[paper-review] Mask TextSpotter v3: Segmentation Proposal Network for Robust Scene Text Spotting
Paper Review
개인적인 논문해석을 포함하고 있으며, 의역 및 오역이 남발할 수 있습니다. 올바르지 못한 내용에 대한 피드백을 환영합니다 :)
1. Introduction
[@ Scene text spotter]
- 최근 scene text spotting task에는 end-to-end 학습 방식의 딥러닝이 많이 적용되고 있음
- 좋은 scene text spotting 아래 세 가지 능력을 갖추어야 함
- Rotation robustness: 텍스트가 이미지 축에 잘 정렬되어 있지 않았을 때에 강건함
- Aspect ratio robustness: non-Latin scripts에는 주로 word 단위보다는 긴 텍스트 라인으로 텍스트 인스턴스가 구성되어 있는데, 이처럼 다양한 텍스트 인스턴스 종횡비에 강건함
- Shape robustness: Logo같은 텍스트에 주로 나타나는 일반적이지 않은 모양의 텍스트에 강건함
[@ Mask TextSpotter series]
- Region Proposal Network(RPN)의 한계
- manually pre-designed anchors를 사용하므로 극단적인 종횡비를 가지는 텍스트 인스턴스를 포착하기 쉽지 않음
- RPN이 생성하는 axis-aligned rectangular proposals는 그 box안에 인접한 다른 텍스트 인스턴스들이 함께 포함되는 경우가 많음
 anchor-box, 출처
anchor-box, 출처
 (2)번 한계의 예시
(2)번 한계의 예시
- 선행연구, Mask TextSpotter v1, Mask TextSpotter v2에서는 Region Proposal Network (RPN)을 통해 RoI feature를 추출하고 이 RPN이 제안한 proposal box들에 detection과 recognition을 수행
- rotation robustness, shape robustness를 갖출 수 있는 RPN을 제안
- But, aspect ratio robustness까지 모두 갖추지는 못했음
[@ Segmentation Proposal Network (SPN)]
- Segmentation Proposal Network을 통해 정확한 polygonal 형태의 proposal 표현을 할 수 있음
- 더 나아가 정확한 형태의 proposal 표현을 통해 hard RoI masking 방법을 적용, 인접한 텍스트 인스턴스나 배경 노이즈의 간섭을 억제할 수 있음
[@ Contributions]
- Segmentation Proposal Network(SPN)
- 극단적인 종횡비나 특이한 형태를 가진 텍스트 인스턴스를 정확하게 포착할 수 있는 SPN를 제안
- hard RoI masking
- SPN이 생성해낸 proposal에 적용하여 배경 픽셀이나 인접한 다른 텍스트 인스턴스가 유발할 수 있는 노이즈를 제거
- Mask TextSpotter v3
- rotation, aspect ratio, shape에 모두 robust한 text spotter 모델
- 다양한 벤치마크에 높은 성능을 보임
2. Related Work
[@ Two-stage scene text spotting]
- Wang et al. tried to detect and classify characters with CNNs.
- Jaderberg et al. proposed a scene text spotting method
- proposal generation module
- a random forest classifier to filter proposals
- a CNN-based regression module for refining the proposals
- a CNN-based word classifier for recognition
- TextBoxes and TextBoxes++ combined thier proposed scene text detector with CRNN
- Zhan et al. proposed to apply multi-modal spatial learning into the scene text detection and recognition system.
[@ End-to-end trainable scene text spotting]
- Mask TextSpotter v1 is the first end-to-end trainable arbitrary-shape scene text spotter
- consisting of a detection module based on Mask R-CNN and character segmentation module for recognition.
