
참고한 서적 : https://hongong.hanbit.co.kr/r-%EB%8D%B0%EC%9D%B4%ED%84%B0-%EB%B6%84%EC%84%9D/ (혼자 공부하는 R언어)📌이번 주차내용
→ R언어에서 다룰 수 있는 다양한 종류의 데이터 알아보기
→ 각 데이터를 어떻게 다루는지에 대해서 알아보기🎁 데이터 분석 과정 🎁
데이터 분석 : 과거 및 현재에 일어난 상황을 활용하여 현황을 파악하고, 앞으로 다가올 상황을
예측하거나 일어날 상황에 대해 타당한 근거 자료를 제시할 수 있도록 준비하는 과정!보통의 데이터 분석과정은 크게 다음과 같은 과정을 거치게 된다.
- 데이터 분석 설계
- 데이터 준비
- 데이터 가공
- 데이터 분석
- 결론 도출
1단계 - 데이터 분석 설계
데이터 분석 설계는 데이터 분석 흐름의 가장 처음 단계로, 가장 중요한 부분이다!
간략하게 설명하자면 해당 단계는 어떤 주제를 어떻게 분석할 지 계획을 세우게 된다.
1. 분석하려는 주제를 명확하고 구체적으로 설정 & 주제 내 용어를 쉽게 정의한다.
2. 여러 회의기법을 통해(브레인 스토밍 등)주제와 연관된 내용의 가설을 다양하게 설정한다. 이 가설설정 단계에서는 가설을 많이많이 세운다음,
그 중 어떤 것이 데이터 확보가 가능한 지 판단하는 것이 좋다. 데이터 확보가 가능한지를 먼저 세우게 되면 그 부분에 너무 집중해버리기 때문에
데이터 분석을 하는데 있어서 전체적인 시각이 좁아질 수 있다는 점을 조심해야한다.
3. 가설 설정이 끝났으면 가설에 따른 분석 가능 변수를 구성한다. 분석 가능 변수를 구성할 때는 각 가설에 따라 필요한 변수를 선정해야 한다.
이 때 파생 변수도 같이 고려하면 좋다.
4. 마지막으로 분석 항목을 결정하면 1단계는 끝!2단계 - 데이터 준비하기
1단계에서는 전체적인 분석 방향을 계획해보았다.
2단계에서는 이제 분석에 필요한 데이터를 본격적으로 준비하는 단계!
필요한 데이터 항목들과 데이터가 어디에있는지에 따라 데이터를 준비하는 방법은 매우 다양하다.
데이터 준비단계는 크게 2가지 방식으로 나누어 생각해볼 수 있다.
-
필요한 데이터를 찾아 직접 입력하여 생성하기(보통 이 방법은 시간 소모가 큼)
-
기존에 누군가 구성해 둔 데이터를 찾아 활용하기(추천)
2번 방법에 대해서 약간의 설명을 가미하자면 다음과 같다.
최근에는 데이터 셋 관련 포털들이 많은데, 그 사이트들에 접속해보면 다양한 데이터 셋이 있다.
직접 사용해본 사이트 중 추천하는 사이트 몇 가지를 이곳에 남겨놓고자 한다.공공데이터 포털
Find Open Datasets and Machine Learning Projects | Kaggle
3단계 - 데이터 가공하기
데이터 가공 : 원시 데이터(아무 조작도 가하지 않은 데이터)를 원하는 형태로 가공하는 것.
- 데이터 분석에 필요없는 데이터 변수를 제거하고 필요한 부분만 추출하기
- 기존 변수의 데이터끼리 연산을 통해 조건에 맞는 새로운 데이터 구성하기
- 데이터 값에 따른 그룹화 진행하기
등의 방법이 존재한다! 이 부분은 자신이 원하는 데이터에 따라 많은 변환이 이루어질 수 있다.
4단계 - 데이터 분석하기
데이터 분석 : 데이터 가공을 거쳐 준비한 데이터를 이용하여 다양한 분석을 시행하는 것.
