✔️ 저번 시간에 살펴본 것과 같이 lstm의 input 값이 3차원이어서 2차원으로 추출된 inception v3의 피쳐값을 넣을 수 없었다. 따라서 원래 참고하던 inception v3를 이용한 cnn-lstm 모델은 어떻게 넣었을지가 궁금해져 다시 찾아보았더니, lstm을 이용하지 않고 gru를 이용한 것을 볼 수 있었다.
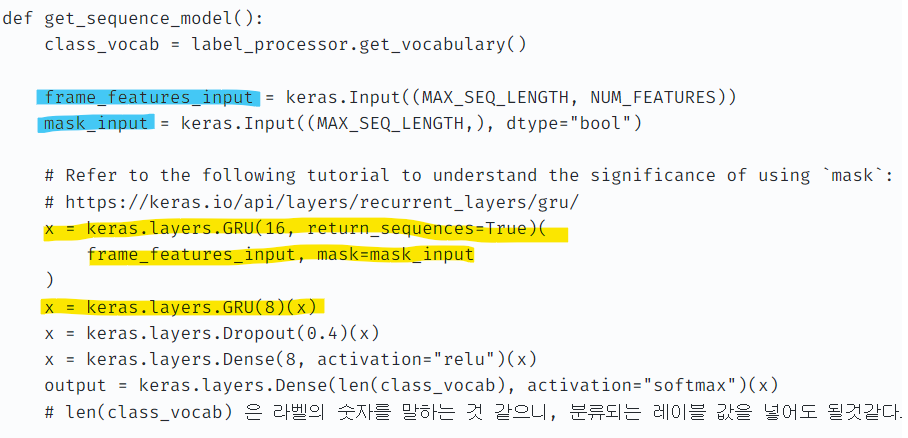

❓ 그렇다면 lstm 과 gru의 차이점은 뭘까? input이 3차원이 아닌걸까?
✔️ 3차원의 데이터는 무엇으로 이루어져 있는 걸까?
- samples
: 데이터의 크기(data size)이며, 원본 데이터를 window size에 따라 슬라이싱 할 경우 생기는 데이터의 갯수이다. - time steps
: 과거 몇개의 데이터를 볼 것인가를 나타내며, 네트워크에 사용할 시간단위 - features
: x의 차원을 의미 , x의 변수 갯수
✔️ 2차원 배열을 3차원 배열로 바꾸어 lstm에 넣는 방법을 찾아 시도해보았다.
# train_data, validation_data 2차원 배열 -> 3차원 배열
train_data=train_data.reshape(train_data.shape[0],train_data.shape[1],1)
validation_data=train_data.reshape(validation_data.shape[0],train_data.shape[1],1)- 😅 cannot reshape array of size 2883584 into shape (512,2048,1)
- train_data는 3차원 배열로 변경이 가능했지만, validation_data는 위와 같은 오류로 변경이 불가했다. 그 이유는 다음과 같다.
train_data.shape[0] == 1408
train_data.shape[1] == 2048
validation_data.shape[0] == 512
validation_data.shape[1] == 2048- 1408 x 2048 x 1 = 2883584
- 512 x 2048 x 2.75 = 32883584
❎ 2883584를 깔끔하게 나눌 수 없는 상태이므로 배열의 차원을 변경할 수 없다. 이는 데이터 셋의 개수가 떨어지지 않아 생긴 오류로 예상된다.
❎ 이는 지현님과 이전부터 우려했던 부분인데, 이번에 사용한 데이터 셋의 총 데이터 셋의 수(test, validation 따로)는 batch_size(128)로 나눴을때 딱 떨어지는 상황이 아니었다. 따라서 피쳐를 추출하는 과정에서 강제로 정수형 변환을 한 상태여서 발생한 오류이이다.
(VGG16의 경우도 마찬가지인 상황이다. 오류가 나지 않았을 뿐,,)
🔴 데이터 셋 팀원들과 상의해야할 문제이므로 해결이 된 이후에 다시 시도해볼 예정이다.

FE Programmer