
시작하며
저번 공부는 cgv 영화 목록에 들어가서 영화 제목들만 크롤링을 해보았다.
오늘은 영화 하나를 들어가서 제목과 내용을 빼내보려고한다.
크롤링 - 제목, 내용 추출
이번에 크롤링을 해볼 것은 CGV 영화 목록에 있는 짱구 영화의 제목과 내용을 가져와보려고 한다 !
밑의 사진을 보면 제목은 div class="title" 태그로 감싸져 있고
줄거리 내용은 div class="sect-story-movie" 태그 안에있는 strong태그에 있는 것을 볼 수있다.
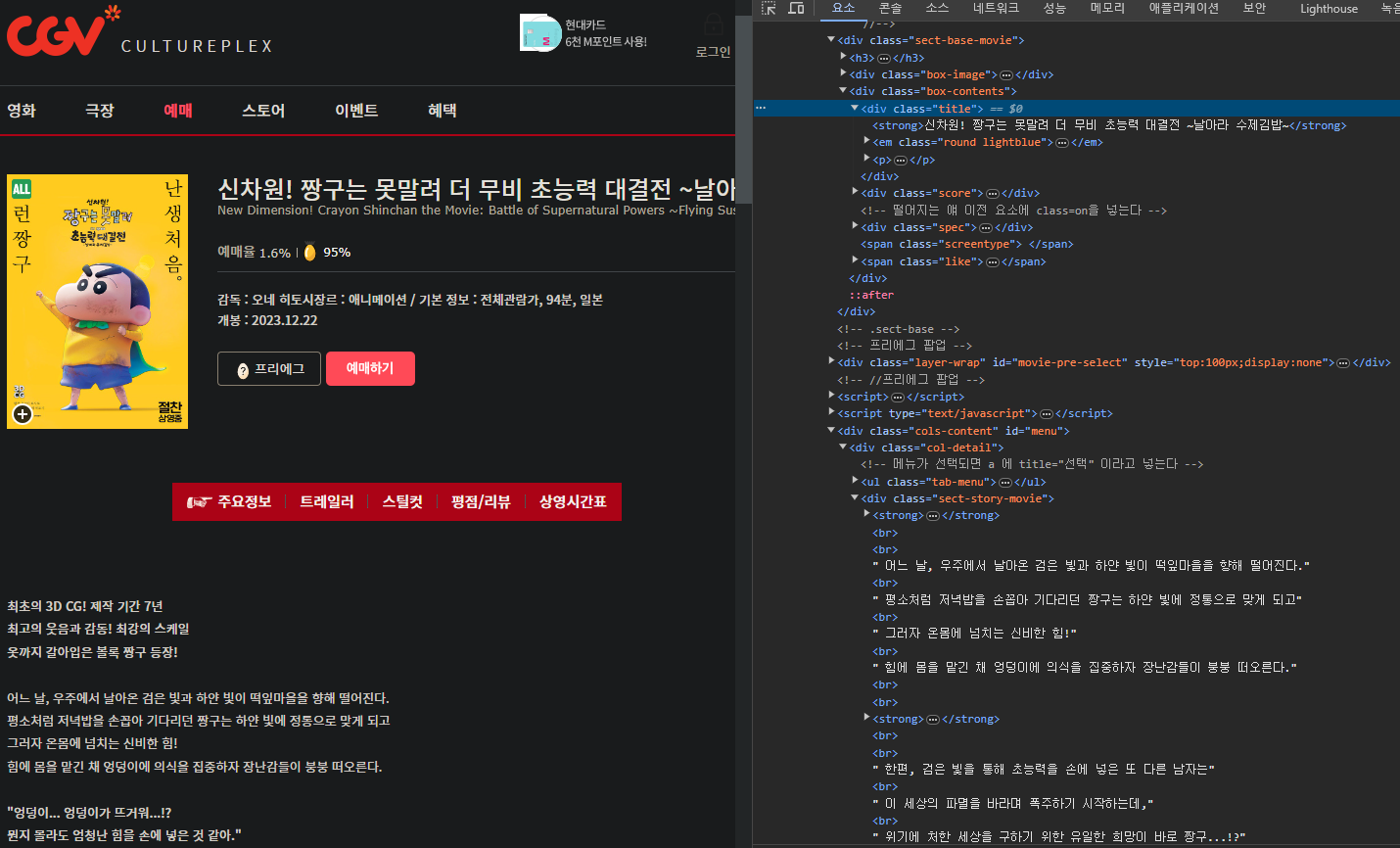
내용 가져오기 - 웹페이지 접속
저번 내용과 같이 해당 웹 페이지에 접속하여 내용을 가져왔다.
(저번 공부에서 사용한 것과 동일하여 추가 코드 설명은 하지 않겠다.)