- 데이터 분포를 확인하기 위해 기술통계량(빈도, 평균, 최대 & 최소값, 이상치) 데이터 파악하기
- 다양한 그래프를 그려보며 패턴 및 분포 확인하기(시각화 작업)
- 사실상 데이터 분석은 데이터 준비 단계에서 함께 진행하기도 함
5단계 - 결론 도출하기
지금까지의 통계량 도출 및 작업을 통해 얻어낸 데이터를 바탕으로 의미 있는 결과를 정리한다.
여기까지 진행하고나면 데이터 분석의 전체 과정이 마무리된다😊
🎁 데이터의 생김새 🎁
✨ 시각적으로 간단한 개념 알아보기 - 행, 열, 데이터 세트, 관측치, 변수, 값 ✨
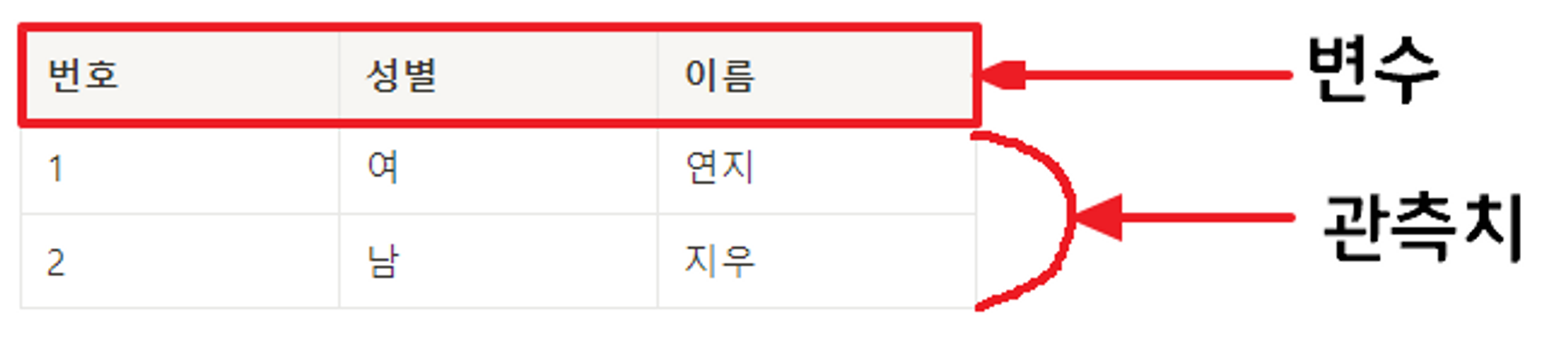
가로 한줄한줄 : 행(Row)
세로 한줄한줄 : 열(Column)
각 열에 대한 이름 : 변수(Variable)
행과 열에 들어가는 데이터 : 값(Value)✨ 데이터 구조 간 관계 및 데이터 유형 ✨
데이터 세트에는 다양한 형태의 데이터가 존재할 수 있다.
데이터는 구조와 형태에 따라 많은 이름을 가지고 있는데, 몇 개를 살펴보면 다음과 같다.
- 벡터 : 1가지 데이터 유형으로 구성된 1차원 구조의 데이터
- 행렬 : 1가지 데이터 유형으로 구성된 2차원 구조의 데이터
- 배열 : 행렬을 N차원으로 확대한 구조의 데이터
- 리스트 : 숫자 & 문자형 벡터 등 다양한 데이터 유형이 포함된 1차원 구조의 데이터
- 데이터 프레임 : 리스트를 2차원으로 확대한 구조의 데이터
데이터를 이해하기 위해서, 데이터 유형에 대해서도 알아보자.
- 숫자형 : Only 숫자로만 이루어진 데이터
- 문자형 : Only 문자로만 이루어진 데이터
- 논리형 : TRUE 혹은 FALSE로 이루어진 데이터
그렇다면, 이제 크게 데이터를 유형 및 차원에 따라 나누어 살펴보도록 하자.
