가짜연구소 NeRF with Real-World에서 진행한 IE-NeRF 리뷰 슬라이드입니다.
- https://docs.google.com/presentation/d/1VuWYLy-Dc8BULMqMIrfqNNmPER13Xtn16pHDmcPfQNc/edit?usp=sharing
1. Introduction
IE-NeRF는 inpainting module로 uncontrolled 환경에서 NeRF를 적용하였습니다. (in-the-wild) 모델의 구조는 Ha-NeRF와 매우 유사하며 single MLP인 점과, inpainting module이 차이점입니다.
2. Related Works
NeRF를 inpainting과 결합한 2개의 논문을 간략하게 소개하겠습니다.
NeRF-object-removal

- RGB-D sequence data로부터 distractors 제거하는 NeRF입니다.
- RGB 이미지와 Depth 이미지에 LaMa inpainting을 적용하여 distractor를 제거한 후, NeRF 모델을 최적화합니다.
- 최적화 과정 중에 confidence-based view selection으로 일관되지 않은 view를 제거합니다.
SPIn-NeRF

- image inpainting으로 appearance 뿐만 아니라 geometry도 가이드합니다.
- NeRF fitting 알고리즘으로 3D inpainting을 구현하였습니다.
3. Method
NeRF
NeRF 소개는 생략하겠습니다!
Pipeline Overview

1️⃣ CNN으로 feature embedding 를 추출합니다.
2️⃣ coarse MLP의 output 와 viewing dir , feature embedding 를 fine MLP에 매핑하여, color radiance 와 static density 및 transient mask 를 얻습니다.
- transient mask는 inpainting module에 사용됩니다.
3️⃣ inpainted image와 rendered image, mask로 각 Loss에 대해 최적화합니다.
Transient Masks and Inpainting Module
MLP로 생성한 transient mask에 pre-trained inpainting model을 적용합니다. mask는 dynamic elements 정보를 포함하므로, inpainting을 통해 distractors를 제거합니다.
Mask generation
마스크 생성은 Ha-NeRF의 방법과 같습니다. 2D pixel location 와 image-specific transient embedding 를 mask MLP에 매핑하여 mask 를 생성합니다. 생성한 mask를 inpainting model LaMa에 guide로 넣어줍니다.
- Ha-NeRF에서와 다른 점은, 하나의 MLP에서 rgb, depth 뿐만 아니라 mask까지 추출한다는 점입니다.
LaMa
LaMa는 논문 작성 시점에서 single-stage inpainting SOTA이며, large mask 생성에 robust하다는 특징을 가집니다. (적은 파라미터 수와 추론 시간으로도 비교적 좋은 성능을 보입니다.) color image 에 binary mask 을 element-wise 곱해준 후, mask를 stack으로 쌓아준 tensor 이 LaMa의 input입니다.
inpainted image인 는 static rendered image에 대해 ground truth의 역할을 가집니다.
Loss Function and Optimization
Photometric loss
- : true color of ray from (inpainted image가 ground truth로 사용됩니다.)
- : 추정된 color from coarse, fine network
Inpainted image를 GT로 사용하는 부분을 제외하면, NeRF에서의 photometric loss와 동일합니다.
Transient loss
first term은 rendered image와 original image 간의 MSE로, transient 요소를 구분하는 데에 사용됩니다. second term은 rendered image와 inpainted image간의 MSE로, static 요소의 recon error를 조절하는 역할을 수행합니다.
Final loss
두 loss의 weighted sum으로 최종 loss를 얻게 됩니다.
Training with Frequency Regularization
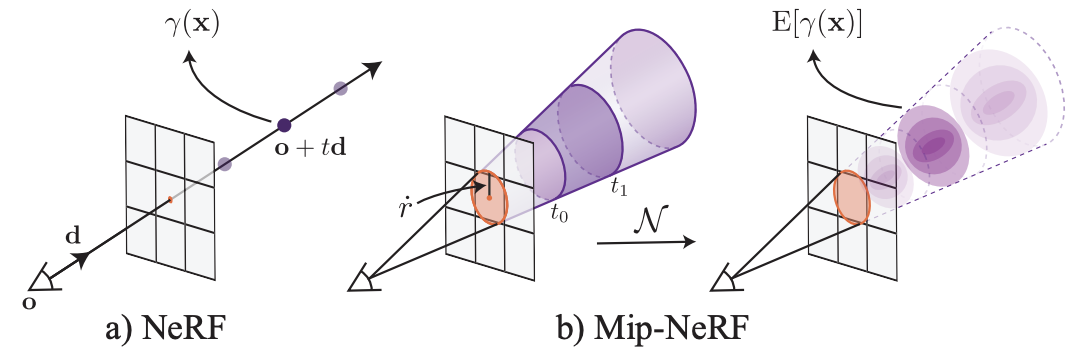
- Cone tracing & IPE: https://velog.io/@rlaalsthf02/Conical-tracing-IPE-in-Mip-NeRF
mip-NeRF에서의 cone casting을 적용하여 NeRF 모델이 multiscale 표현을 학습하도록 합니다. 이때, IPE(Integrated Positional Encoding)를 iteration에 따라 점진적으로 적용하였습니다. 초기 단계에 IPE를 강하게 적용하면, low-frequency에 대한 정보를 모델이 잃게 되는 단점이 있습니다.
4. Results
Quantitative

- Phototourism 데이터셋 평가 지표입니다.
- 기존 주요 NeRF들에 비해서는 좋은 성능을 보입니다.
- 하지만, SOTA와 비교 시 성능에서 큰 차이를 보입니다.
Qualitative

- 비교군에 비해서는 더 나은 퀄리티이지만, Sacre 데이터에 대해서 floater를 형성합니다.
Conclusions
- image inpainting을 비교적 간단하게 적용하여, in-the-wild task를 수행하였습니다.
- 성능이 뛰어나진 않지만, 하나의 연구 가능성을 보여준 논문이라고 생각됩니다. - mask 퀄리티가 높아진다면 성능이 올라갈 수 있을 것이라고 생각됩니다.
Reference
[1] IE-NeRF: Inpainting Enhanced Neural Radiance Fields in the Wild, Shuaixian Wang, Haoran Xu , https://arxiv.org/pdf/2407.10695
[2] Removing Objects From Neural Radiance Fields, Niantic, ETH Zurich, https://nianticlabs.github.io/nerf-object-removal/ (CVPR 2023)
[3] Reference-guided Controllable Inpainting of Neural Radiance Fields, Ashkan Mirzaei, Tristan Aumentado-Armstrong, https://ashmrz.github.io/reference-guided-3d/ (ICCV 2023)
