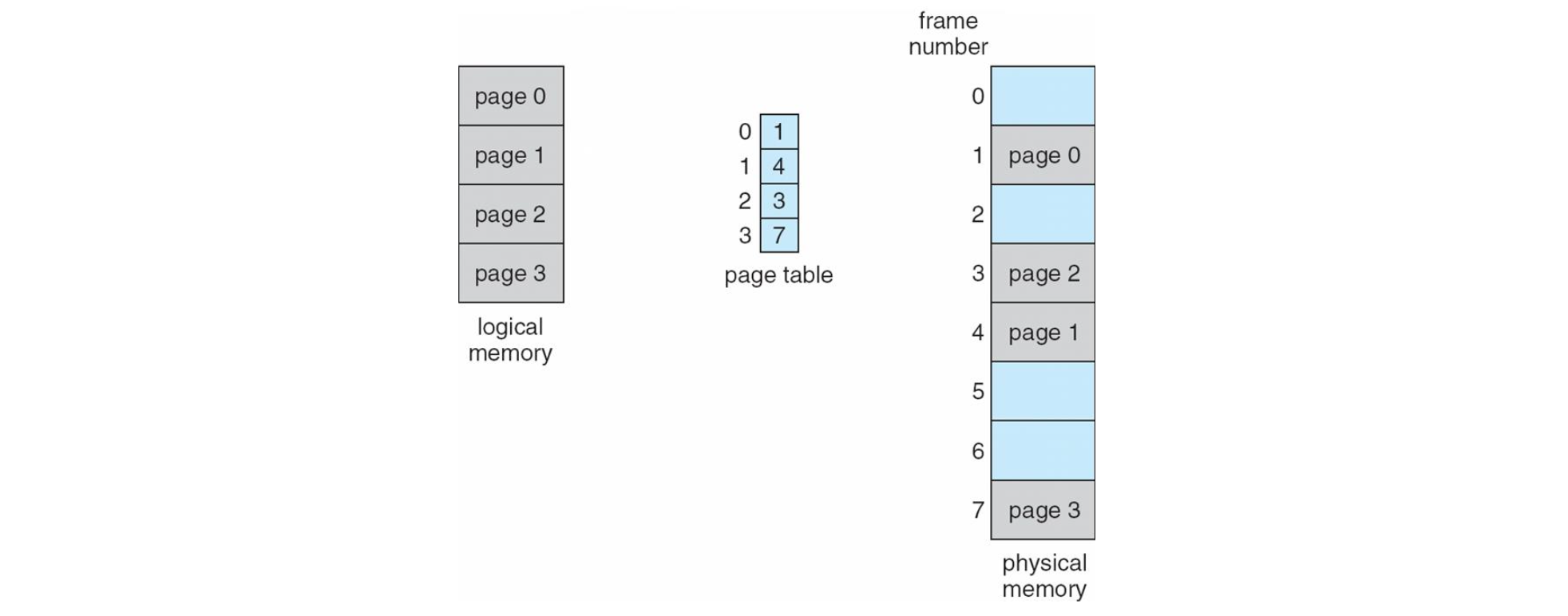
프로세스의 물리적 주소 공간을 Noncontiguous 하게끔 만드는 두 번째 메모리 관리 은 바로 Paging 입니다. 하드웨어와 OS 가 긴밀히 협력하여 구현된 방식입니다. Paging 에서는 애초에 Logical Memory 자체를 똑같은 사이즈의 블럭으로 쪼개며 이 단위를 Page 라고 합니다. 그리고 마찬가지로 물리적 메모리도 고정된 크기의 블럭으로 쪼개어져 페이지가 할당될 수 있게끔 하는데 이 단위를 Frame (Page frame) 이라고 합니다. 논리적 의미를 기준으로 가변적으로 쪼개는 Segmentation 과는 또 다른 관리 방식이죠.
Page 의 크기는 전형적으로 2 의 지수 형태를 취합니다. 왜일까요?

