해당 글은 [Catlike Coding/Basics/Jobs] Post를 실습하며 나온 Job System에 관한 내용을 정리한 글이다.
서론
현재 코드또한 충분히 빠르지만, Unity의 Job System을 이용해서 다른 접근을 할 수 있다.
Job System을 이용하면 코드의 Update 시간을 더 줄일 수 있고, Perfomance를 상승시키거나 속도를 늦추지 않고 더 많은 코드를 위한 공간 확보가 가능하다
Job System
Job System의 개념은 CPU의 병렬 처리 능력을 최대한 효율적으로 활용하는 것에 있다. CPU의 Multiple Cores와 SIMD(Single-Instruction-Multiple-Data) 명령을 적극적으로 활용하는 것이다. 이를 위해 Work의 조각들을 Job이라 정의하는데, 이러한 Job들은 일반 C# 코드처럼 작성되지만, Unity's Burst Compiler로 컴파일 되면서 Aggressive한 최적화와 병렬처리가 이루어진다. 이는 일반 C#에는 없는 몇가지 구조적 제약을 적용함으로써 가능해진다.
Burst Package
Burst는 별도의 패키지로 이뤄져 있으며 이 프로젝트에서 Job을 사용하기 위해선 Unity.Burst, Unity.Collections, Unity.Jobs Namespace가 필요하다.
using Unity.Burst;
using Unity.Collections;
using Unity.Jobs;Native Arrays
Jobs는 Object가 아닌 간단함 Value와 Struct Type만 사용할 수 있다.
배열을 사용할 수 있지만, NativeArray라는 Generic Type으로 변환해야한다.
Native Array는 Native Machine Memory를 가리키는 Pointer를 가지고 있는 Struct이며, 우리의 C# 코드에 사용되는 일반적인 Memory Heap 외부에 존재한다.
즉, 기본적인 메모리 관리에서 발생하는 Overhead를 피하기 위함이다.
현재 코드에 Fractal Part를 위한 Native Array를 만들기 위해선 NativeArray를 사용한다. 이러한 배열을 여러개 사용하므로, 우리가 필요한건 이런 배열을 담는 배열이고, Matrices 또한 마찬가지다.
NativeArray<FractalPart>[] parts;
NativeArray<Matrix4x4>[] matrices; parts = new NativeArray<FractalPart>[depth];
matrices = new NativeArray<Matrix4x4>[depth];NativeArray의 생성자에는 다음과 같은 Parameter가 들어간다
1. Array의 사이즈
2. Native Array가 얼마나 길게 존재할지 예상하는 Indicator
이때, 우린 같은 Array을 매 프레임 마다 사용하므로 Allcator.Persistent를 쓴다.
parts[i] = new NativeArray<FractalPart>(length, Allocator.Persistent);
matrices[i] = new NativeArray<Matrix4x4>(length, Allocator.Persistent); for (int li = 1; li < parts.Length; li++)
NativeArray<FractalPart> levelParts = parts[li]; NativeArray<FractalPart> parentParts = parts[li - 1];
NativeArray<FractalPart> levelParts = parts[li];
NativeArray<Matrix4x4> levelMatrices = matrices[li];그리고 사용이 끝나면 Memory를 해제해준다.
private void OnDisable()
{
for (int i = 0; i < matricesBuffers.Length; i++)
{
matricesBuffers[i].Release();
parts[i].Dispose();
matrices[i].Dispose();
}
parts = null;
matrices = null;
matricesBuffers = null;
}이 시점에서 Fractal은 정상적으로 실행된다. 차이점은 C# Array 대신 Native Array를 사용한다는 것이다.
이것은 자칫 더 안좋은 성능을 가져올 수 있는데, 이는 C# 코드로부터 관리되는 Native Array는 아주 약간 OverHead가 일어날 수 있기 때문이다.
이러한 Over Head는 Burst-Compiled Job을 사용하면 사라질 것이다.
Job Struct
Job을 정의하기 위해선 Job Interface를 구현하는 Struct Type를 만들어야한다.
Interface를 구현하는 것은 Class를 확장하는 것과 비슷하지만 기존 기능을 상속받는 것 대신 특정 기능을 직접 구현해야한다.
struct UpdateFractalLevelJob : IJobFor
{
public float spinAngleDelta;
public float scale;
[ReadOnly]
public NativeArray<FractalPart> parents;
public NativeArray<FractalPart> parts;
[WriteOnly]
public NativeArray<Matrix4x4> matrices;
public void Execute(int i) { }
}Execute 메서드가 Update 메서드의 가장 안쪽 루프의 코드를 대체하도록 해당 코드의 모든 변수를 넣고, 접근할 수 있도록 Public으로 정의한다.
또한 ReadOnly와 WriteOnly를 사용하여 일부 NativeArray의 부분적인 접근만 가능하도록 한다.
여러 Processes가 동일한 데이터를 병렬적으로 수정하면, 어느 것이 먼저 처리되는지는 임의로 결정된다.
1. 두 Process가 같은 배열 요소를 수정하면, 마지막에 설정한 값이 남는다.