- Mask TextSpotter v2 extends Mask TextSpotter v1 by applying a spatial attention module for recognition
- spatial attention module: character 수준의 공간적 왜곡을 바로 잡아줄 수 있는 모듈
- Qin et al. also combine a Mask R-CNN detector and an attention-based recognizer to deal with arbitrary-shape text instances
- Qin et al.의 연구에선 mask map을 recognition에 성능향상을 위해 RoI feature에 대해 RoI masking을 수행
- 하지만, mask map을 생성하는 데 RPN을 사용하기 때문에 proposals을 생성하는 데 부정확한 결과를 만들어낼 수 있음 (Introduction에서 밝힌 RPN의 단점)
- Xing et al. propose to simultaneously detect/recognize the characters and the text instances, using the text instance detection results to group the characters.
- TextDragon detects and recognizes text instances by grouping and decoding a series of local regions along with their centerline
[@ Segmentation-based scene text detectors]
- Zhang et al. first use FCN to obtain the salient map of the text region
- then estimate the text line hypotheses by combining the salient map and character components.
- Finally, another FCN predicts the centroid of each character to remove the false hypotheses.
- He et al. propose Cascaded Convolutional Text Networks (CCTN) for text center lines and text regions.
- PSENet adopts a progressive scale expansion algorithm to get the bounding boxes from multi-scale segmentation maps.
- DB proposes a differentiable binarization module for a segmentation network.
- 본 논문에서는 기존 Segmentation-based scene text detector에 비해 다양한 단서와 추가적인 모듈을 결합하여 detection task를 수행함
- proposal generation에 segmentation network을 사용한다는 점을 강조할 수 있음
3. Methodology
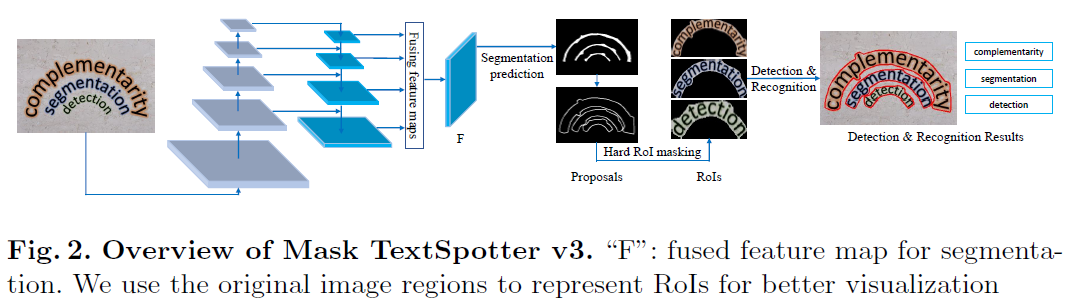
Mask TextSpotter v3 consists of ...
- a ResNet-50 backbone, a Segmentation Proposal Network (SPN) for proposal generation
- a Fast R-CNN module for refining proposals
- a text instance segmentation module for accurate detection
- a character segmentation module and a spatial attentional module for recognition