Paging 에서 사용하는 Logical Address 는 세그멘테이션과 같습니다. 의 형태이며 이 때 는 페이지의 번호 는 offset(displacement) 를 나타내죠. 총 비트로 구성된 주소에서 뒤의 비트는 offset 를, 앞은 페이지 번호인 의 값을 가집니다. 그렇기에 이 때 주소 공간의 총 크기는 이며, 하나의 페이지의 크기는 임을 의미하는 것입니다. 보통 페이지의 크기는 4KB ~ 8KB 라고 합니다.
그렇다면 Paging 에서 Logical 주소를 Physical 주소로 바꿔주는 Address mapping 은 어떻게 이루어 질까요? 바로 각 프로세스마다 가지고 있는 Page Map Table (PMT) 를 통해 이루어집니다. 이 PMT 는 커널 영역에 저장되어 있어 OS 가 통제하며 사용자는 이 mapping 과정을 확인할 수 없습니다.
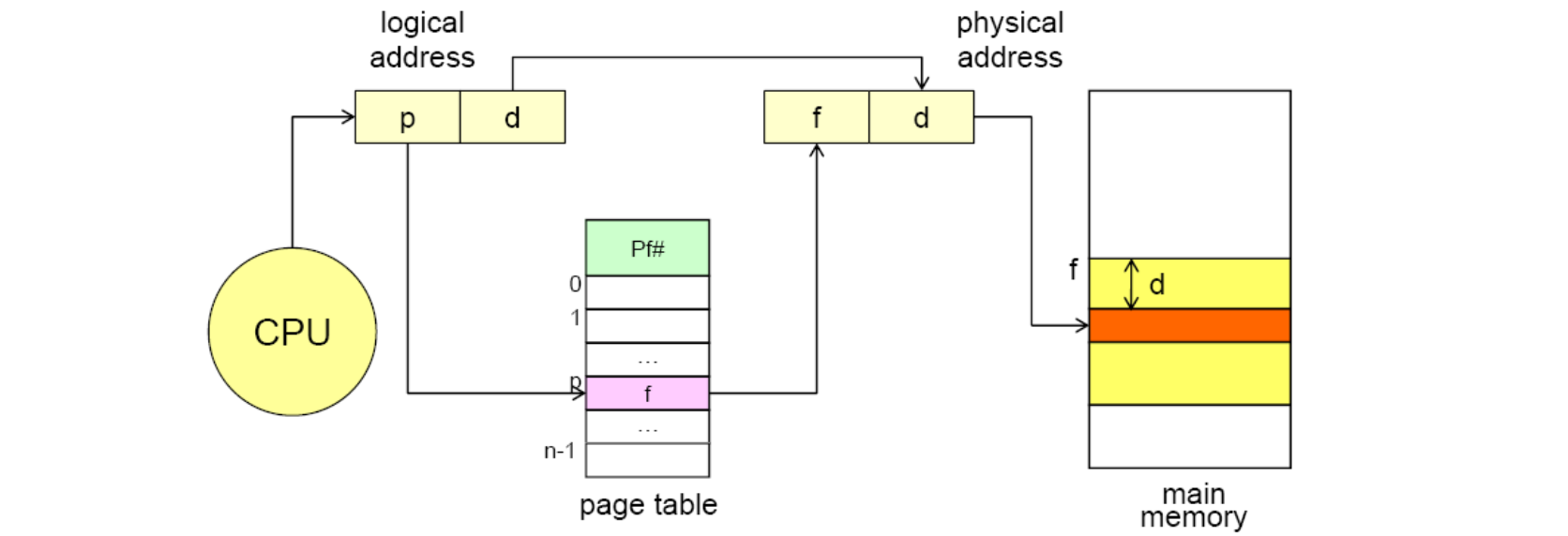
각 프로세스마다 페이지 테이블이 다르기 때문에 현재 CPU 에서 실행 중인 프로세스의 페이지 테이블을 가리키는 레지스터가 필요합니다. 그것이 바로 Page-table base register(PTBR) 입니다. 또한 페이지 테이블의 전체 크기를 나타내는 레지스터가 있는데 Page-table length register(PTLR) 이죠.
