알고리즘 문제를 풀다가 소문자, 대문자 판별, 숫자 판별 등의 기능을 구현해야할 때
필자는 아스키코드를 자주 사용한다.
어떤 방식으로 사용할 수 있는지 정리해보고자 한다.
아스키 코드 표
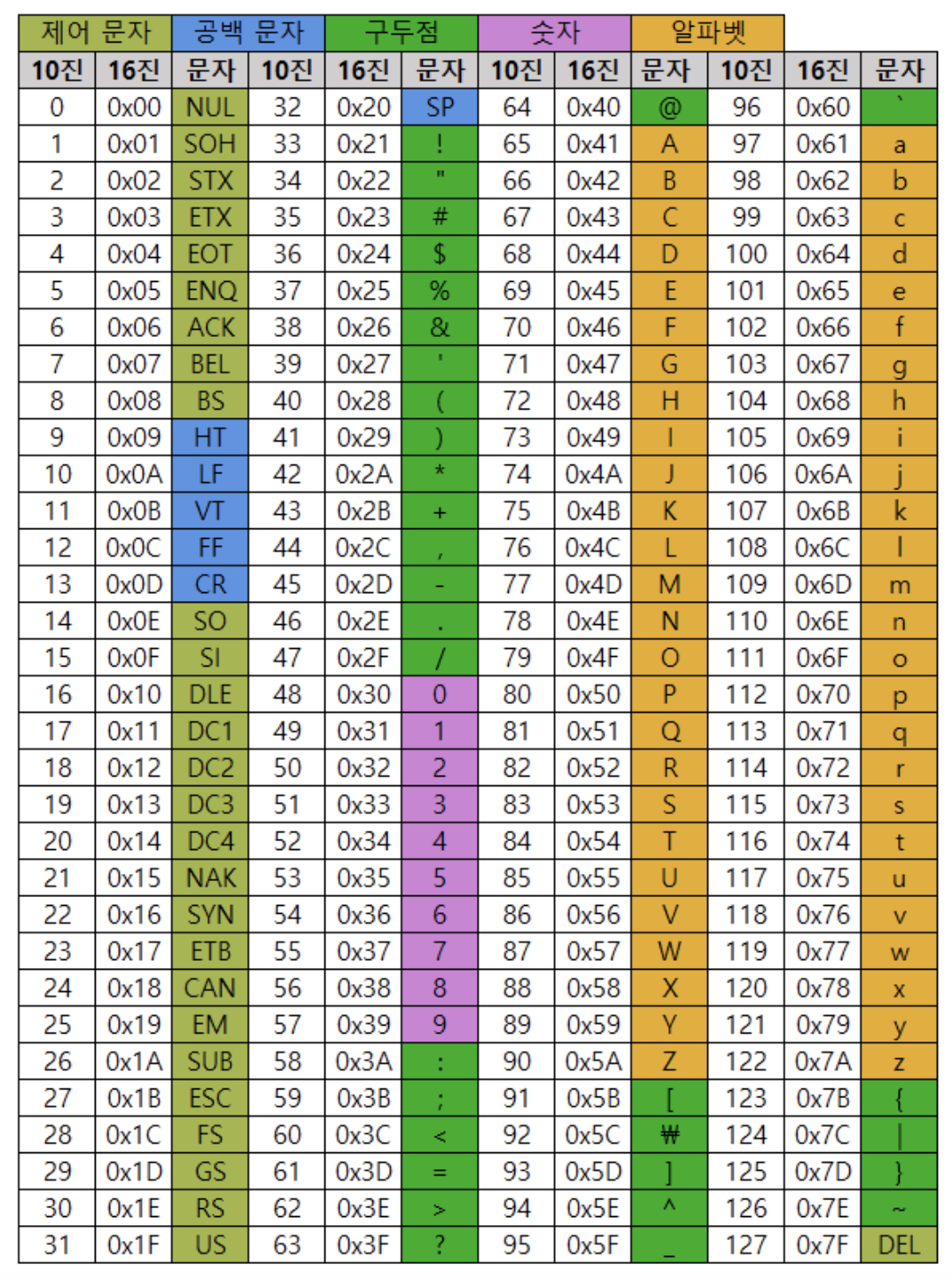
표를 읽는 법은 간단하다.