추가적으로 Mask TextSpotter v3는 RoI feature의 형태를 다각형, polygonal 형태로 생성하기 때문에 정확한 detection을 할 수 있고 recognition의 성능에도 좋은 영향을 줄 수 있음
3.1. Segmentation proposal network
- U-Net의 형태를 사용, 다양한 크기의 다양한 feature를 사용
- SPN의 output 는 위 feature들을 결합하여 크기로 생성됨
- 는 각각 입력 이미지의 높이, 너비
- 를 통해 Segmentation을 수행하여 최종적으로 크기의 predict segmentation map 를 생성함
 최종 Segmentation 수행 모듈의 구조
최종 Segmentation 수행 모듈의 구조
[@ Segmentation label generation]
Segmentation 성능 향상을 위해 text instance들의 크기를 축소시킴으로써 인접한 text instance들을 분리하려는 테크닉이 일반적임
- Vatti clipping algorithm
- pixel 만큼 텍스트 영역을 축소시키는 테크닉
- the offset pixel
- 는 텍스트 인스턴스 polygon의 면적
- 은 텍스트 인스턴스 polygon의 둘레
- is the shrink ratio
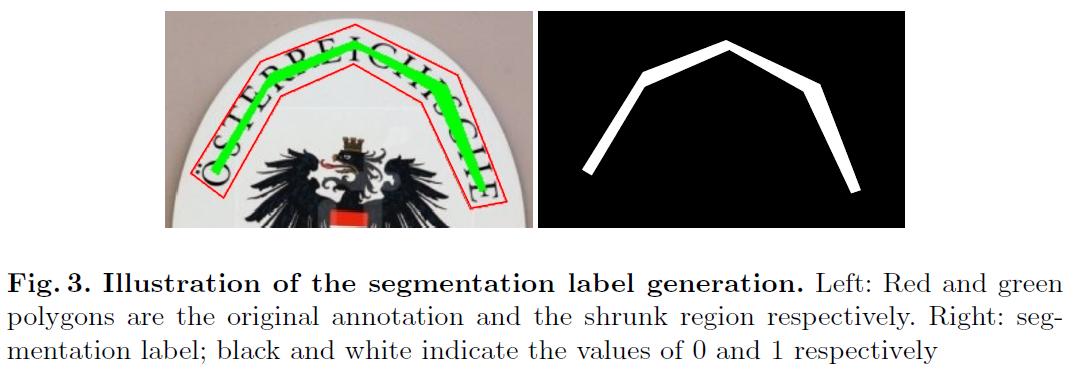
[@ Proposal generation]
- 먼저 Segmentation map 를 이진화하여 binary map 를 계산
- 이후 Vatti clipping algorithm을 원복
3.2. Hard RoI masking
- 직사각형의 binary map 에서 각 text instance RoI feature와 크기가 동일한 polygon mask 을 생성
- RoI feature , 는 element-wise multiplication
- hard RoI masking을 통해 배경 영역이나 인접한 다른 텍스트 인스턴스들의 방해를 억제할 수 있음
- 결과적으로 detection과 recognition 모두에 성능 향상을 도모할 수 있음
3.3. Detection and recognition
- text detection and recognition의 설계는 Mask TextSpotter v2의 것과 동일
- Mask TextSpotter v2가 당시 최고의 detection, recognition 모델임
- RPN-based scene text spotter와 (본 논문에서 제안하는) SPN-based scene text spotter의 공정한 비교를 위함
- hard RoI masking을 거친 masked RoI features는 Fast R-CNN의 입력으로 주어지고 localization을 가다듬고 character segmentation module과 spatial attentional module로 recognition을 수행
3.4. Optimization
- is defined in Fast R-CNN
- is defined in Mask TestSpotter v2, consisting of a text instance segmentation loss, a chracter segmentation loss, and a spatial attentional decoder loss.
- indicates the SPN loss
- SPN loss엔 Dice loss를 사용
- is the segmentation map, is the target map, represents element-wise multiplication.
- SPN loss엔 Dice loss를 사용
4. Experiments
4.1. Datasets
- SynthText
- 800K 텍스트 이미지를 포함한 합성 데이터셋
- annotations for word/character bounding boxes and text sequences.