물론 페이지 테이블에는 해당 페이지의 프레임 위치 뿐 아니라 해당 프레임에 대한 다른 정보들이 포함될 수 있습니다. 대표적으로 Valid-invalid bit 가 있습니다. 해당 페이지 - 프레임으로의 변환이 유효한지 아닌지를 나타냅니다. Valid 는 현재 페이지가 프로세스의 주소 공간에 있기에 legal 한 페이지임을 나타냅니다. 즉, 프로세스가 접근이 가능하다는 것이죠. 반대로 Invalid 하다는 것은 페이지가 프로세스의 주소 공간에 없는 illegal 한 페이지임을 나타냅니다. 이 페이지에 접근을 한다면 trap 이 발생하는 것이죠. 이렇듯 프로세스에서 실제로 할당되지 않은 페이지들을 물리 메모리 프레임에 할당할 필요가 없어 메모리를 절약하는 데 효과적입니다.

Page-table entry(PTE) 에는 앞선 valid bit 말고도 여러가지 정보를 담는 비트들이 존재합니다. Protection bit 는 메모리가 Read/Write 모드 인지, User/Supervisor 모드 인지 등에 대한 정보를 나타냅니다. 페이지가 물리 메모리나 디스크에 있는 지를 나타내는 Present bit 도 있습니다. Valid 하지만 아직 메모리나 디스크에 없을 수도 있으니까요😁 이와 더불어 페이지 내용이 수정이 일어났는지를 나타내는 Dirty bit 와 페이지에 접근이 있었는지를 나타내는 Reference bit 등도 있습니다.