2. 한 Process가 다른 Process가 설정중인 동일한 요소에 접근하면, 이전 값이나 새로운 값 중 어느 쪽을 얻게 될지 알 수 없다.
최종 결과는 우리가 제어할 수 없는 정확한 타이밍에 따라 달라지며, 이는 일관성 없는 동작을 초래할 수 있어, 문제를 감지하고 수정하기 매우 어려워진다.
이러한 현상을 경쟁 조건(Race Conditions)이라고 한다.
ReadOnly 속성은 해당 데이터가 작업 실행중 일정하게 유지된다는 것을 나타낸다. 이는 Process들이 안전하게 병렬로 읽을 수 있으며, 결과가 항상 동일하게 유지된다.
컴파일러는 작업이 ReadOnly 데이터에 Write하지 않고, WriteOnly 데이터는 읽지 않도록 강제한다.
만약 실수로 이를 어길 경우, 컴파일러가 의미적 오류를 알려줘서 문제를 바로잡을 수 있다.
Executing Jobs
Execute 메서드는 Update단에서의 내부 Loop를 대체할 것이다.
하지만 우리는 매 Iteration마다 Invoke할 필요는 없다. 이 개념은 우리가 Job의 스케쥴을 정함으로써 그것의 Loop내에서 수행하게 하는 것이다.
이 기능은 Schedule을 Invoke하여 실행되게 할 수 있고, 2개의 Parameter를 가진다.
1번째 Parameter에는 얼마나 많은 Iteration이 필요한지인데, 이는 우리가 Processing중인 Part의 길이와 같다.
2번째 Parameter에는 JobHandle Struct Value로, Job 사이의 순차적 의존성을 강제하는 데 사용된다. 처음에는 이 구조체에 기본값을 사용할 건데, Default 키워드를 사용하면 아무적 제약을 적용하지 않게 된다.
Schedule은 Job을 즉각적으로 실행시키지 않는다. 추후의 Processing을 위해 스케쥴될 뿐이다.
스케쥴은 Job의 진행도를 추적할 수 있는 JobHandle Value를 반환한다.
우린 Complete()를 Invoke하여 Job을 끝내기 전까지 Delay 시킬 수 있다.
Scheduling
현재 시점에선, 각 레벨마다 Job을 예약하고, 완료될 때까지 기다리는 방식이라 Job System으로 변경했음에도 Fractal이 이전처럼 순차적으로 업데이트 된다.
이 방식을 개선하기 위해 모든 작업을 예약한 후에 완료를 기다리도록 설정할 수 있다.
이를 위해 각 Job들이 이전 Job에 의존하도록 만들어서, 마지막 Job Handle을 다음 Job에 전달하면서 예약하는 방식으로 진행한다.
그리고 Loop가 끝난 후 Complete를 호출하면 전체 Job Sequence가 실행되도록 유도할 수 있다.
이때 우린 이제 각 Job을 변수에 저장할 필요 없이, 마지막 Handle만 추적하면 된다.
Job들은 Main Thread가 아닌 Worker Thread에서 실행된다. 하지만 Main Thread가 Job들을 완료될 때까지 기다려야 하므로, 현재로서는 Job이 어디서 실행되든 큰 차이는 없다. 예약된 Job들은 서로 다른 Thread에서 실행될 수 있지만, 여전히 순차적 의존성을 유지된다.
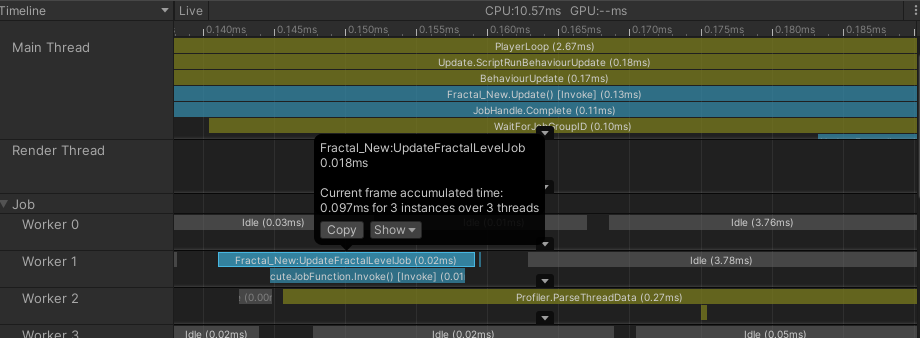
모든 작업을 한꺼번에 실행하도록 묶고, 마지막 작업의 완료를 기다리는 것의 장점은 완료 대기를 지연시킬 수 있다는 점에 있다.
예를 들어, 모든 Job을 Update에서 예약한 후 다른 Job을 수행하고, Complete 호출을 지연하여 Late Update에서 완료를 기다릴 수 있다.
Burst Compliation
이러한 변화에도 전형 성능 향상을 보지 못하는데, 이는 Burst Compiler를 사용하고 있지 않기 때문이다.
Burst Compiler를 사용하면 Frame Debugger는 Burst-Compiled된 Job들을 보여준다. 이 시점에서 App은 Burst에 의해 최적화 되어 조금 빠르게 작동하지만, 큰 효과가 나오진 않는다.
