코테를 공부하다보면, 중복 값을 제거하는 연산을 할 때가 있다.
그럴 때 보통new Set()을 사용해왔는데...그냥 중복을 제거하는 것만 알고 있었다.
그래서Set객체를 사용하는 다양한 방법을 알아보려고 한다.
Set 객체
Set 객체는 자료형에 관계 없이 원시 값과 객체 참조 모두 유일한 값을 저장할 수 있습니다.
- MDN docs -
Set 객체는 자료형에 관계 없이 유일한 값을 저장할 수 있다.
따라서, 중복되는 값은 가질 수 없다.
NaN과 undefined도 Set에 저장할 수 있습니다. 원래
NaN !== NaN이지만, Set에서 NaN은 NaN과 같은 것으로 간주됩니다.
- MDN docs -
들어가는 모든 데이터에 대하여 중복을 검사하는데,
여러 NaN에 대하여 같다고 판단하여 중복을 제거해버린다는 점을 기억하자!
또한, 인덱스를 활용하여 접근할 수가 없다는 점도 특징이다.
배열과는 다르다!
따라서, 순서가 중요시하는 데이터 형태가 아니라는 것을 알 수 있다.
사용법
생성
// 방법 1.
let set1 = new Set(); // Set(0) {}
// 방법 2.
let set2 = new Set(["hi", "bye", "hello"]); // Set(3) { 'hi', 'bye', 'hello' }
// 방법 3.
let set3 = new Set("hihello"); // Set(5) { 'h', 'i', 'e', 'l', 'o' }생성하는 방법은 너무나도 간단하다. new Set()을 사용하면 된다.
괄호 안에 값을 넣어 원소까지 만들어 버릴 수도 있다.
3번째 방법의 경우, 중복되는 문자가 있어 제거된 것을 확인 할 수 있다.
추가
let set = new Set();
set.add("A");
set.add("B");
set.add("C");
set.add("C");
console.log(set); // Set(3) { 'A', 'B', 'C' }원소를 추가하는 것은 add() 메서드를 사용한다.
이미 존재하는 원소를 추가하는 경우, 결과가 반영되지 않는 것을 확인 할 수 있다.
참고로,
let set = new Set().add("A").add("B").add("C"); // Set(3) { 'A', 'B', 'C' }이런 식으로, 생성과 추가를 한번에 할 수도 있다.
원소 존재 확인
console.log(set.has("A")); // true특정 원소가 존재하는지 확인하기 위해 has() 메서드를 사용할 수 있다.
boolean 타입의 값으로 존재 여부를 알려준다.
존재하면 true, 아니면 false.
길이 확인
console.log(set.size); // 3size를 사용해서 원소가 몇 개 들어있는지 확인 할 수 있다.
배열의 length와 같은 개념이라고 생각하면 된다.
왜 이렇게 활용할 수 있냐면...
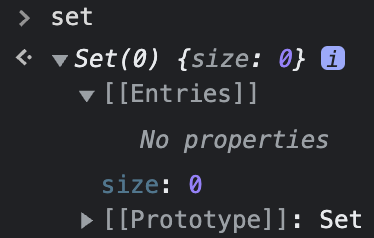
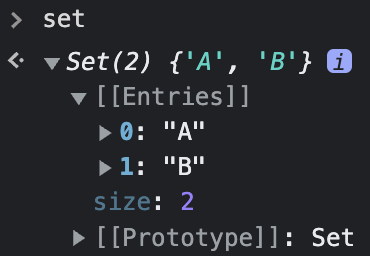
Set 객체는 위와 같은 속성들을 가지고 있기 때문이다.
size라는 key에 접근하여 값을 가져온 것이다.
제거
set.delete("C");
console.log(set); // Set(2) { 'A', 'B' }원소를 제거하는 것은 delete() 메서드를 사용한다.
전부 제거
set.clear();
console.log(set); // Set(0) {}clear() 메서드를 사용해서 모든 원소를 한번에 제거할 수도 있다.
keys() 메서드
let set = new Set(["hi", "bye", "hello"]); // Set(3) { 'hi', 'bye', 'hello' }
const setKeys = set.keys();
console.log(setKeys); // [Set Iterator] { 'hi', 'bye', 'hello' }keys() 메서드를 활용하여 Set 객체를 iterator 객체로 만들 수 있다.
이를 활용해, next() 메서드를 활용하면 원소값을 활용 할 수 있다.
console.log(setKeys.next()); // { value: 'hi', done: false }
console.log(setKeys.next().value); // 'bye'
console.log(setKeys.next().value); // 'hello'
console.log(setKeys.next().value); // undefined. 크기를 넘어갔기 때문values() 메서드
keys() 메서드와 동일한 활용이 가능하다.
const setValues = set.values();
console.log(setValues); // [Set Iterator] { 'hi', 'bye', 'hello' }
console.log(setValues.next().value); // 'hi'
console.log(setValues.next().value); // 'bye'
console.log(setValues.next().value); // 'hello'entries() 메서드
const setEntries = set.entries();
console.log(setEntries);
// [Set Entries] {
// [ 'hi', 'hi' ],
// [ 'bye', 'bye' ],
// [ 'hello', 'hello' ]
// }entries() 메서드는 [value, value] 형태로 하나의 배열로 만들어주는데,
이를 활용하여 원소 값을 사용할 수도 있다.
for (let atr of setEntries) {
console.log(atr); // [ 'hi', 'hi' ], [ 'bye', 'bye' ], [ 'hello', 'hello' ] 순서로 출력
}불필요하게 원소가 key와 value에 똑같이 들어가므로, 어디에 써먹을지는 감이 잡히지 않는다.
forEach()
set.forEach((value1, value2, setObj) => console.log(value1, value2, setObj));
// hi hi Set(3) { 'hi', 'bye', 'hello' }
// bye bye Set(3) { 'hi', 'bye', 'hello' }
// hello hello Set(3) { 'hi', 'bye', 'hello' }forEach() 메서드를 사용하여 원소에 접근 할 수도 있다.