번외로 각 프로세스의 페이지 테이블에서 가지고 있는 페이지가 꼭 다른 메모리의 페이지를 가리켜야 한다는 법은 없습니다. 예를 들어 코드를 위한 페이지라면 메모장, 컴파일러 등과 같이 여러 프로세스에서 공유하며 사용하는 Shared code 가 존재할 수 있는 것이죠. 마치 여러 스레드가 같은 프로세스 공간을 가지는 것과 비슷합니다. 이는 다양한 Interprocess 커뮤니케이션에 있어 유용한 방식이 될 수 있습니다. 물론 각각의 프로세스가 각자 다른 코드와 데이터를 가질 수도 있죠.
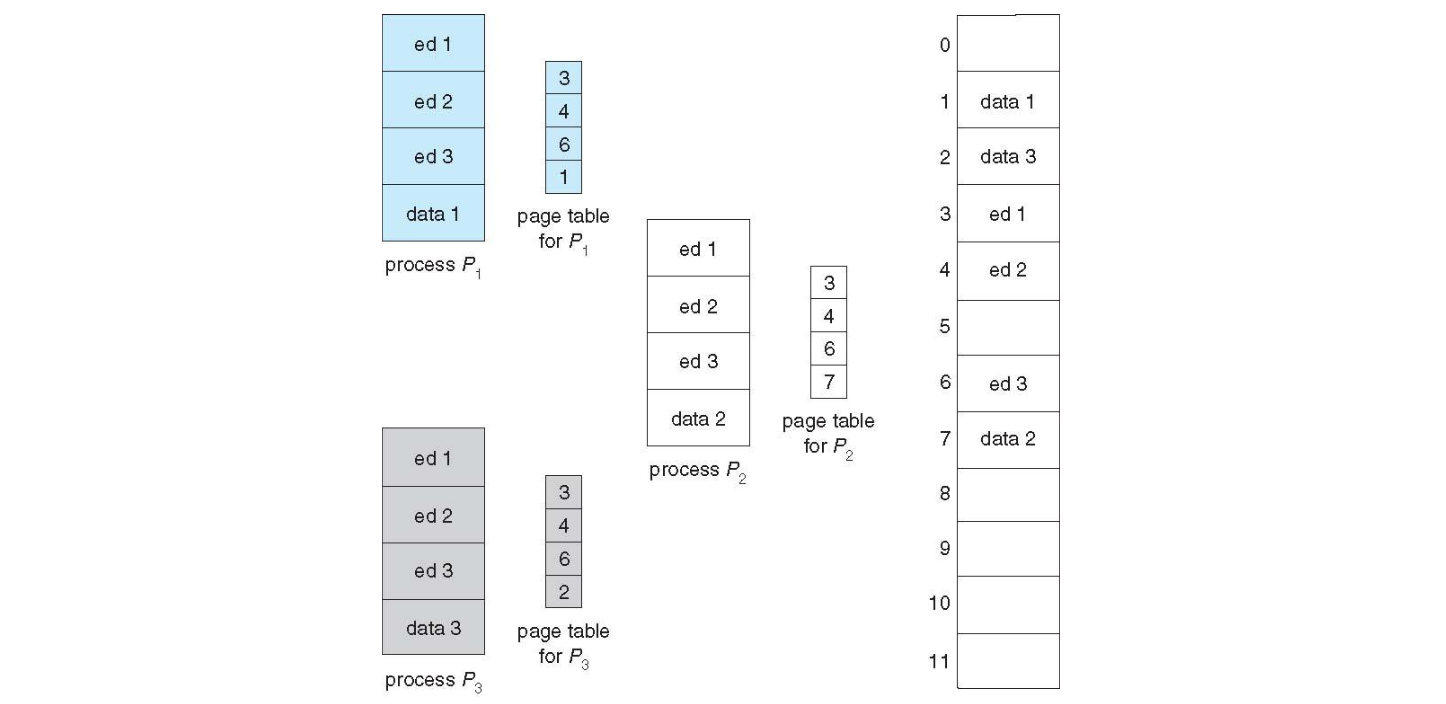
위와 같이 여러 프로세스들이 같은 ed 라는 코드를 공유하면서 각자 다른 데이터를 가질 수 있는 것입니다.
TLB (Translation Look-aside Buffer)
그럼 이제 실제 mapping 을 생각해 봅시다. 프로그램이 실행되면 CPU 는 먼저 메모리의 OS, 즉 커널 영역에 접근해 PMT 를 확인합니다. 그렇게 계산된 물리 주소를 통해 메모리에 접근합니다. 이렇듯 어떤 데이터나 명령어 접근을 위해 메모리 접근을 두 번 을 해야합니다!😰 이 비효율을 최소화하기 위해 개발된 것이 바로 TLB(Translation Look-aside Buffer) 입니다. PMT 의 일부 (최근에 사용된 페이지 위주) 를 CPU 의 MMU 에 장착하는 것입니다.