데이터 유형에 따른 분류
데이터는 유형에 따라 크게 다음과 같이 나눌 수 있다.
- 단일형 : 1가지 데이터 유형으로만 구성된 데이터
- 다중형 : 여러가기 데이터 유형으로 구성된 데이터
차원에 따른 분류
차원 : 데이터 내에서 특정 데이터 값을 찾을 때 필요한 정보의 개수
- 1차원 데이터 : 직선으로 데이터가 나열되어 있는 형태
- 2차원 데이터 : 행과 열로 데이터가 나열되어 있는 형태
각 데이터를 표로 정리하여 살펴보자
| 유형(하단 기준) / 차원(우측 기준) | 1차원 | 2차원 | N차원 |
|---|---|---|---|
| 단일형 | 벡터 | 행렬 | 배열 |
| 다중형 | 리스트 | 데이터 프레임 |
벡터(Vector)
📌 벡터 📌 : 데이터 구조의 가장 기본적인 형태 & 1차원 데이터이며 1가지 데이터 유형으로 구성된다.
변수명 <- c(값) # R에서의 할당 연산자인 <- 그리고 c() 함수를 이용하여 벡터 생성벡터는 1가지 유형으로만 구성되기 때문에, 데이터 형을 다음과 같이 나눌 수 있다.
- 숫자형
- 정수형
- 문자형
- 논리형
벡터 - 숫자형 & 정수형 벡터
숫자형 벡터 : 실수 범위에 해당하는 모든 숫자를 말한다. 여기에는 정수형 벡터가 포함된다.
정수형 벡터 : 정수만으로 구성되는 벡터.
-
숫자형 벡터 생성 및 조회
# 숫자형 벡터 생성 및 조회 ex_vector1 <- c(-1, 0, 1) # ex_vector1 벡터 생성 & 아래에서 조회 ex_vector1 # 결과 : [1] -1 0 1 / [1] <- 데이터의 위치를 표현함(1번째 요소부터 표시했다는 의미) -
숫자형 벡터 속성과 길이 확인하기
아까 만든 ex_vector에 대해서 데이터 유형과 길이를 확인해보는 방법을 알아보자.
# 숫자형 벡터 속성 및 길이 확인 mode(ex_vector1) # mode() : 데이터 유형 확인 str(ex_vector1) # str() : 데이터 유형 및 값 확인 length(ex_vector1) # length() : 데이터의 길이 확인# 숫자형 벡터 속성 및 길이 확인 - 결과 > mode(ex_vector1) # 데이터 유형 확인 [1] "numeric" # numeric : 벡터가 숫자형이다! > str(ex_vector1) # 데이터 유형 및 값 확인 num [1:3] -1 0 1 # 데이터 유형이 num(숫자형)이며 + 변수에 있는 모든 데이터 출력 > length(ex_vector1) # 데이터의 길이 확인 [1] 3 # 데이터의 길이가 3임을 알 수 있다.
벡터 - 문자형 벡터
문자형 벡터 : 문자로 이루어진 데이터. 문자 데이터는 따옴표로 감싸서 작성한다.
- 문자형 벡터 생성 및 조회
# 문자형 벡터 생성 & 조회 ex_vector2 <- c("Hello", "Hi~") ex_vector2 ex_vector3 <- c("1", "2", "3") ex_vector3> # 문자형 벡터 생성 & 조회 결과 > ex_vector2 <- c("Hello", "Hi~") > ex_vector2 [1] "Hello" "Hi~" > ex_vector3 <- c("1", "2", "3") > ex_vector3 [1] "1" "2" "3" - 문자형 벡터 속성과 길이 확인하기
mode(ex_vector2) str(ex_vector2) mode(ex_vector3) str(ex_vector3)# 문자형 벡터에 mode & str을 통해 속성과 길이를 확인한 결과 > mode(ex_vector2) [1] "character" > str(ex_vector2) chr [1:2] "Hello" "Hi~" > mode(ex_vector3) [1] "character" > str(ex_vector3) chr [1:3] "1" "2" "3"
벡터 - 논리형 벡터
논리형 벡터 : TRUE 혹은 FALSE로 이루어진 데이터. 주로 데이터 값을 비교할 때 사용된다.
