
시작하며
오늘은 크롤링에 대한 공부를 해보려고 한다 💪
취업 준비를 하면서 토이프로젝트도 끝냈고
이제 자바 기초 개념을 다시 공부해야겠다는 마음으로 기초를 공부하던 중에
하루종일 자바만 만지기에는 뭔가 심심하고 부족한 느낌이 들어서
지금까지 내가 프로젝트에서 써왔던 기술들과 새로운 기술들에 대한 공부도 같이 병행하며 기록해보려고 한다 : )
내가 프로젝트를 하며 사용했던 기술이지만
제대로 잘 익히지 못한 기술들을 우선적으로 공부를 해볼 생각이다 💪
이만 서론은 끝내고 크롤링에 대한 공부에 들어가보자 !
크롤링(Crawling)
크롤링이란 무엇일까 ?
크롤링( Crawling )이란 데이터를 수집하고 분류하는 것을 위미한다. 주로 인터넷상의 웹페이지를 수집해서 분류하고 저장하는 것을 뜻하며 데이터가 어디에 저장되어 있는지 위치에 대한 분류 작업이 크롤링의 주요 목적이다.
한마디로 크롤링( Crawling )은 웹 페이지를 그대로 가져와서 거기서 데이터를 추출하는 행위라고 보면 된다 !
크롤링의 원리는 ?
웹페이지는 HTML 문서로 작성되어 있으며 CSS를 참조하여 디자인 활용, 자바스크립트( JavaScript )를 참조하여 상호작용이 가능해진다.
크롤링은 HTML 태그 등을 찾아서 원하는 데이터를 추출이 가능하다.
만약 내가 원하는 정보를 크롤링 하고싶다면, 해당 웹페이지에서 F12(개발자도구)를 누른다면
해당 웹페이지의 HTML 문서가 나올 것 이다.
그리고 원하는 정보의 HTML태그를 확인하여 원하는 정보를 추출하면 된다 !
출처 : http://wiki.hash.kr/index.php/%ED%81%AC%EB%A1%A4%EB%A7%81
라이브러리
나는 자바언어를 사용하며 Eclipse를 사용하고있다.
그래서 jsoup( HTML 파싱 Java라이브러리 )를 사용한다.
jsoup을 사용하면 특정 웹 페이지에서 가져오고싶은 요소가 있을 때 HTML에서 사용하는 태그명이나 " # ", " . " 등을 사용하여 해당 요소를 선택해 객체로 받아올 수 있다.
https://jsoup.org/download 에서 라이브러리 다운로드가 가능하다.
크롤링을 해보자
라이브러리 적용
위에서 라이브러리를 다운받았다면 Eclipse에 적용시켜보자.
나는 일반 Java Project로 프로젝트를 생성하였다.
프로젝트를 생성 후 프로젝트 우클릭 -> Properties를 클릭하면 밑에 사진처럼 뜬다.
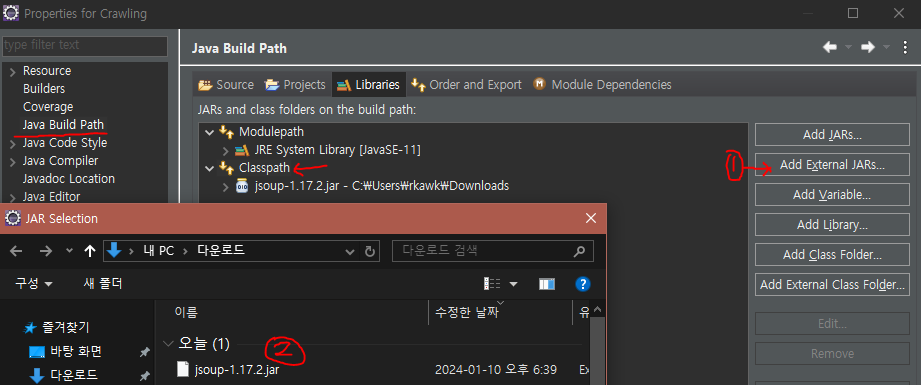
그리고 Modulepath와 Classpath가 있는데 Classpath를 누르고 Add External JARs를 눌러주면 된다.
1번 : Add External JAR Selection을 누르면 파일탐색기가 뜰 것이다.
2번 : 다운받은 jsoup라이브러리를 선택하면 위에처럼 라이브러리가 추가가 된다.
그러고 Apply 해주면 외부 라이브러리 추가 끝 !
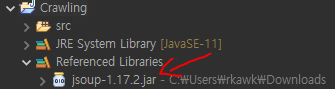
나는 처음에 Modulepath에 추가했더니 밑에처럼 라이브러리를 찾을 수 없다는 에러를 겪었다..
찾아보니 버전업이 되면서 Classpath에 추가하면 된다고 한다 !Exception in thread "main" java.lang.NoClassDefFoundError: org/jsoup/Jsoup at Crawling.main(Crawling.java:13)
그러면 이렇게 라이브러리가 적용된 것을 확인할 수 있다.
페이지 접속
나는 CGV에 무비차트에서 영화의 제목들만 추출을 해보려고 한다.
그러기 위해서는 해당 웹 페이지의 url이 필요하다 !
// "url 페이지에 접속해서 get()으로 내용을 가져오겠다" 라는 것
Document doc = Jsoup.connect("http://www.cgv.co.kr/movies/?lt=1&ft=0").get();코드 설명
- Document : Document는 웹 페이지 그 자체를 의미한다.
웹 페이지에 존재하는 HTML 요소에 접근하고자 할 때는 반드시 Document 객체부터 시작해야 한다.- Jsoup.connect(주소) : 페이지 주소의 문자열을 주소화 한다.