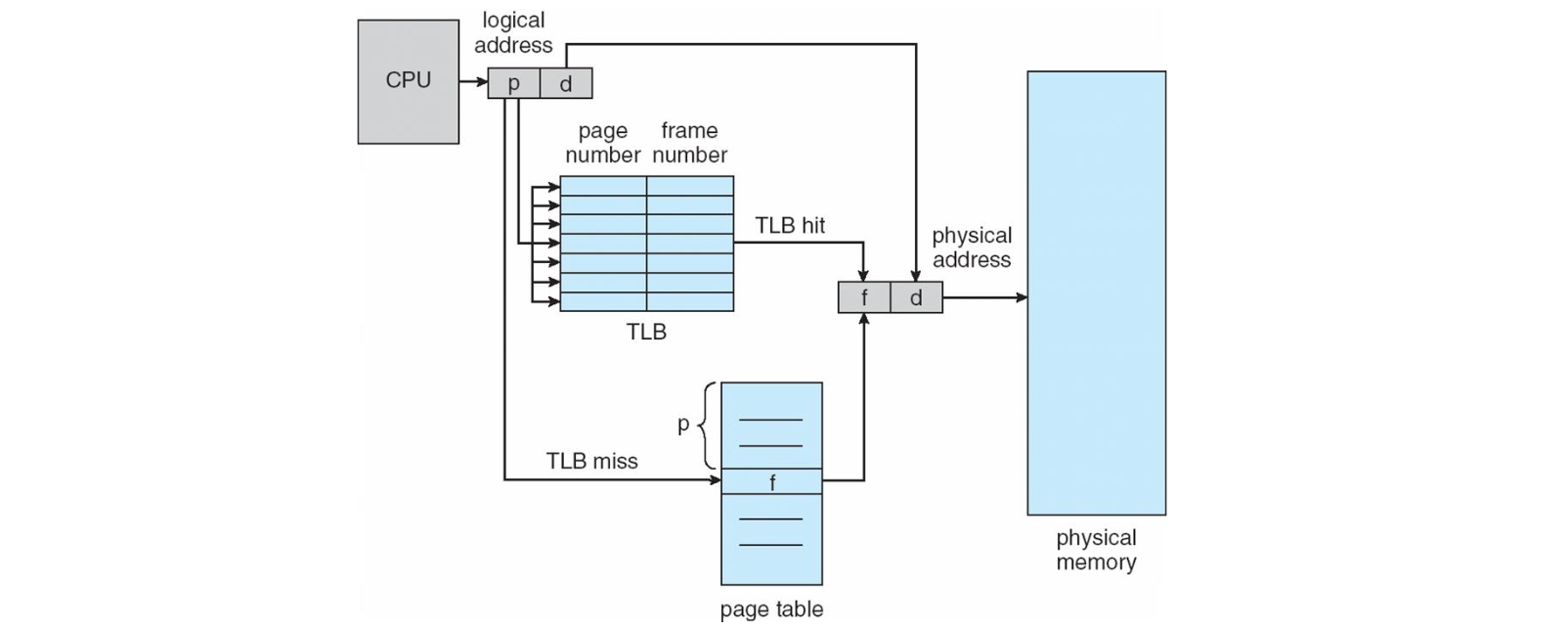
찾고자 하는 페이지 번호를 먼저 TLB 에서 확인하는 겁니다. 만약 존재한다면 TLB hit 으로 빠르게 물리 메모리를 구할 수 있게 됩니다. 만약 없다면 TLB miss 로 기존처럼 PMT 에 접근하여 찾아야 합니다. 이런 TLB 는 64~1024 개 정도의 엔트리를 가지는 매우 작은 버퍼입니다.
TLB 는 hardware-managed(CISC) 와 software-managed 로 나뉩니다. 하드웨어는 TLB miss 가 발생하면 PTBR 을 통해 페이지 테이블에 접근해 원하는 translation 을 찾습니다. 그리고 이를 TLB 에 업데이트 한 뒤, 명령어를 다시 실행시키죠. 그러나 TLB miss 가 무한정 연속으로 나지 않기 위해서는 조금 더 정교한 작업이 필요하며 이를 소프트웨어, OS 에서 뒷받침하게 됩니다. OS 는 TLB miss handler 를 통해 이러한 일들을 수행하죠. 결과적으로 miss 가 일어나면 하드웨어는 exception 을 발생시키고, OS 의 TLB miss handler 가 이를 처리하는 형태가 되겠습니다.
TLB 도 기존 페이지 테이블과 마찬가지로 몇 가지 상태를 나타내는 비트들이 존재합니다. 그 중에 PTE 에서 valid bit 는 페이지가 프로세스에 할당이 되었는지를 나타내는 비트였습니다. 그래서 invalid 한 페이지에 접근하는 것은 OS 로 trap 을 일으켰죠. 그런데 생각을 해보면 TLB 는 페이지 테이블처럼 프로세스가 각자 가지는 것이 아니라 컴퓨터 내에 하나로 모든 프로세스가 공유합니다. 그래서 시스템이 부팅되면, 캐시된 translation 이 없기 때문에 TLB 의 모든 엔트리들이 invalid 로 세팅됩니다. 또한 Context switch 로 프로세스가 바뀌면 TLB 가 flush 되고 모든 엔트리가 invalid 로 세팅되죠. 그런데 이렇게 되면 context switch 할 때마다 cost 가 너무 크지 않겠어요?

