_state=1, criterion='entropy'))
pipe.fit(X_train, y_train)
print('훈련 정확도: ', pipe.score(X_train, y_train))
print('검증 정확도: ', pipe.score(X_val, y_val))
>>>
훈련 정확도: 0.9908667674880646
검증 정확도: 0.7572055509429486
y_val.value_counts(normalize=True)
>>>
0 0.761001
1 0.238999
Name: vacc_h1n1_f, dtype: float64
✔️ sklearn.pipeline.Pipeline
파이프라인 라이브러리를 사용하여 중복되는 method를 간단히 바꿔줄 수 있다.
✔️ StandardScaler가 들어가지 않는 이유
결정트리에서는 노드를 결정하는 것이 관건이기 때문에 수치를 scale 해주는 StandardScaler는 효과가 없다.
✔️ value_counts()
샘플에서 값들의 비율을 count해준다.
이 데이터에서는 0이 다수범주(76퍼센트)를 차지하고 있다.
데이터에 0만 있다고 가정한 모델을 만들어도, 정확도는 0.76은 무조건 될 것이므로
이 값이 기준모델이 된다.
✔️ 훈련 정확도보다 검증 정확도가 낮다
훈련 정확도는 0.99
검증 데이터는 0.757로 다수범주(0의 비율)와 비슷하게 나왔다.
훈련(train) 정확도보다 검증(validation) 정확도가 낮다는 것은,
모델이 훈련데이터에만 너무 적합하다는 뜻이 된다.
이것을 과적합이라고 한다. (대부분을 0으로 예측)
또한 기준모델과 비슷하게 나온 검증 정확도는 훈련이 제대로 되지 않았음을 의미한다.