심지어 Play Mode에 들어가면, Editor의 성능은 더 저하된다는 것을 알게 될 것이다.
왜냐하면 Burst Compilation은 Shader Compilation처럼 Editor에 의존하기 때문이다.
Job이 처음 실행될때, 일반적인 C# Compiled Version이 실행될때와 같이 Burst로 실행된다.
Burst Compilation이 끝나면, Editor는 Burt Version으로 바뀔 것이다.
이때, CompileSynchronously를 Property를 사용하면 Editor가 바로 Burst로 컴파일 되도록 설정할 수 있다.
Shader 컴파일처럼 Build에 영향을 주지 않는데, 이는 모든 과정이 Build Process에서 컴파일 되기 때문이다.
Burst Inspector
Burst Compiler가 생성한 Assembly 코드는 Burst Inspector에서 확인할 수 있다.
여기에서 Project의 모든 Job에 대한 Burst가 생성한 Low Level Instruction을 볼 수 있다.
우리의 Job들은 Complie Target List의 Fractal.UpdateFractalLevelJob-(IForJob)으로 표시될 것이다.
생성된 코드를 세부적으로 분석하지는 않을 것이지만, 성능 개선에 대한 부분은 스스로 증명되어야만 한다.
오른쪽 끝에 있는 .LVM IR Optimization Diagnostic Display Mode로 전환하면 Burst가 무엇을 하는지 이해할 수 있다.
Remark: IJobFor.cs:43:0: loop not vectorized: loop control flow is not understood by vectorizer
Remark: NativeArray.cs:162:0: Stores SLP vectorized with cost -3 and with tree size 2첫번째 Remark는 Burst가 SIMD 명형을 사용해서 여러 반복 작업을 Merge하지 못했다는 것을 나타낸다.
간단한 예시로, data[i] = 2f * datat[i]와 같은 Job이 있다고 생각해보자.
SIMD Instruction을 사용하면 Burst는 이 Job은 한번에 여러 Index를 실행할 수 있도록 변경할 수 있다.
이상적인 경우, 최대 8개의 Index를 동시에 처리할 수 있다. 이렇게 연산을 Merge하는 것을 Vectorization이라고 하며, 이는 단일 값에 대한 Instruction을 Vector에 대한 Instruction으로 대체하는 것을 의미한다.
Burst가 Control Flow를 이해하지 못한다고 나타내는 것은 복잡한 조건 블록이 있다는 뜻이다.
우리는 그런 조건을 사용하지 않았지만, 기본적으로 Burst Safety Checks가 활성화 되어 있다.
이 검사는 읽기/쓰기 속성을 강제하고, 같은 배열에 병렬로 쓰려고 하는 등의 Job간 의존성 문제를 감지한다.
이러한 검사는 Development에서만 사용되며 Build에서는 제거된다.
Burst Inspector에서 최종 결과를 확인하려면 Safety Check Toggle을 비활성화 할 수 있다.
또한 각 Job별로, 또는 Project 전체에 대한 Saftey Check Toggle을 비활성화 할 수 있다. 보통 Editor에서는 Safety Check를 활성화하고, Build에서 성능을 테스트하지만, Editor 성능을 극대화 하려면 Safety Check를 비활성화 할 수 있다.
Safety Check를 비활성화 해도 여전히 Loop를 Vectorise할 수 없는 경우가 있다. 이런 경우는 Call Instruction의 문제로, 이는 Burst가 최적화하지 못하는 메서드 호출이 있다는 뜨시며, 이는 Vectorize할 수 없다.
두번째 Remark는 Burst가 독립적인 여러 연산을 단일 SIMD 명형으로 벡터화하는 방법을 찾았다는 뜻이다. 예를 들어, 독립적인 값들의 Add 연산을 단일 Vector Add로 Merge했다는 거다. Cost of -3는 이런 방식으로 3개의 Instruction이 효과적으로 제거되었다는 뜻이다.
SLP란?
SLP는 Superword-Level Parallelism의 약자로, 이는 여러 독릭접 작업을 병렬로 처리하는 SIMD 방식의 최적화를 가리킨다.
후기
후반의 Code에 관련된 부분은 Skip하였다. 해당 튜토리얼은 이전과 다르게 튜토리얼을 그대로 따라하면 정상적으로 작동하지 않는다. 우선 튜토리얼로 이론적인 부분과 메서드를 보고, Repository에서 Code를 참고하거나, Clone하여 실제 동작을 확인해보는 것이 좋다.
해당 튜토리얼은 Unity C# Job System에 관한 내용을 다루고 있다.
정리하자면 Job System은 Unity에서 제공하는 멀티 스레딩 프레임 워크로, CPU 리소스를 효율적으로 활용하여 성능을 개선할 수 있다.
Burst Compiler를 C# Job과 함께 사용하면 코드 작성 품질이 개선된다.
Job System에 대한 자세한 내용은 [Unity Doc - Job]에서 확인할 수 있으며, 튜토리얼만으론 부족하지 해당 Doc을 읽어볼 필요가 있다.