- 논리형 벡터 생성 및 속성 확인
# 논리형 벡터 생성 및 속성 확인 ex_vector4 <- c(TRUE, FALSE, TRUE, FALSE) ex_vector4 mode(ex_vector4) str(ex_vector4)> # 논리형 벡터 생성 및 속성 확인 결과 > ex_vector4 <- c(TRUE, FALSE, TRUE, FALSE) > ex_vector4 [1] TRUE FALSE TRUE FALSE > mode(ex_vector4) [1] "logical" > str(ex_vector4) logi [1:4] TRUE FALSE TRUE FALSE# 번외 - 만들어놓은 데이터 세트 삭제하는 법 remove(ex_vector1) rm(ex_vector1)
범주형 자료(Categorical Data)
범주형 자료 : 특수한 형태의 벡터로 이루어져 있음. 명목형 자료를 바탕으로 범주화 하였음!
명목형 자료 : 순서가 없는 자료를 의미한다.
수치형 자료 : 정수형과 실수형 자료를 의미한다.
# 이런식으로 종류를 나타내는 데이터를 범주형 자료라고 칭한다.
음식 : 빵, 밥, 국, 김치 ...
음료수 : 박카스, 바나나 우유, 몬스터 울트라 ...- 범주형 자료의 생성 - factor()
# 범주형 자료의 생성 및 조회 ex_vector5 <- c(3, 4, 5, 3, 3) ex_vector5 cate_vector5 <- factor(ex_vector5, labels = c("Apple", "Banana", "Cherry")) cate_vector5> # 범주형 자료의 생성 및 조회 결과 > ex_vector5 <- c(3, 4, 5, 3, 3) > ex_vector5 [1] 3 4 5 3 3 > cate_vector5 <- factor(ex_vector5, labels = c("Apple", "Banana", "Cherry")) # Levels = 범주 # 여기에서는 Apple = 3 / Banana = 4 / Cherry = 5로 대응된다. > cate_vector5 [1] Apple Banana Cherry Apple Apple Levels: Apple Banana Cherry
행렬 그리고 배열
행렬 : 행 + 열로 구성된 2차원 단일형 데이터
배열 : 행렬을 N차원으로 확대한 구조의 단일형 데이터
행렬(Matrix)
-
행렬 데이터 생성
# 행렬 데이터 생성 # matrix(벡터, nrow = 행 개수, ncol = 열 개수) # 2x3 3x2 행렬 생성해보기! x <- c(1, 2, 3, 4, 5, 6) matrix(x, nrow = 2, ncol = 3) # 2x3 matrix(x, nrow = 3, ncol = 2) # 3x2> # 행렬 데이터 생성 > # matrix(벡터, nrow = 행 개수, ncol = 열 개수) > # 2x3 3x2 행렬 생성해보기! > x <- c(1, 2, 3, 4, 5, 6) # [,]에서 ,를 기준으로 앞 숫자는 행 & 뒤 숫자는 열을 의미한다 > matrix(x, nrow = 2, ncol = 3) # 2x3 [,1] [,2] [,3] [1,] 1 3 5 [2,] 2 4 6 > matrix(x, nrow = 3, ncol = 2) # 3x2 [,1] [,2] [1,] 1 4 [2,] 2 5 [3,] 3 6 -
행렬 데이터 배치 순서 뒤바꾸기(byrow = T)
행렬 데이터는 행렬의 개수에 따라 위 아래로 순서대로 배치된다.