그래서 프로세스를 구분하는 Address space identifier(ASID) 정보를 추가하였습니다. 프로세스가 바뀌어도 TLB 에서 해당 ASID 에 맞는 엔트리들만 확인하면 되니 flush 를 하고 valid 를 다시 세팅하고 하는 오버헤드를 아예 없앨 수 있는 것이죠.
Paging: For Smaller Tables
하지만 역시나 대두되는 문제는 페이지 테이블의 크기가 너무 크다는 것입니다. 예를 들어 32-bit 의 logical address space 가 있다고 생각해 봅시다. 그리고 페이지의 크기는 4KB() 로 하죠. 그렇게 되면 페이지 테이블에 필요한 엔트리 수는 개가 됩니다. 각각의 엔트리가 4 바이트라고 해도 약 4MB가 물리 메모리에 할당되어야 하는 것입니다. 그러면 페이지의 크기를 키우면 되잖아요?! 간단하게 생각해서 엔트리 개수가 줄테니까요. 하지만 불필요하게 페이지, 즉 프레임의 크기 자체를 키워버리면 다시 Internal Fragmentation 에 도달하게 될 겁니다.

결국 위와 같이 Sparse 한 페이지의 테이블이 문제입니다. 실제로 물리 메모리의 프레임들 중 대부분이 사용되지 않는다면, 페이지 테이블의 엔트리 또한 비워져 있는 것이고 이는 곧 메모리의 낭비를 의미합니다. 이를 위한 여러 방식들이 있습니다. 하나씩 찾아보죠.
Hybrid Approach: Paging and Segments 은 말 그대로 페이징과 세그멘테이션 방식을 함께 사용하는 것입니다.
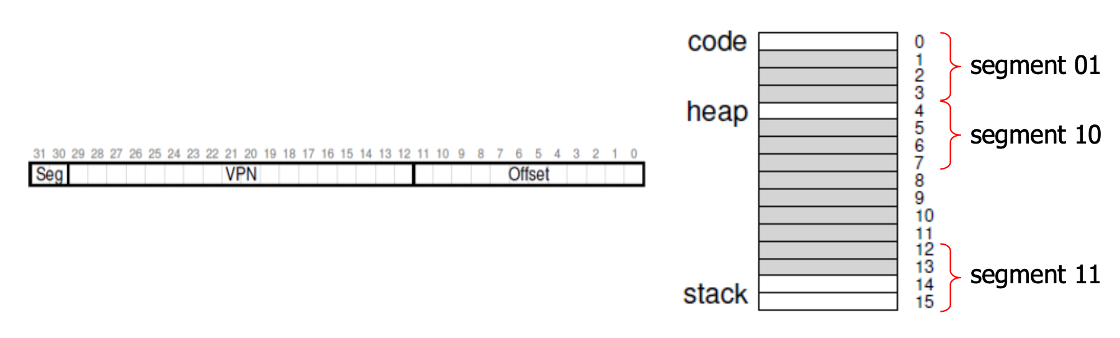
위처럼 주소 공간을 세그멘테이션으로 나누고 각 세그멘트에 한하여 페이지 테이블을 가지는 것입니다. 주소는 위와 같이 해당 세그멘트를 가리키는 비트 , VPN(Virtual Page Number), Offset 으로 되어있죠. 그래서 위 그림처럼 힙과 스택 사이 할당되지 않은 페이지들은 더 이상 페이지 테이블이 필요가 없는 것이죠. 그런데 만약 힙 영역이 크게 sparse 하다면 또 의미가 없어진다는 단점이 있습니다. 더불어, 페이징과 세그멘테이션 같은 non-contiguous 한 방식의 고질적인 문제인 External fragmentation 을 해결하지는 못한다는 것입니다.