- Rotated ICDAR 2013 dataset (RoIC13)
- ICDAR 2013 데이터셋에서 를 회전시켜 직접 제작
- ICDAR 2013의 텍스트 인스턴스들이 모두 수평적으로 정렬되어 있기 때문에 이 특성을 이용해 텍스트의 회전 방향에 대한 강건함(rotation robustness)을 테스트 할 수 있음
- MSRA-TD500
- 영어와 중국어로 구성된 multi-language scene text detection benchmark
- 많은 수의 텍스트 인스턴스가 극단적인 종횡비로 구성됨
- recognition annotations가 포함되지 않음
- Total-Text
- 다양한 형태의 텍스트 인스턴스, 가로세로 방향의 인스턴스, 곡선 형태의 텍스트들이 포함
- polygonal bounding box와 transcription annotations 포함
- ICDAR 2015 (IC15)
- quadrilateral bounding boxes로 레이블 구성
- 대부분의 이미지가 저해상도이고 작은 텍스트 인스턴스를 포함
4.2. Implementation details
[@ Mask TextSpotter v2]
- 공정한 비교를 위해 같은 학습 데이터와 Data augmentation 과정을 거침
- 한 가지 차이점
- SPN이 더 극단적인 형태의 text instance에도 강건하기 때문에 rotation 각도 범위를 에서 로 확장
[@ hyper-parameters & training details]
- optimizer: SGD with a weight decay of 0.001 and momentum of 0.9
- SynthText로 사전학습 수행 후 데이터셋을 조합하여 미세조정 수행
- SynthText: ICDAR 2013: ICDAR 2015: SCUT: Total-Text