이와같은 기본 배치를 바꾸고 싶을 경우에는byrow = T옵션을 사용하면 좋다!byrow - 데이터를 왼쪽에서 오른쪽순서로 먼저 슉슉 채우겠다는 옵션 - 여기에 T 옵션을 주게되면 열부터 채워지게 된다. - 기본값은 위에서 아래순서로 먼저 슉슉 채우는 byrow = F# byrow = T 옵션을 행렬해 추가해보자! x <- c(1, 2, 3, 4, 5, 6) matrix(x, nrow = 2, ncol = 3) # 2x3 matrix(x, nrow = 2, ncol = 3, byrow = T) # 2x3 인데 왼쪽 -> 오른쪽 순서로 먼저 채움> # byrow = T 옵션을 행렬해 추가해보자! > x <- c(1, 2, 3, 4, 5, 6) > matrix(x, nrow = 2, ncol = 3) # 2x3 [,1] [,2] [,3] [1,] 1 3 5 [2,] 2 4 6 > matrix(x, nrow = 2, ncol = 3, byrow = T) # 2x3 인데 왼쪽 -> 오른쪽 순서로 먼저 채움 [,1] [,2] [,3] [1,] 1 2 3 [2,] 4 5 6
배열(Array)
- 배열 데이터 생성
# 배열 데이터 생성 # array (변수명, dim = c(행 수, 열 수, 차원 수)) # 3차원 배열 생성, 위에서 아래로 차례대로 1 -> 6 들어가서 배열 형성 y <- c(1, 2, 3, 4, 5, 6) array(y, dim = c(2, 2, 3))> # 배열 데이터 생성 > # array (변수명, dim = c(행 수, 열 수, 차원 수)) > # 3차원 배열 생성, 위에서 아래로 차례대로 1 -> 6 들어가서 배열 형성 > y <- c(1, 2, 3, 4, 5, 6) > array(y, dim = c(2, 2, 3)) , , 1 [,1] [,2] [1,] 1 3 [2,] 2 4 , , 2 [,1] [,2] [1,] 5 1 [2,] 6 2 , , 3 [,1] [,2] [1,] 3 5 [2,] 4 6
리스트와 데이터 프레임
리스트 : 1차원 데이터 벡터 or 다른 구조의 데이터를 그룹으로 묶는 데이터 세트
데이터 프레임 : 리스트를 2차원으로 확대한 것
리스트
- 리스트 변수 생성
# 리스트 생성 list1 <- list(c(1, 2, 3), "Hello") list1> # 리스트 생성 > list1 <- list(c(1, 2, 3), "Hello") # 이렇게 출력하는 이유 : 리스트에 포함된 값을 데이터형별로 구분해서 출력하기 때문 # 숫자형 벡터 / 문자형 벡터 2가지 데이터형으로 구분지어 출력한 것! > list1 [[1]] [1] 1 2 3 [[2]] [1] "Hello" - 리스트 변수 속성 확인
# 리스트에 대한 변수 속성 확인 str(list1)> # 리스트에 대한 변수 속성 확인 > str(list1) List of 2 # 2가지 변수로 구성된 리스트 라는 의미 $ : num [1:3] 1 2 3 # 1번째 : 숫자형 데이터 & 길이 3인 데이터 1, 2, 3 $ : chr "Hello" # 2번째 : 문자형 데이터
데이터 프레임
데이터 프레임 : 실제 업무에서 가장 많이 사용하는 데이터 세트. 서로 다른 형태의 데이터를 묶을 수 있는 다중형 데이터 세트이다.
행렬과 다르게 데이터 프레임의 각 열에는 변수명이 존재해야 한다는 특징이 존재한다.

행 : 데이터 세트의 가로 영역, 데이터의 관측치라고도 부른다.
열 : 데이터 세트의 세로 영역, 변수라고 부른다.
데이터값 : 데이터 프레임내에서 관측된 값이다.