Multi-level (hierarchical) Page Tables 는 페이지 테이블에 계층적인 단계를 두는 방법입니다. 아래는 가장 간단하게 Two-Level로의 변화를 보인 그림입니다.
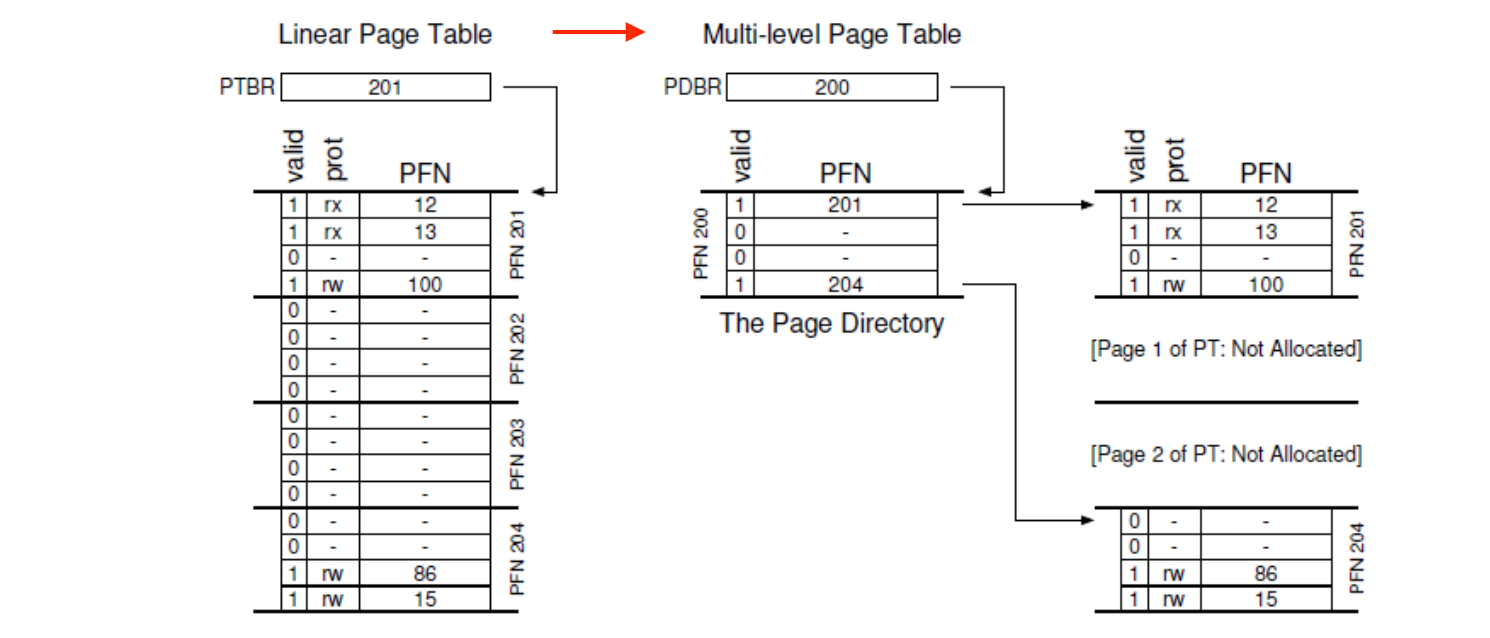
위 왼쪽이 이 기존 페이지 테이블입니다. 선형적으로 되어있기 때문에 다음과 같이 사용되지 않는 202, 203 그룹의 PFN (Page Frame Number) 은 쓸데없이 엔트리를 차지하고 있게 됩니다. 그러나 위 그림에서 페이지(프레임)들을 묶어 그룹으로 만들고, 이 그룹들을 하나의 디렉토리처럼 계층 구조로 만드는 것입니다. 여기서 할당된 201, 204 그룹의 페이지 테이블을 가리키는 엔트리를 저장합니다. 그렇기 때문에 202, 203 그룹의 페이지 프레임들은 페이지 테이블에 할당될 필요가 없는 것입니다.