Document doc = Jsoup.connect("http://www.cgv.co.kr/movies/detail-view/?midx=87888").get();내용 가져오기 - 해당 태그 정보 담기
여기서는 elements에는 제목을 담았고, storyElement에는 줄거리를 담았다 !
하지만 저번 시간에 사용한 메서드가 다르다.
doc.getElementsByAttributeValue 이 메서드를 사용했지만 이번에는 select 메서드를 사용하였다 ! 설명은 밑에서 하겠다.
Elements elements = doc.select("div.title");
Elements storyElement = doc.select(".sect-story-movie");코드 설명
- select("div.title") : div태그의 class="title"인 것을 가져왔다.
select(String cssQuery) 메서드는 jsoup 라이브러리에서 HTML 문서 내에서 CSS 선택자를 사용하여 원하는 엘리먼트들을 선택할 때 사용된다.
이 메서드를 사용하면 특정 조건에 맞는 엘리먼트들을 쉽게 가져올 수 있다.
꼭 CSS 선택자가 아니여도 select("div")처럼 태그명도 들어갈 수 있다.
그래서 div(태그).title(class명)해서 데이터를 가져왔다 !- select(".sect-story-movie") : class="sect-story-movie"를 가져온 것이다.
이 코드도 위와 같이 sect-story-movie의 class를 가진 태그의 데이터를 가져온 것이다.
가져온 데이터 Console에 띄워보기
이제 정보를 담았으니 해당 정보를 출력해보자 !
System.out.println("제목 : " + elements.select("strong").text());
System.out.println();
System.out.println("줄거리 : ");
System.out.println(storyElement.html().replaceAll("<br>", "\n").replaceAll("<strong>", "").replaceAll("</strong>", ""));코드 설명
- elements.select("strong").text() : elements에 저장되어있는 값에서 select("strong")으로 strong 태그의 데이터를 가져온 것이다.
.text()를 안해준다면 HTML코드도 같이 출력이 된다.- storyElement.html().replaceAll("br", "\n").replaceAll("strong", "").replaceAll("/strong", "") : 줄거리 내용을 담고있는 storyleElement를 .html()로 문자열로 만들어 주고 replaceAll() 메서드로 태그들을 공백으로 만들고 br태그는 줄바꿈으로 변환해주었다.
옆에 메서드들을 사용하지 않으면 태그와 다 같이 출력이 되어서 .text()로 해보았더니 텍스트가 한 줄로 출력이 되었다.
그래서 html까지 같이 출력 한 다음에 문자열로 바꿔주었고 br태그를 \n으로 줄바꿈을 해줘서 한줄에 다 출력 되는 것을 원래 홈페이지 처럼 줄바꿈이 되게 변환하였고, strong태그의 경우는 공백으로 처리하여 없애주었다.
(replaceAll에 있는 br, strong, /strong은 원래 태그로 "<" ">" 이렇게 감싸져 있어야 하는데 벨로그에서 어떻게 텍스트로 보이게 하는지 아직 잘 몰라서 "<" ">" 빼고 작성)
결과 이렇게 줄 바꿈이 되어서 출력이 잘 된 것을 볼 수 있다 !

전체 코드
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
// Crawling
public class Crawling {
public static void main(String[] args) throws IOException {
Document doc = Jsoup.connect("http://www.cgv.co.kr/movies/detail-view/?midx=87888").get();
Elements elements = doc.select("div.title");
Elements storyElement = doc.select(".sect-story-movie");
System.out.println("제목 : " + elements.select("strong").text());
System.out.println();
System.out.println("줄거리 : ");
System.out.println(storyElement.html().replaceAll("<br>", "\n").replaceAll("<strong>", "").replaceAll("</strong>", ""));
}
}마치며
사실 오늘도 어제와 크게 다른점은 없지만 그래도 select()메서드와 태그를 문자열로 바꿔서 원하는 대로 처리하는 방법을 알 수 있었다.
더 복잡한 문서를 크롤링 하려면 이런 방법들을 응용해서 데이터를 가져와야하는데 아직 많은 연습이 필요할거같다.. : (
크롤링 공부는 꾸준하게 계속 할거지만 이제 다른 기술들도 공부하며 정리하여 게시할 생각이다.
아마 한 기술만 지속적으로 올리기보단 여러가지 기술을 공부하는걸 랜덤적으로 올릴거같다.
더 공부해서 크롤링 시리즈도 계속 올려보고 다른 공부들도 시리즈 만들어서 올려봐야겠다 !
혹시 누군가 나의 게시물을 봐주신다면 잘못된 점 + 많은 정보들을 댓글에 남겨주시면 감사하겠습니다 !
그럼 안녕 ~ 🖐🖐