- 학습에 사용되는 batch를 위 비율로 구성, 즉 batch를 8로 구성
- pre-training
- learning rate는 0.01로 시작
- 100K, 200K iteration에서 각각 씩 감소
- fine-tuning
- 학습 시와 동일한 환경을 사용
- initial learning rate만 0.001로 시작
- pre-training, fine-tuning 모두 250K번째의 가중치를 사용했음
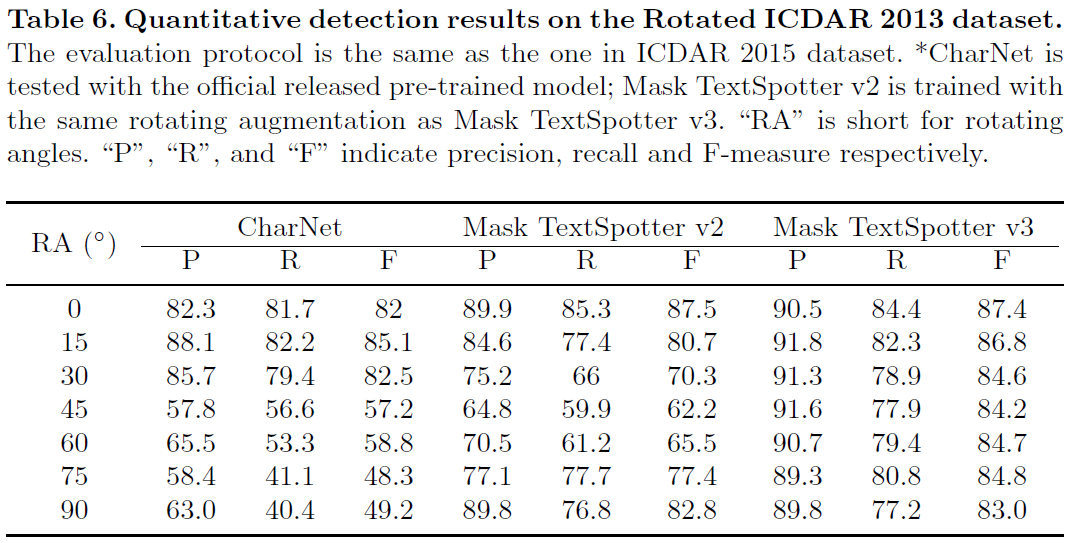
4.3. Rotation robustness
자체적으로 구축한 RoIC13에 테스트 수행
[@ Detection task]
[@ End-to-end recognition task]
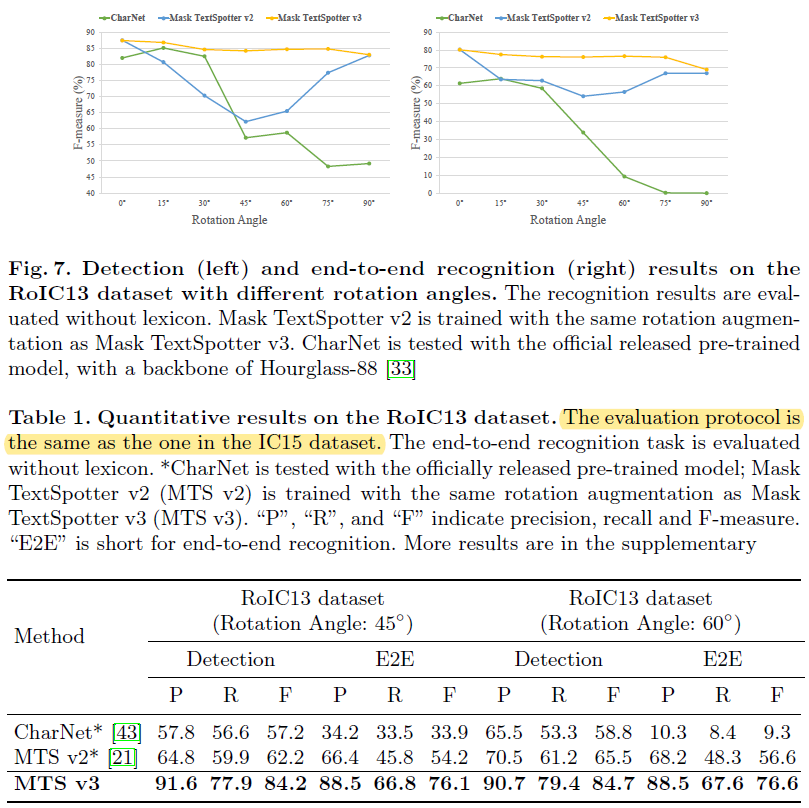
- Evaluation protocol of IC15 (출처)
- ground truth bounding box와 50% 이상 겹치고 text 내용이 일치할 경우 true positive
- 일부 작은 텍스트에 대해 "do not care"의 레이블이 되어있는 경우가 있음
- ground truth bounding box와 50% 이상 겹치는 경우, 혹은 찾아내지 못하는 경우에도 evaluation에 포함되지 않는다.
4.4. Aspect ratio robustness
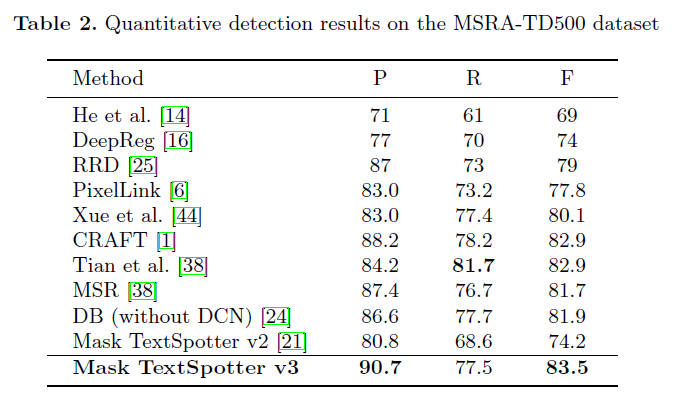
- 극단적인 종횡비의 text instance가 많이 출현하는 MSRA-TD500 데이터셋에 대해 평가 진행
- recognition annotation이 없기 때문에 detection task에 대한 평가만 수행

4.5. Shape robustness
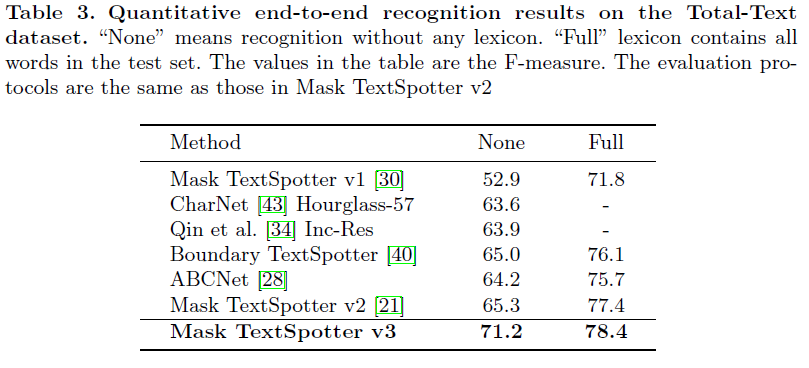