- 데이터 프레임 생성 - data.frame()
# 데이터 프레임 생성 # data.frame() 함수 이용 - data.frame(변수명1, 변수명2, ... , 변수명n) ID <- c(1, 2, 3, 4, 5, 6, 7, 8, 9, 10) SEX <- c("F", "M", "F", "M", "M", "F", "F", "F", "M", "F") AGE <- c(50, 40, 28, 50, 27, 23, 56, 47, 20, 38) AREA <- c("서울", "경기", "제주", "서울", "서울", "서울", "경기", "서울", "인천", "경기") dataframe_ex <- data.frame(ID, SEX, AGE, AREA) dataframe_ex> # 데이터 프레임 생성 > # data.frame() 함수 이용 - data.frame(변수명1, 변수명2, ... , 변수명n) > ID <- c(1, 2, 3, 4, 5, 6, 7, 8, 9, 10) > SEX <- c("F", "M", "F", "M", "M", "F", "F", "F", "M", "F") > AGE <- c(50, 40, 28, 50, 27, 23, 56, 47, 20, 38) > AREA <- c("서울", "경기", "제주", "서울", "서울", "서울", "경기", "서울", "인천", "경기") > dataframe_ex <- data.frame(ID, SEX, AGE, AREA) > dataframe_ex # 관측치가 10개이고 변수가 4개인 데이터 프레임이 생성됨! ID SEX AGE AREA 1 1 F 50 서울 2 2 M 40 경기 3 3 F 28 제주 4 4 M 50 서울 5 5 M 27 서울 6 6 F 23 서울 7 7 F 56 경기 8 8 F 47 서울 9 9 M 20 인천 10 10 F 38 경기 - 데이터 프레임 변수 관찰 - str() 활용
# 주의 : 데이터프레임으로 데이터 세트를 만들 때는 각 변수에 대한 관측치 개수가 동일해야함! > str(dataframe_ex) 'data.frame': 10 obs. of 4 variables: $ ID : num 1 2 3 4 5 6 7 8 9 10 $ SEX : chr "F" "M" "F" "M" ... $ AGE : num 50 40 28 50 27 23 56 47 20 38 $ AREA: chr "서울" "경기" "제주" "서울" ...
2주차 기본 미션 : p99 확인 문제 3, 4번 풀이 및 인증
확인 문제 3번 요구사항
- 문자형으로 이루어진 데이터 1, 2, 3, 4, 5는 ID 변수
- 숫자형으로 이루어진 데이터 10, 25, 100, 75, 30은 MID_EXAM 변수
- 문자형으로 이루어진 데이터 1반, 2반, 3반, 1반, 2반은 CLASS 변수로 구성
결과
# 2주차 기본 미션 - 3번
ID <- c("1", "2", "3", "4", "5")
MID_EXAM <- c(10, 25, 100, 75, 30)
CLASS <- c("1반", "2반", "3반", "1반", "2반")> ID
[1] "1" "2" "3" "4" "5"
> MID_EXAM
[1] 10 25 100 75 30
> CLASS
[1] "1반" "2반" "3반" "1반" "2반"확인 문제 4번 요구사항
- data.frame() 함수와 3번 문항에서 사용한 변수를 사용하여 example_test 데이터 세트 저장
결과
# 2주차 기본 미션 - 4번
# 서로다른 구조의 데이터를 그룹으로 묶은 데이터 세트인 example_test 생성
example_test <- data.frame(ID, MID_EXAM, CLASS)
example_test
2주차 선택 미션 : 데이터 분석 과정 정리하기
해당 파트는 데이터 분석 과정 파트에서 정리해보았습니다😊
다시 간단하게 요약해 보자면 다음과 같은 과정을 거치게 됩니다.
- 데이터 분석 설계
- 데이터 준비
- 데이터 가공
- 데이터 분석
- 결론 도출

저도 개발자인데 같이 교류 많이 해봐요 ㅎㅎ! 서로 화이팅합시다!