- get() : 주소화된 페이지의 주소를 가져온다.
출처 : https://tcpschool.com/javascript/js_dom_document
출처 : https://ddcloud.tistory.com/entry/JAVA-%EC%9B%B9-%ED%81%AC%EB%A1%A4%EB%A7%81Web-Crawling-2-jsoup%EC%9C%BC%EB%A1%9C-%ED%81%AC%EB%A1%A4%EB%A7%81%ED%95%98%EA%B8%B0
특정 태그의 내용 가져오기
여기서 제목이 적혀져있는 태그를 확인해보면 strong태그에 class 이름이 title인 것을 확인할 수 있다.
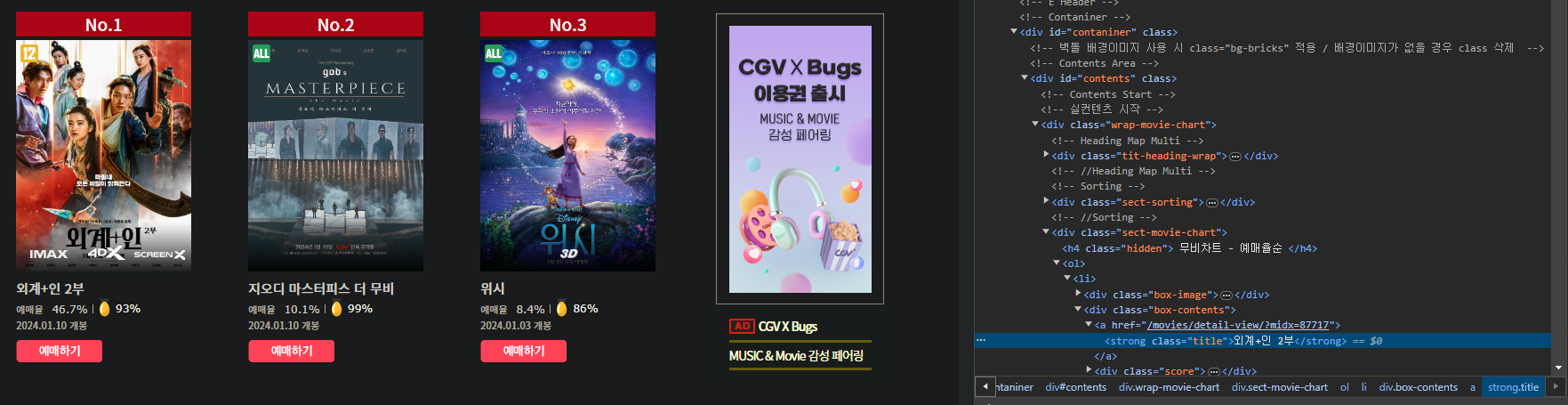
그러면 저 태그를 한번 가져와보자 !
// class="title" 을 가지고 있는 태그를 가져와서 Elements타입에 담는다.
Elements elements = doc.getElementsByAttributeValue("class", "title");
for(Element element : elements) {
System.out.println(element.text());
}코드 설명
- getElementsByAttributeValue(attribute, value) : HTML 문서 내에서 지정된 속성값을 가진 모든 요소를 선택하는 메서드이다.
attribute에는 찾고자 하는 속성의 이름
value에는 찾고자 하는 속성의 값이다.- element.text() : 만약 .text()가 없다면 태그값까지 같이 나온다 하지만 .text()가 있어서 내용값만 출력이 가능하다.
그럼 이렇게 해당 태그의 값들이 가져와지는 것을 볼 수 있다 !

.text()가 없다면?
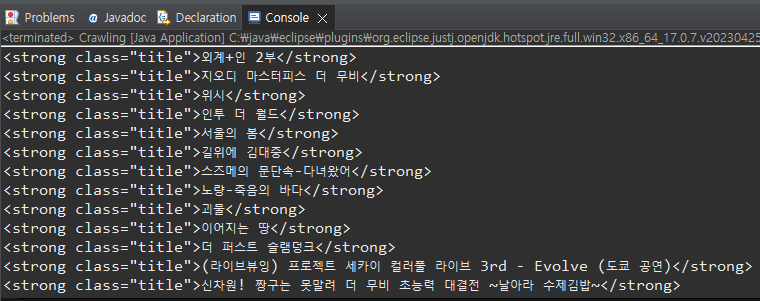
이런식으로 태그까지 출력이 된다.
전체 코드
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
// Crawling
public class Crawling {
public static void main(String[] args) throws IOException {
// "url 페이지에 접속해서 get()으로 내용을 가져오겠다 라는 것"
Document doc = Jsoup.connect("http://www.cgv.co.kr/movies/?lt=1&ft=1").get();
// class="title" 을 가지고 있는 태그를 가져와서 Elements타입에 담는다.
Elements elements = doc.getElementsByAttributeValue("class", "title");
for(Element element : elements) {
System.out.println(element.text());
}
}
}
참고 : https://www.youtube.com/watch?v=vNRMDNoQMJw&t=586s (유튜브 영상)
마치며
오늘은 크롤링의 완전 기초를 다뤄보았다.
오늘 가져온 영화제목은 전부다 가져오지 못하였다.
19순위까지만 가져와지고 그 외의 제목들은 가져와지지 않았다.
아마 감싸고있는 태그가 달라서 그런거같은데 그건 다음시간에 해결해보려고한다 ..
내일 일찍 일어나야해서 .. 😅
다음 시간에 조금 더 깊이 들어가보자 !
그럼 안녕 ~ 🖐🖐