"문자"라는 항목에 있는 값들이 바로 우리가 입력값으로 넣어줄 것들이다.
"10진"이라는 항목에 있는 숫자들은 "문자"를 아스키 코드 번호로 변환한 것이다.
즉, 특정 "문자"가 아스키 코드 번호로 몇 번인지를 파악 할 수 있다.
문자 => 아스키 코드 번호
특정 입력값을 아스키 코드 번호로 변환하는 방법에 대해 알아보자.
문자.charCodeAt();방법은 위와 같다.
굳이 사용되는 변수명을 "문자"라고 적은 것은 charCodeAt()이 string 타입에만 가능하기 때문이다.
예시로 살펴보자.
"h".charCodeAt(); // 104
1.charCodeAt(); // 에러 발생!!!자, 이제 문자열에만 사용할 수 있다는 것을 알았으니, 다양한 예시들을 살펴보자.
"h".charCodeAt(); // 104
"H".charCodeAt(); // 72
"1".charCodeAt(); // 49
" ".charCodeAt(); // 32상단에 있던 표와 비교해보면 문자가 그와 매칭되는 10진수 숫자로 변환되는 것을 알 수 있다.
그렇다면 문자를 좀 길게 만들어보자.
문자열을 넣어보겠다.
"hello".charCodeAt(); // 104
"bye".charCodeAt(); // 98
"World".charCodeAt(); // 87띠용? 문자열을 입력해줬더니, 가장 앞에 있는 문자만 변환되는 것을 알 수 있다.
흠...그렇다면 두 번째 문자부터는 변환할 방법이 없는걸까?
방법이 있다!
charCodeAt()에는 인자를 넣을 수 있는데, 이 인자가 바로 문자열의 인덱스 번호를 의미한다.
예시로 살펴보자.
"hello".charCodeAt(0); // 104
"hello".charCodeAt(1); // 101
"hello".charCodeAt(4); // 111
"hello".charCodeAt(5); // NaN
"hello".charCodeAt(-1); // NaN인덱스 번호를 인자로 넣어주니, 문자열 내 해당 인덱스에 존재하는 문자가 변환되는 것이 확인된다.
물론, 문자열이 가지고 있는 인덱스 범위를 넘어가면 NaN이 반환된다.
아스키 코드 번호 => 문자
이번에는 반대로, 특정 아스키 코드 번호를 문자로 변환하는 방법에 대해 알아보자.
String.fromCharCode(숫자)방법은 위와 같다.
왜 뜬금없이 앞에 String이 붙냐고 생각하실 수 있는데, 이유는 아래와 같다.
fromCharCode()는String의 정적 메서드이기 때문에String.fromCharCode()로 사용해야 합니다.
- MDN docs -
변수명을 "숫자"라고 적은 것은 fromCharCode()의 인자로는 number 타입만 넣을 수 있기 때문이다.
여기서 잠깐! number 타입?
흠...상단 아스키 코드 표를 보면 16진수 목록이 존재한다.
그럼 16진수를 넣어도 될까?
물론이다! 16진수 표현인 0x12(예를들어)은 number 타입이므로 가능하다.
예시로 살펴보자.
String.fromCharCode(104); // "h"
String.fromCharCode(72); // "H"
String.fromCharCode(49); // "1"
String.fromCharCode(32); // " "
String.fromCharCode(0x68); // "h"
String.fromCharCode(0x48); // "H"
String.fromCharCode(0x31); // "1"
String.fromCharCode(0x20); // " "10진수 104는 16진수로 0x68이므로 같은 문자를 반환하는 것을 확인 할 수 있다.