배열의 메서드라고 생각했는데, Set 객체에서도 사용이 가능하다.
하지만, 파라미터가 의미하는 것이 약간 달라진다.
첫번째 파라미터는, 해당 순서의 value를 의미한다.
두번째 파라미터는, 해당 순서의 key를 의미한다.
그런데, Set 객체에는 별도의 key가 없으므로, 두 파라미터 모두 원소 값을 의미하게 된다.
세번째 파라미터는, Set 객체 전체를 의미한다.
활용법
지금까지는 사용법을 살펴봤다.
이제는 Set 객체를 활용하는 방법을 몇 가지 살펴볼 것이다.
스프레드 연산자
console.log(...set); // 'A B'
console.log([...set]); // [ 'A', 'B' ]스프레드 연산자를 활용하여 위와 같이 만들 수 있다.
[...set]으로 배열화하여 사용할 수 있겠다.
배열화
const setArrFrom = Array.from(set);
console.log(setArrFrom); // [ 'A', 'B' ]Array.from() 메서드를 사용해서 배열로 만들어 줄 수 있다.
스프레드 연산자의 활용법과 같은 결과를 만들어 낸다.
for of
for (let atr of set) {
console.log(atr); // 'hi', 'bye', 'hello' 순서로 출력
}for of 문법을 사용하여 Set 객체의 원소들에 접근할 수 있다.
참고로 for in 문법은 안 먹힌다. 혼동하지 말자.
이는 for in과 for of의 차이에 대해 찾아보면 좋을 것 같다.
필자가 정리한 글이 있으니 참고하실 분은 참고해주세요!
집합 연산 구현
MDN 공식 문서에서는 Set 객체를 활용한 집합 연산을 몇 가지 소개해준다.
const setA = new Set([1, 2, 3, 4])
const setB = new Set([2, 3])
const setC = new Set([3, 4, 5, 6])두 Set 객체를 각각 하나의 집합이라고 생각하고 예시를 살펴보자.
합집합
function union(setA, setB) {
const _union = new Set(setA); // setA를 새로운 Set 객체로 만든다.
for (const elem of setB) {
_union.add(elem); // setB의 원소를 새로운 Set 객체에 추가한다.
}
return _union; // 중복이 제거되므로, 중복되는 집합의 원소가 있다면 하나만 남는다.
}
console.log(union(setA, setB)); // Set(6) { 1, 2, 3, 4, 5, 6 }교집합
function intersection(setA, setB) {
const _intersection = new Set(); // 교집합을 의미하는 새로운 Set 객체를 생성한다.
for (const elem of setB) { // setB의 원소가
if (setA.has(elem)) { // setA에도 존재한다면
_intersection.add(elem); // 새로운 Set 객체에 그 원소를 추가한다.
}
}
return _intersection;
}
console.log(intersection(setA, setC)); // Set(2) { 3, 4 }대칭차
대칭차(Symmetric Difference)는 합집합에서 교집합을 뺀 것을 의미한다.
function symmetricDifference(setA, setB) {
const _difference = new Set(setA); // setA를 새로운 Set 객체로 만든다.
for (const elem of setB) { // setB의 원소가
if (_difference.has(elem)) { // 새로운 Set 객체에 존재한다면
_difference.delete(elem); // 교집합에 해당하므로, 이를 삭제한다.
} else {
_difference.add(elem); // 그렇지 않다면, 대칭차에 해당하므로 새로운 객체에 추가한다.
}
}
return _difference;
}
console.log(symmetricDifference(setA, setC)); // Set(4) { 1, 2, 5, 6 }차집합
function difference(setA, setB) {
const _difference = new Set(setA); // setA를 새로운 Set 객체로 만든다.
for (const elem of setB) { // setB의 원소를
_difference.delete(elem); // 새로운 Set 객체에서 지운다.
}
return _difference;
}
console.log(difference(setA, setC)); // Set(2) { 1, 2 }
console.log(difference(setC, setA)); // Set(2) { 5, 6 }차집합은 순서에 따라 결과가 달라지므로, 주의하자.
A - B와 B - A는 결과가 다르다.
상위 집합 판별
superset은 상위 집합, subset은 하위 집합을 뜻한다.
function isSuperset(set, subset) {
for (const elem of subset) { // 하위 집합의 원소가
if (!set.has(elem)) { // 판별 대상에 포함되어있지 않다면
return false; // 판별 대상은 하위 집합의 상위 집합이 아니므로 false를 반환한다.
}
}
return true; // 위 반복문을 통과하면 판별 대상은 하위 집합의 상위 집합이므로 true를 반환한다.
}
console.log(isSuperset(setA, setB)); // true
console.log(isSuperset(setB, setA)); // false상위 집합인지 아닌지 판별할 대상과 하위 집합으로 입력한 대상의 순서에 따라 결과가 달라진다.
setA는 setB의 상위 집합이지만,
setB는 setA의 상위 집합이 아니라 하위 집합이다.
따라서 순서를 바꿔서 연산하면 결과가 달라진다.
중복 판별
const arr = [1, 2, 3, 4, 5, 5];
function isUnique(value) {
const set = new Set(value);
if (set.size !== value.length) {
return false;
}
return true;
}
console.log(isUnique(arr)); // false중복값의 제거로 인해 Set 객체의 길이가 달라지는 것을 활용하여 중복값 여부를 판별할 수 있다.
참고 자료