이렇기 때문에 아주 sparse 한 주소 공간들을 아주 compact 하게 다룰 수 있다는 장점이 있습니다. 그러나 어떤 물리 메모리에 접근하기 위해서 모든 레벨을 순차적으로 거쳐야 한다는 치명적인 단점 또한 존재하죠. 즉 메모리 load 가 n배 더 많아지기 때문에, 시간 과 공간 의 tradeoff 가 필연적으로 발생하게 되는 것입니다.
다음으로, Hashed Page Table 에 대해 알아봅시다. Sparse 를 Dense 하게 만들어주는 자료구조로써 Hash 가 있다는 걸 아시죠? 그걸 이용하는 겁니다!
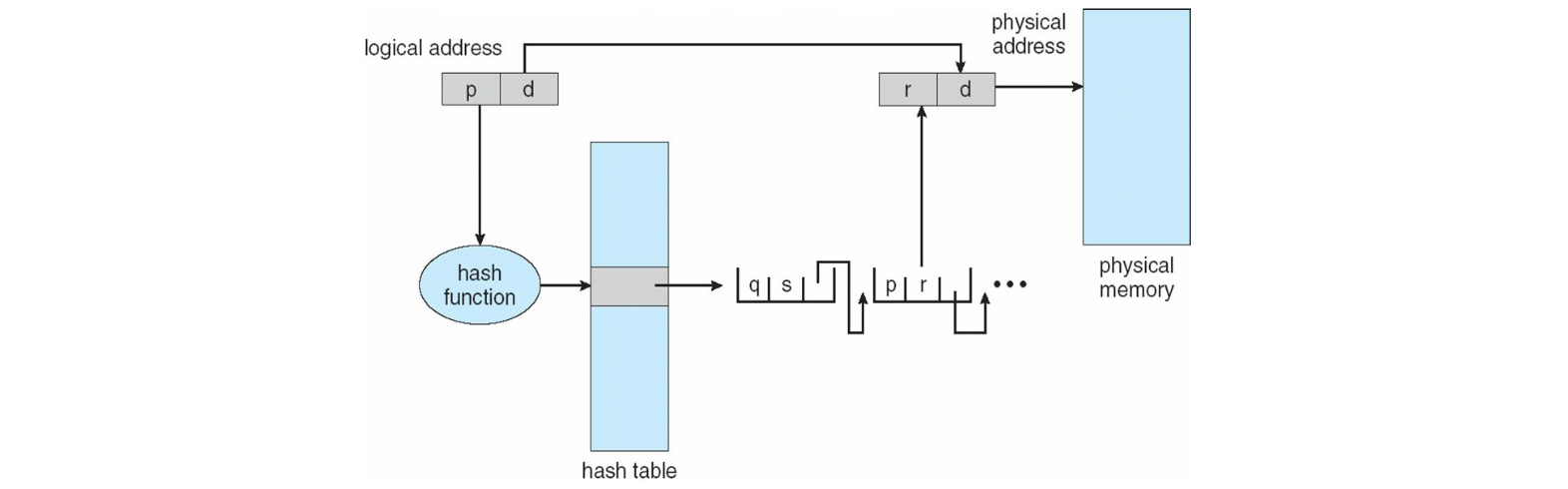
논리 주소의 페이지 번호가 해시 함수를 거쳐 페이지 테이블 즉, 해시 테이블의 엔트리로 이동합니다. 이 테이블은 우리가 해시에서 사용하는 Chaning 을 취하고 있어 매치가 나올 때까지 엔트리를 타고 이동해서 해당하는 값을 찾아 프레임 번호를 알아내는 것이죠. 32비트 이상의 주소 공간에서 흔하게 쓰이는 기법입니다.