- horizontal, oriented, and curved 형태의 다양한 형태가 많이 포함된 Total-Text에 대해 평가 진행

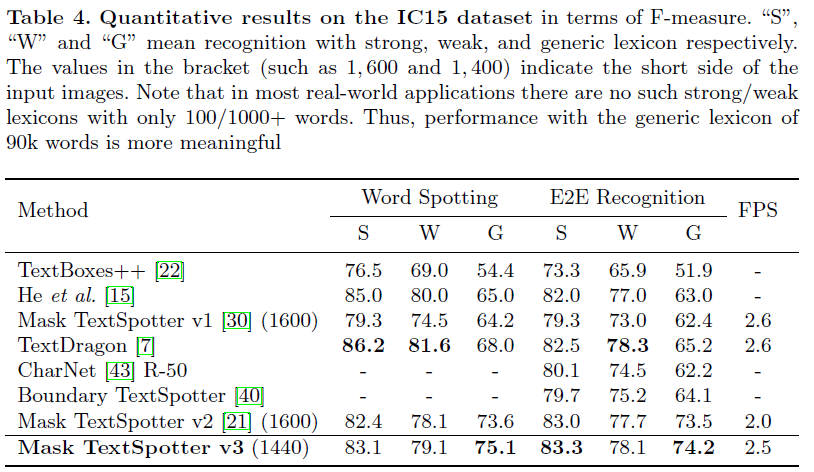
4.6. Small text instance robustness
- TextDragon이
Strong,Weaktask에서는 가장 좋은 성능을 보였지만 일반적인 경우라고 볼 수 있는Generictask에서 가장 좋은 성능을 큰 차이로 보임Strong:Weak:Generic= text word의 종류 수
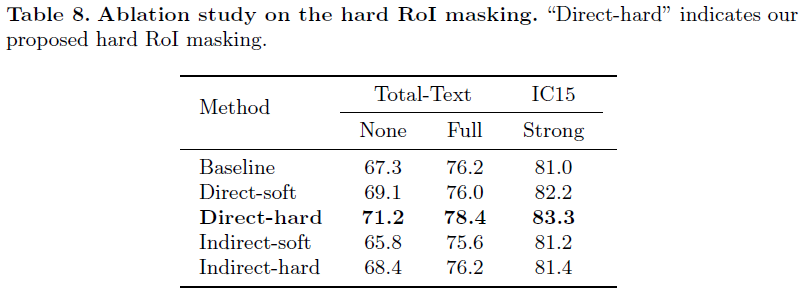
4.7. Ablation study
- options 1
- direct: segmentation/binary map을 곧바로 사용
- indirect: segmentation/binary map을 추가적인 레이어를 더해 후처리를 가하여 사용
- options 2
- soft: soft probability map(값의 범위가 )을 사용
- hard: mask map의 값이 0과 1로만 구성된 것을 사용
- 논문에서 제안하는 hard RoI masking 방법이 의미가 있음
5. Conclusion
- end-to-end 학습 모델 Mask TextSpotter v3를 제안
- SPN을 도입하여 정확한 텍스트 영역 폴리곤을 생성할 수 있음
- 다양한 데이터셋에 대한 검증 수행
- Rotated ICDAR 2013 데이터셋에 rotation robustness 검증
- MSRA-TD500 데이터셋에 aspect ratio robustness 검증
- Total-Text 데이터셋에 shape robustness 검증
- IC15 데이터셋에 작은 텍스트 인스턴스에 대한 강건함도 검증