그럼 한번에 하나의 숫자만 입력할 수 있는걸까?
아니다! 여러 개의 숫자를 나열해서 단어를 만들 수 있다.
String.fromCharCode(104, 72, 49, 32); // "hH1 "
String.fromCharCode(0x68, 0x48, 0x31, 0x20); // "hH1 "그런데 주의할 점이 있다.
초기 JavaScript 표준화 과정에서 예상했던 것처럼, 대부분의 흔한 유니코드 값을 16비트 숫자로 표현할 수 있고,
fromCharCode()가 많은 흔한 값에서 하나의 문자를 반환할 수 있지만, 모든 유효한 유니코드 값(최대 21비트)을 처리하려면fromCharCode()만으로는 부족합니다. 높은 코드 포인트의 문자는 써로게이트 값 두 개를 합쳐 하나의 문자를 표현하므로,String.fromCodePoint()(en-US)(ES2015 표준) 메서드는 그러한 쌍을 높은 값의 문자로 변환할 수 있습니다.
- MDN docs -
fromCharCode()가 모든 유니코드를 커버할 수는 없다는 것을 명심해야한다.
fromCharCode()가 허용하는 범위는 0부터 65535(0xFFFF)까지이다.
만약, 이 범위를 넘어서는 값을 입력하게 되면 아래와 같은 상황이 발생한다.
String.fromCharCode(65536); // "\x00"
String.fromCharCode(0); // "\x00"
String.fromCharCode(65536 + 104); // "h"
String.fromCharCode(104); // "h"65535 다음부터는 다시 0부터 시작하는 것과 같게된다.
언제 charCodeAt? fromCharCode?
그렇다면 언제 charCodeAt()을 사용하고, 언제 fromCharCode()를 사용할까?
필자가 알고리즘 문제를 풀면서 마주한 상황만 적어보려고 한다.
- 입력값으로 주어진 배열(혹은 문자열)이 소문자(혹은 대문자)로만 이루어졌는가?
- 이런 경우에는 문자를 아스키 코드 숫자로 변환하고, 그 숫자가 아스키 코드의 표에 명시된 범위에 속하는지를 보면된다.
- 예를들어, "h"는 104로 변환된다. 만약 소문자만 들어있는지 판별해야한다면 조건문은
변환된 숫자 >= 97 && 변환된 숫자 <= 122가 될 것이다.
이 때 104는 해당 범위 내에 속하므로 소문자라는 것을 알 수 있다. - 따라서
charCodeAt()으로 문자를 숫자로 변환한 뒤, 조건문에서 판단하면 되겠다.
- 입력값에서 소문자만 남기고 다 지워라
- 이런 문제도 1번 케이스와 완벽하게 동일하다.
charCodeAt()으로 변환하여 조건문을 통과하면fromCharCode()를 사용해서 숫자를 다시 문자로 변환하여 정답 변수에 넣어주면된다.- 물론 조건문 판단에만 사용하고,
fromCharCode()를 사용하지 않고 인덱스를 보고 문자열을 넣어주는 방법도 있다.(아마 그게 더 깔끔하다) - 다만, 여기서는 최대한 두 메소드를 써먹기 위해 이런 과정을 언급했다.
이 두 케이스를 예시로 활용하면, 숫자와 알파벳만 들어있는지 판별하는 조건문을 만들 수도 있다.
주의할 점
주의해야할 점은 내가 아스키 코드 숫자의 범위를 착각하면 써먹기가 어렵다는 것이다.
어느 범위의 숫자가 어느 문자를 가르키는지 외우지 않고서야, 바로바로 판단하기 어렵다.
그래서 아스키 코드 표를 보면서 해야한다.
필자는 이런 문제점으로 인해 요즘은 정규식을 공부하고 있다.
정규식을 활용하는 코드가 더 깔끔하기도 한 것 같다..🤔
참고 자료
frost00님 블로그
창공님 블로그
charCodeAt() - MDN docs
fromCharCode() - MDN docs
