저번 포스트에서는 베이시안 선형 회귀를 다루면서 기본적인 개념들도 포함하여 소개하는 시간을 가졌습니다. 이번 포스트에서는 베이시안 선형 분류가 어떻게 이루어지는지 알아보겠습니다.
Content
베이시안 분류 문제가 베이시안 회귀보다 어려운 이유는 타겟 자체가 불연속적인 성질을 띄고 있어 적분이 되지 않기 때문입니다. 따라서 Gaussian likelihood를 사용할 수 없게 되죠.
이를 해결하기 위하여 두 가지 방법이 존재하며, 각각 discriminative 방법과 generative 방법입니다.
Discriminative
discriminative 방법은 output을 activation function으로 표현하는 것입니다. 따라서 직접적으로 p(y|x)를 모델링할 수 있게 됩니다. 데이터들로부터 최적의 분류기를 구성하는 Decision theory로 해당 방법을 볼 수 있습니다.
Decision Theory
Decision Theory의 목표는 feature space를 각각의 decision region으로 나누는 최적의 분류기를 구성하는 것입니다.
joint distribution p(x, y)를 통해 데이터 x와 타겟 y의 관계를 표현하고, 이에 Loss function을 곱한 것을 적분하여 Loss 값을 구하는 방법입니다.
MLE
Class가 2개만 있는 binary 문제로 가정한 후, maximum likelihood로 분류 문제를 풀어보겠습니다.
- Logistic: /
- Likelihood: , ,
- Expectation:
- Gradient:
위에서 시그마는 sigmoid 함수를 의미합니다. class가 2개이기 때문에 activation function을 sigmoid로 설정한 것입니다. class가 여러 개일 때는 softmax function을 사용하면 되겠죠? multiclass logistic 문제를 MLE로 푸는 과정은 노트 필기로 남겨두었습니다.
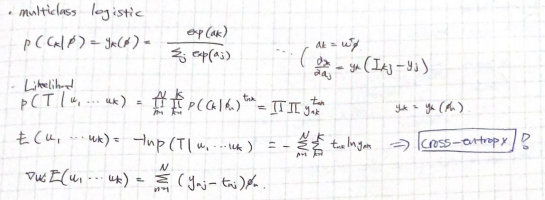
IRLS(Iteratively reweighted least squares)
IRLS는 목적 함수를 이용한 반복적인 학습을 통해서 최적화 문제를 해결하는 방법입니다. 딥러닝에서 weight update하는 방법과 매우 유사합니다.
- : Hessian matrix(=를 이계도함수로 표현한 행렬)
- : gradient of a function E(w)
Loss function을 sum of squared error로 설정하였을 때의 IRLS로 최적의 파라미터 w를 구하는 과정을 노트 필기로 남겨두었습니다.

Generative
Generative 방법은 베이즈 이론을 통해서 posterior를 간접적으로 구하는 방법입니다.
marginalize로 p(x)를 구하여 () outlier, unlabelled data 등 input 데이터들을 처리하는 것이 용이해집니다. 하지만 discriminative 방법에 비해서 분류 문제 해결에 필요한 비용이 더 많이 들게 됩니다.
Modeling
Class가 2개 이상일 때에 posterior인 generalized linear model을 구하는 과정입니다. (class가 2개일 때는 logit function과 logistic sigmoid function을 통해 posterior를 구할 수 있게 됩니다. 이번 포스트에서는 생략하겠습니다!)
class conditional density 와 class prior인 를 활용하여 posterior를 간접적으로 구할 수 있게 되며, 이때 사용된 normalized exponential 함수를 softmax 함수라고 부릅니다.
MLE
log likelihood function을 general case에 대해 나타내면 다음과 같습니다. 해당 함수를 최대화하는 파라미터를 찾으면, 선형 분류 문제를 해결할 수 있습니다.
- : prior class probabilities
- : general class conditional densities
- : one-hot encoded 타겟 벡터
Laplace Approximation
이번에는 MAP 최적화 방법으로 베이시안 선형 분류 문제를 해결해보겠습니다.
우리는 위의 과정들을 통해서 likelihood를 얻어낼 수 있습니다. 그렇다면 prior와 likelihood의 곱으로 posterior를 표현할 수 있을까요? 하지만, 여기서 문제가 하나 발생합니다. 베이시안 선형 회귀에서는 prior와 likelihood 모두 가우시안 분포로 두었기 때문에 posterior도 가우시안으로 가정하였습니다. 반면에 베이시안 선형 분류에서는 likelihood가 어떤 분포를 가진다고 특정할 수 없기 때문에 posterior가 가우시안 분포라고 둘 수 없게 됩니다.
따라서 posterior를 근사하여 구하는 방법인 Laplace Approximation을 적용하여 likelihood를 사용하지 않고 posterior에 가까운 가우시안 근사 분포를 구합니다. posterior의 mode를 찾고, 이를 중점으로 하는 가우시안 분포를 생성하는 것으로 가우시안 근사를 생성합니다.
- : 하나의 연속적인 변수, : normalization factor
가우시안 분포의 logarithm이 이차형식이라는 점을 이용하여 를 테일러 전개로 표현한 것입니다.
근사 분포 가 에 비례한다고 가정한다면 다음과 같이 표현할 수 있습니다.
- : Hessian
근사 분포 q(z)가 posterior의 역할을 하므로 해당 분포를 최대화하는 방법을 통해 모델을 학습합니다. 또한 이에 대한 predictive distribution을 구하여 새로운 입력 값에 대한 예측도 가능합니다.
Model comparison
한정된 모델 집합 내에서 특정 데이터에 대해 가장 적합한 모델을 찾는 방법으로 사용되는 BIC(Bayesian Information Criterion)에 대해서 간단히 알아보겠습니다.
BIC 수식 전개를 위해, 기본 세팅을 하겠습니다.
위의 세팅을 활용하여 model evidence를 베이즈 이론으로 구할 수 있습니다.
첫 번째 텀은 likelihood가 되며, 두 번째 텀부터는 model complexity를 표현하는 occam factor가 됩니다. 따라서 likelihood를 최대화하고 model의 복잡도를 최소화하는 방향으로 BIC를 모델 선택에 활용합니다.
Reference
[1] Bayesian Deep Learning, 최성준, https://www.edwith.org/bayesiandeeplearning/joinLectures/14426
[2] Gaussian process for machine learning, https://gaussianprocess.org/gpml/chapters/RW.pdf
[3] Pattern recognition and machine learning, https://www.microsoft.com/en-us/research/uploads/prod/2006/01/Bishop-Pattern-Recognition-and-Machine-Learning-2006.pdf
[4] Maximum likelihood estimation, Wikipeida, https://en.wikipedia.org/wiki/Maximum_likelihood_estimation
